racineai/OGC_Military
收藏Hugging Face2025-08-28 更新2025-04-12 收录
下载链接:
https://hf-mirror.com/datasets/racineai/OGC_Military
下载链接
链接失效反馈官方服务:
资源简介:
OGC军事视觉决策支持系统数据集,经过组织、分组和清洗,包含从在线PDF文档抓取的图像和文本数据,以及基于文档内容生成的合成查询。数据集使用Google的Gemini 2.0 Flash Lite模型来生成多样化的查询。该数据集包含训练集166,140行数据和测试集20,812行数据,语言分布以英语为主,还包括法语、阿拉伯语、德语、俄语、乌克兰语、中文、波斯语、荷兰语、西班牙语、日语、马来语、意大利语和波兰语。
The OGC Military Vision Decision Support System dataset is organized, grouped, and cleaned, containing image and text data scraped from online PDF documents, along with synthetic queries generated based on document content. The dataset uses Googles Gemini 2.0 Flash Lite model to generate diverse queries. It includes 166,140 rows of training data and 20,812 rows of test data, with a language distribution mainly in English, also including French, Arabic, German, Russian, Ukrainian, Chinese, Persian, Dutch, Spanish, Japanese, Malay, Italian, and Polish.
提供机构:
racineai
搜集汇总
数据集介绍
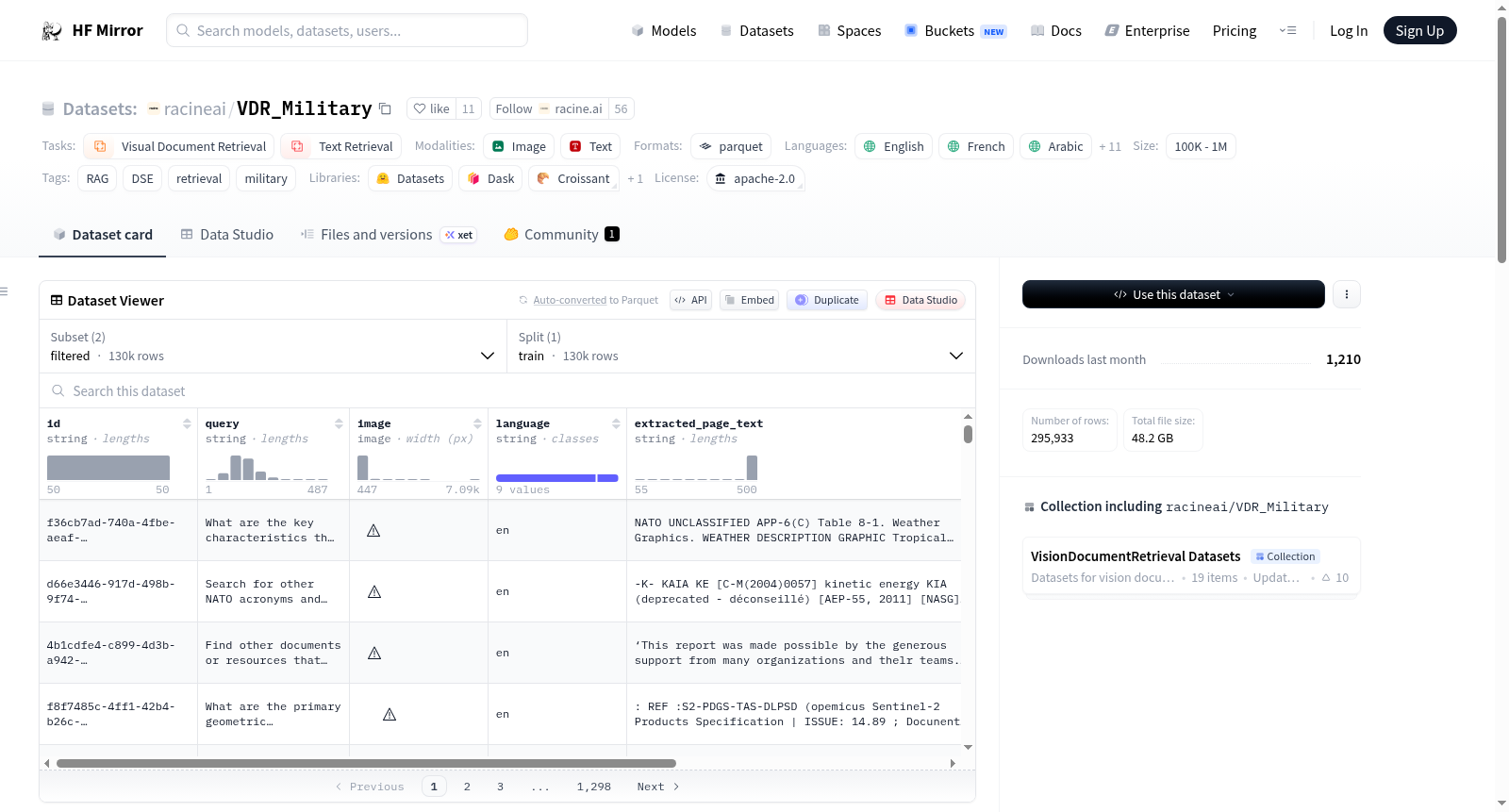
构建方式
在军事视觉文档检索领域,数据集的构建通常依赖于对多源异构信息的系统化整合。本数据集通过自动化流程从在线PDF文档中提取内容,并运用定制化流水线结合谷歌Gemini 2.0 Flash Lite模型生成合成查询,从而构建出涵盖多语言军事文档的检索对。该方法不仅实现了文档内容的向量化表示,还通过合成查询增强了数据集的多样性与覆盖面,为后续的密集检索任务奠定了坚实基础。
使用方法
针对密集语义嵌入与跨模态检索任务,本数据集可直接用于训练与评估视觉文档检索模型。用户可通过加载指定的parquet格式文件,获取图像、文本及其对应向量表示,进而实现端到端的检索流水线构建。数据集支持多语言环境下的检索实验,并可通过过滤配置灵活调整数据质量,适用于军事领域知识库构建、智能问答系统开发等实际应用场景。
背景与挑战
背景概述
在军事信息智能处理领域,高效检索与理解多模态文档是提升决策支持系统的关键。racineai/OGC_Military数据集应运而生,由RacineAI团队于近期构建,核心成员包括Paul Lemaistre、Léo Appourchaux和André-Louis Rochet。该数据集聚焦于视觉文档检索与文本检索任务,旨在通过从在线PDF文档中提取内容并生成合成查询,为图像与文本的向量化表示提供高质量训练资源。其多语言覆盖特性,尤其是英语与法语的主导分布,反映了对跨语言军事信息整合的迫切需求,为增强检索增强生成与密集检索模型在专业领域的适用性奠定了数据基础。
当前挑战
该数据集致力于应对军事领域多模态信息检索的复杂挑战,其核心问题在于如何从结构各异的PDF文档中精准提取视觉与文本信息,并构建语义关联的查询对。在构建过程中,面临多重困难:原始PDF文档的格式多样性导致内容解析与清洗难度显著;利用Gemini 2.0 Flash Lite模型生成合成查询时,需确保查询的多样性与语义准确性,避免引入模型偏差;此外,数据集中语言分布极不均衡,英语占比超过84%,而其他语言样本稀少,这为开发跨语言泛化能力强的检索模型带来了严峻考验。
常用场景
经典使用场景
在军事信息检索与视觉文档分析领域,racineai/OGC_Military数据集为研究者提供了一个多语言、结构化的基准测试平台。该数据集通过从在线PDF文档中提取内容并生成合成查询,构建了图像与文本的对应关系,典型应用于视觉文档检索(Visual Document Retrieval)和密集检索模型(Dense Retrieval)的训练与评估。其核心价值在于模拟真实军事文档的跨模态检索场景,例如根据图像内容定位相关文本描述,或基于文本查询匹配对应的视觉信息,为军事情报分析与知识管理提供了数据基础。
解决学术问题
该数据集有效应对了军事领域跨模态检索中数据稀缺与语言多样性的挑战。学术研究常面临专业领域标注数据不足、多语言对齐困难等问题,而OGC_Military通过自动化流程生成大规模、多语言的合成查询,缓解了数据标注成本高昂的瓶颈。其意义在于推动了密集检索模型在专业垂直领域的适配性研究,促进了跨语言军事信息的高效索引与检索,为安全敏感领域的知识发现技术提供了可验证的实验数据,增强了模型在复杂真实场景中的泛化能力。
实际应用
在实际应用中,该数据集支撑了军事档案数字化与智能情报系统的开发。例如,可用于构建军事文档管理系统,实现基于内容的快速图像检索与文本关联分析;在国防安全领域,辅助分析师从海量多语言报告中提取关键视觉信息,提升情报处理效率。此外,其多语言特性有助于开发跨语言军事信息检索工具,支持国际合作与多源情报融合,为指挥决策与态势感知提供技术赋能,体现了人工智能在专业化、高安全性场景中的落地潜力。
数据集最近研究
最新研究方向
在军事视觉文档检索领域,多模态信息处理正成为前沿探索的核心。racineai/OGC_Military数据集以其多语言军事文档与合成查询的结构,为密集检索模型(Dense Retrieval)与检索增强生成(RAG)系统的优化提供了关键训练资源。当前研究热点聚焦于跨语言军事术语的语义对齐,以及视觉文档中图表、地图与文本的联合向量化表示,旨在提升复杂战场环境下情报分析的自动化与精准度。该数据集的构建方法,特别是利用大语言模型生成合成查询的流程,为低资源专业领域的数据扩充提供了可借鉴的技术路径,对推动国防智能化中的信息检索与决策支持系统发展具有实质性意义。
以上内容由遇见数据集搜集并总结生成


