AMSbench
收藏arXiv2025-05-30 更新2025-11-28 收录
下载链接:
https://hf-mirror.com/datasets/wwhhyy/AMSBench
下载链接
链接失效反馈官方服务:
资源简介:
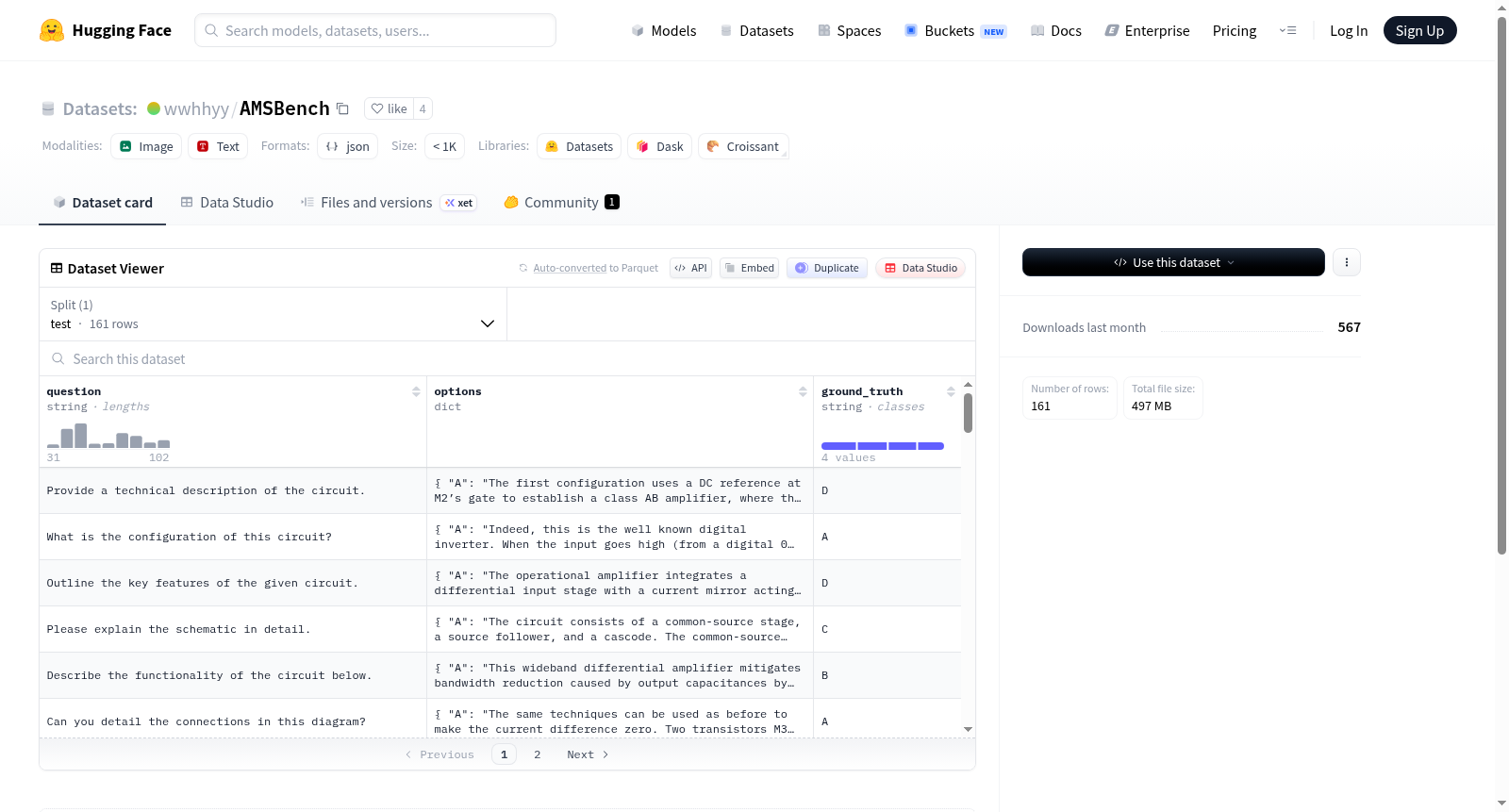
AMSbench是一个全面的数据集,旨在评估多模态大型语言模型(MLLMs)在模拟/混合信号(AMS)电路设计领域的感知、分析和设计能力。该数据集包含约8000个测试问题,跨越多个难度级别,并评估了八种主流模型。AMSbench的创建过程涉及收集来自学术界和工业界的多种数据模态,包括教科书、幻灯片、GitHub代码、电路图、表格/图表、行业报告和学术研究论文。数据集的构建旨在解决现有MLLMs在复杂多模态推理和高层次电路设计任务中的局限性,以推动自动化AMS电路设计工作流程的发展。
AMSbench is a comprehensive dataset designed to evaluate the perception, analysis, and design capabilities of multimodal large language models (MLLMs) in the analog/mixed-signal (AMS) circuit design domain. This dataset contains approximately 8,000 test questions spanning multiple difficulty levels, and has been utilized to assess eight mainstream models. The development of AMSbench involved gathering diverse data modalities from both academia and industry, including textbooks, lecture slides, GitHub code, circuit diagrams, tables, charts, industry reports, and academic research papers. The dataset is constructed to address the limitations of existing MLLMs in complex multimodal reasoning and high-level circuit design tasks, thereby promoting the development of automated AMS circuit design workflows.
提供机构:
上海交通大学, 加州大学洛杉矶分校, 清华大学, 宁波东方理工学院
创建时间:
2025-05-30
搜集汇总
数据集介绍
构建方式
在模拟与混合信号(AMS)电路领域,长久以来缺乏一个系统性的多模态评估基准。AMSbench 的构建正是为了填补这一空白,其数据来源横跨学术界与工业界,涵盖教科书、学术论文、商业数据手册及幻灯片等多种文档。研究团队利用 MinerU 工具将所有 PDF 文档高效转换为 Markdown 格式,以便提取内嵌的电路原理图等视觉元素。针对原理图到网表的转换,借助 AMSnet 技术精确恢复元件级连接与电路拓扑。为了丰富语义信息,结合领域专家的人工标注与前沿多模态大语言模型的输出,通过精心设计的提示工程与过滤策略,生成了高质量的<电路原理图,描述>配对数据。最终,依据逻辑结构与章节组织教科书内容,并从数据手册中提取结构化性能规格,人工构建了涵盖电路原理、行为与性能指标的问答数据集,形成了包含约 8000 道测试题的综合基准。
使用方法
使用 AMSbench 时,研究者可直接利用其公开的数据集进行模型评估与对比。基准提供了清晰的评测流程:对于多选问题,采用准确率(ACC)作为指标;对于多选问题,使用 F1 分数;对于网表识别任务,定义了归一化的网表编辑距离(NED)来量化预测与真实网表之间的差异。在电路设计与测试平台生成任务中,采用 pass@k 指标衡量模型生成方案的成功率,即对每个问题生成 k 个答案,计算通过仿真验证的比例,并取多次实验的平均值作为最终结果。研究者可以参照论文中给出的示例,将电路原理图与文本问题输入至待评估的多模态大语言模型,并根据相应的评分标准计算性能,从而系统性地衡量模型在 AMS 电路领域的感知、分析与设计能力。
背景与挑战
背景概述
模拟/混合信号(AMS)电路作为集成电路产业的核心基石,其设计自动化长期受困于对人工经验的深度依赖与多模态数据的固有复杂性。近年来,多模态大语言模型(MLLM)的突破性进展为AMS电路分析与设计带来了全新机遇,然而现有研究多聚焦于孤立子任务,缺乏系统性评估框架。为弥合这一空白,上海交通大学、加州大学洛杉矶分校、清华大学及东方理工高等研究院的研究团队于2025年联合推出了AMSbench基准数据集。该数据集由Yichen Shi、Ze Zhang、Hongyang Wang等学者主导构建,包含约8000道覆盖多难度等级的测试题,系统评估MLLM在电路原理图感知、电路分析与电路设计三大核心维度上的表现,旨在推动AMS电路设计全流程自动化进程。
当前挑战
AMSbench所揭示的挑战首先体现在领域问题的复杂性上:AMS电路设计依赖晶体管级描述与多模态信息(原理图、图表、文本),现有MLLM在复杂多模态推理与系统级电路设计任务中表现显著不足,例如精确解读电路原理图、理解性能指标间的权衡关系等。其次,数据集构建过程面临严苛挑战:高质量AMS电路数据的稀缺性迫使团队从教材、科研论文与商业数据手册中广泛采集,并依赖专家手动标注与先进MLLM输出相结合的方式生成语义丰富的原理图-标注对;同时,电路设计任务中测试台生成环节因预训练数据中相关知识匮乏,导致当前模型几乎无法生成语法正确的测试台,凸显了数据覆盖广度与模型泛化能力之间的鸿沟。
常用场景
经典使用场景
在集成电路设计这一精密而复杂的领域,模拟/混合信号(AMS)电路的设计自动化始终是悬而未决的难题,其高度依赖人类专家的经验与直觉。AMSbench作为首个系统性评估多模态大语言模型(MLLM)在AMS电路领域能力的综合基准,其核心使用场景在于对模型进行三维度的严苛考核:电路原理图感知、电路分析与电路设计。通过囊括约8000道涵盖从元件计数、连接判断到网表生成等感知子任务,以及功能识别、模块划分等分析任务,乃至根据规格生成电路拓扑与测试平台的设计任务,AMSbench为衡量MLLM在跨模态电路理解与生成上的真实水平提供了标尺。
解决学术问题
该数据集精准地填补了学术界在评估MLLM用于AMS电路设计时缺乏统一、全面量化标准的空白。此前的研究往往局限于孤立任务,如网表生成或错误识别,无法系统性地回答三个关键问题:模型能否精准识别电路原理图?其领域知识的上限何在?以及模型在多大程度上能助力设计自动化?AMSbench通过构建多难度、多模态的问答体系,不仅量化了当前顶尖模型在复杂多模态推理与系统级设计上的显著短板——例如在理解性能指标权衡与生成完整测试平台时几乎失效——更揭示了模型在精细感知与局部信息处理上的瓶颈,为后续研究指明了攻坚方向。
实际应用
在实际的工业界与教育场景中,AMSbench的应用价值体现在其作为“试金石”与“导航仪”的双重角色。对于EDA工具开发商,该基准可用于严格筛选和迭代具备辅助设计能力的MLLM,例如自动将手绘草图转化为可仿真的网表,或根据设计指标推荐初步的电路拓扑结构,从而缩减资深工程师在繁琐参数搜索上的时间成本。在高等教育层面,AMSbench能够作为教学辅助系统,自动评估学生对复杂电路图(如折叠共源共栅运放)的理解程度,并诊断其在功能推理或模块划分上的知识盲区,实现个性化、可量化的学习反馈。
数据集最近研究
最新研究方向
在模拟/混合信号(AMS)电路领域,多模态大语言模型(MLLMs)的自动化设计能力正成为前沿研究焦点。AMSbench作为首个系统性基准,聚焦于评估MLLMs在电路原理图感知、分析与设计三大维度的综合表现,涵盖约8000道多模态测试题。当前研究表明,尽管Gemini-2.5 Pro等模型在基础元件识别上展现出一定精度,但在复杂多模态推理与系统级电路设计任务中仍存在显著局限,尤其在完整网表提取与性能指标权衡理解方面表现薄弱。该基准的提出不仅揭示了现有模型与人类专家之间的性能鸿沟,更为推动AI驱动的AMS电路全自动化设计流程提供了关键评估框架与数据支撑,其影响力正随电子设计自动化领域对智能辅助工具需求的激增而持续扩大。
相关研究论文
- 1通过上海交通大学, 加州大学洛杉矶分校, 清华大学, 宁波东方理工学院 · 2025年
以上内容由遇见数据集搜集并总结生成


