swulling/gsm8k_chinese
收藏Hugging Face2023-11-28 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/swulling/gsm8k_chinese
下载链接
链接失效反馈官方服务:
资源简介:
---
language:
- zh
license: mit
size_categories:
- 1K<n<10K
source_datasets:
- gsm8k
task_categories:
- text2text-generation
dataset_info:
features:
- name: question
dtype: string
- name: answer
dtype: string
- name: question_zh-cn
dtype: string
- name: answer_only
dtype: int64
splits:
- name: test
num_bytes: 1020788
num_examples: 1319
- name: train
num_bytes: 5664657
num_examples: 7473
download_size: 3988161
dataset_size: 6685445
configs:
- config_name: default
data_files:
- split: test
path: data/test-*
- split: train
path: data/train-*
tags:
- math-word-problems
---
语言:
- 中文
许可证:MIT许可证
数据规模分类:
- 1000 < 样本数 < 10000
源数据集:
- GSM8K
任务类别:
- 文本到文本生成(text2text-generation)
数据集信息:
特征:
- 名称:问题(question),数据类型:字符串
- 名称:答案(answer),数据类型:字符串
- 名称:简体中文问题(question_zh-cn),数据类型:字符串
- 名称:仅答案(answer_only),数据类型:64位整数(int64)
数据集拆分:
- 拆分名称:测试集(test),字节大小:1020788,样本数量:1319
- 拆分名称:训练集(train),字节大小:5664657,样本数量:7473
下载大小:3988161 字节
数据集总大小:6685445 字节
配置项:
- 配置名称:默认配置(default),数据文件:
- 拆分:测试集(test),数据路径:data/test-*
- 拆分:训练集(train),数据路径:data/train-*
标签:
- 数学应用题(math-word-problems)
提供机构:
swulling
原始信息汇总
数据集概述
基本信息
- 语言: 中文
- 许可证: MIT
- 数据集大小: 1K<n<10K
- 源数据集: gsm8k
- 任务类别: text2text-generation
数据集结构
特征
- question: 字符串类型
- answer: 字符串类型
- question_zh-cn: 字符串类型
- answer_only: 整数类型
分割
- test:
- 字节数: 1020788
- 样本数: 1319
- train:
- 字节数: 5664657
- 样本数: 7473
下载与大小
- 下载大小: 3988161 字节
- 数据集大小: 6685445 字节
配置
- 配置名称: default
- 数据文件:
- test: data/test-*
- train: data/train-*
标签
- math-word-problems
搜集汇总
数据集介绍
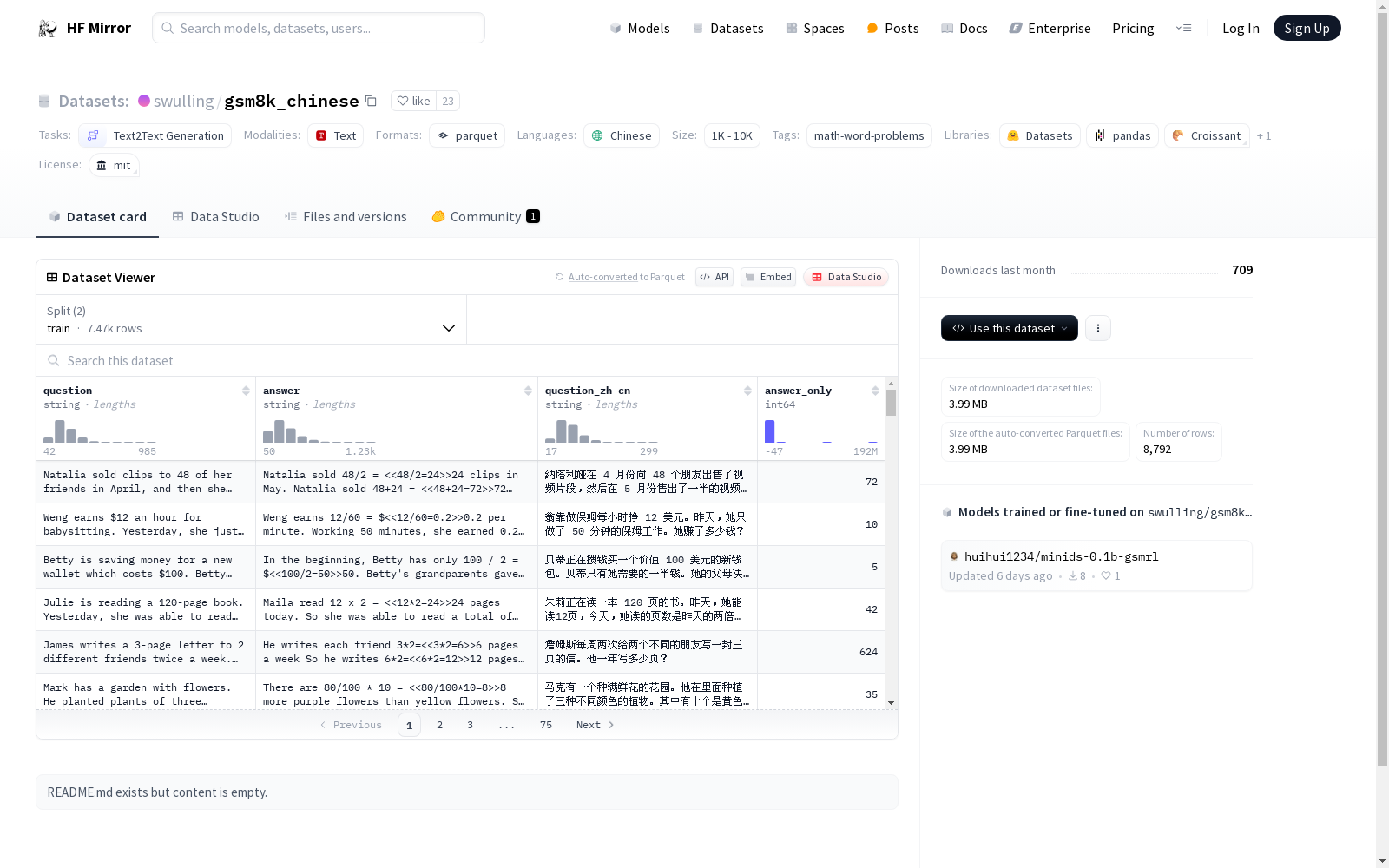
构建方式
在自然语言处理领域,尤其是数学文本处理方面,swulling/gsm8k_chinese数据集的构建采用了对原始gsm8k数据集的汉化与结构化处理。该数据集包含问题和答案对,其中问题以中文形式给出,并伴有相应的中文解答。构建过程中,数据集被划分为训练集和测试集,分别包含7473个和1319个样本,确保了数据集的可用性和模型的训练效率。
特点
swulling/gsm8k_chinese数据集的特点在于,它专注于中文数学问题的生成任务,具有明确的文本到文本生成特性。数据集采用MIT许可证,易于研究者使用和分享。此外,数据集规模适中,便于管理,同时涵盖了多种数学问题类型,为模型训练提供了丰富多样的学习材料。
使用方法
使用swulling/gsm8k_chinese数据集时,用户可根据需求下载整个数据集,其中包括训练集和测试集。数据以JSON格式存储,包含问题、答案以及额外的辅助字段。用户可以直接加载这些数据文件,用于构建数学文本生成模型,进行模型训练、验证和测试,以评估模型在中文数学问题生成任务上的性能。
背景与挑战
背景概述
在自然语言处理领域,数学问题生成与解答是检验机器理解与生成能力的重要课题。swulling/gsm8k_chinese数据集,基于国际知名的数学问题数据集gsm8k构建,由数据科学家swulling于近年贡献至HuggingFace平台。该数据集主要针对中文数学问题的生成与解答,提供了训练与测试数据,旨在推动中文自然语言处理技术在数学教育领域的应用,对提升机器的数学理解与问题解决能力具有重要意义。
当前挑战
该数据集在构建与应用过程中面临的挑战主要包括:如何确保生成的数学问题与答案的准确性及合理性;如何处理自然语言中多义性与歧义性的问题;以及在数学问题生成过程中,如何保持语言的自然流畅性。此外,数据集规模相对有限,如何在有限的样本中提取足够的特征,以支持广泛场景下的数学问题生成与解答,也是当前面临的挑战之一。
常用场景
经典使用场景
在自然语言处理领域,swulling/gsm8k_chinese数据集被广泛用于文本到文本生成的任务中。该数据集特别适用于数学单词问题的生成与解决,其提供的中文问题和答案对,为模型训练提供了丰富的语言理解和数学逻辑处理素材。
实际应用
在实践应用方面,swulling/gsm8k_chinese数据集的应用场景包括但不限于智能教育辅助、在线答疑系统以及自动化考试系统的构建。它能够帮助开发出能够理解并解决实际数学问题的智能系统,为教育和技术领域带来革新。
衍生相关工作
基于swulling/gsm8k_chinese数据集,研究者们衍生出了一系列相关工作,包括但不限于数学问题解答模型的构建、自然语言处理技术在数学教育中的应用研究,以及针对中文特定语言特征的数学文本处理方法探索,极大地推动了相关领域的学术发展和技术应用。
以上内容由遇见数据集搜集并总结生成


