统一偏好数据集
收藏arXiv2025-03-07 更新2025-03-11 收录
下载链接:
https://codegoat24.github.io/UnifiedReward/
下载链接
链接失效反馈官方服务:
资源简介:
本文构建了一个大规模的统一偏好数据集,该数据集整合了现有的多个数据集,经过预处理后,包含了图像和视频的理解与生成任务的人类偏好数据。数据集分为 pairwise ranking 和 pointwise scoring 两种类型,覆盖了236000条数据,旨在训练能够跨视觉任务进行评估的统一奖励模型 UNIFIEDREWARD。该数据集的构建是为了解决现有奖励模型任务特定、适应性差的问题,并为多模态理解和生成任务提供了一种新的评估方法。
This paper constructs a large-scale unified preference dataset. Integrating multiple existing datasets and undergoing preprocessing, this dataset contains human preference data for image and video understanding and generation tasks. It is divided into two types: pairwise ranking and pointwise scoring, with a total of 236,000 entries, aiming to train the UnifiedReward unified reward model capable of conducting evaluations across visual tasks. This dataset is developed to address the issues of task-specificity and poor adaptability of existing reward models, and to provide a novel evaluation method for multimodal understanding and generation tasks.
提供机构:
复旦大学, 上海创新研究院, 上海人工智能实验室, 上海科学院人工智能研究所
创建时间:
2025-03-07
搜集汇总
数据集介绍
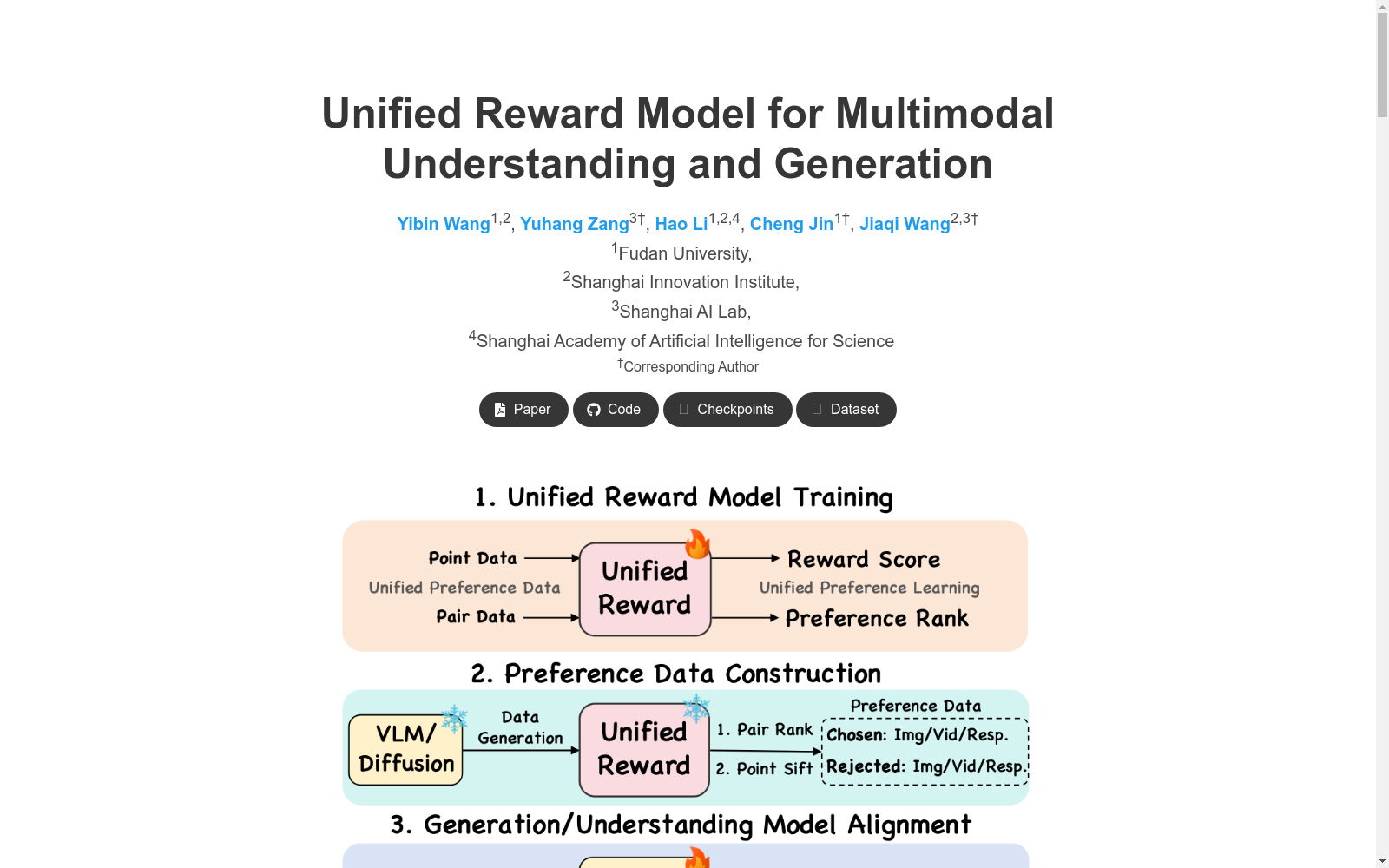
构建方式
UNIFIEDREWARD数据集的构建首先整合了现有的多个数据集,包括图像和视频的理解和生成任务,形成了约23.6万条数据的大规模统一偏好数据集。然后,基于这个数据集,研究者们对预训练的视觉语言模型进行了微调,开发了UNIFIEDREWARD模型,该模型能够进行配对排序和点评分,用于视觉模型的偏好对齐。最后,利用该模型对视觉模型的输出进行多阶段过滤,包括配对排序和点筛选,自动构建高质量的偏好配对数据。
使用方法
UNIFIEDREWARD数据集的使用方法包括三个步骤:1. 统一偏好模型训练:利用构建的数据集对预训练的视觉语言模型进行微调,开发UNIFIEDREWARD模型。2. 偏好数据构建:利用UNIFIEDREWARD模型对视觉模型的输出进行多阶段过滤,构建高质量的偏好配对数据。3. 生成/理解模型对齐:利用构建的偏好数据,通过直接偏好优化(DPO)对视觉模型进行微调,使模型输出更符合人类偏好。
背景与挑战
背景概述
在多模态生成和理解领域,人类偏好对齐是提高模型性能的关键。现有的奖励模型通常针对特定任务,限制了其在多样化视觉应用中的适应性。为了解决这个问题,王艺斌等人提出了UNIFIEDREWARD,这是第一个用于多模态理解和生成评估的统一奖励模型。该模型基于大规模人类偏好数据集进行训练,包括图像和视频生成/理解任务。UNIFIEDREWARD能够进行成对排序和点状评分,为视觉模型偏好对齐提供了一种有效的方法。该数据集和相关模型的研究对于推动多模态理解和生成技术的发展具有重要意义。
当前挑战
UNIFIEDREWARD模型面临的主要挑战包括:1) 缺乏一个涵盖广泛视觉任务的综合人类偏好数据集,限制了模型的通用性和适应性;2) 视觉任务的内在联系尚未被充分探索,共同学习多个视觉任务可能产生相互强化的效果,但目前尚未有统一模型能够有效地利用这种跨任务协同效应。
常用场景
经典使用场景
统一偏好数据集(Unified Reward Dataset)主要用于训练和评估UNIFIEDREWARD模型,该模型旨在解决多模态理解和生成任务中的偏好对齐问题。通过该数据集,UNIFIEDREWARD模型能够学习并评估图像和视频的生成和理解任务,为视觉模型提供偏好对齐的指导。数据集包含大规模的人类偏好数据,涵盖了图像和视频的生成和理解任务,支持对生成内容的质量和语义一致性进行评估。
解决学术问题
统一偏好数据集解决了现有奖励模型通常针对特定任务,缺乏跨多样视觉应用适应性的问题。此外,数据集也支持联合学习,通过同时学习多个视觉任务,创建相互强化效应,提高模型在各个领域的性能。数据集的构建和使用有助于提升视觉模型对人类偏好的理解和匹配,推动了多模态理解和生成领域的进步。
实际应用
统一偏好数据集在实际应用中可以用于优化和提升视觉模型,使其生成的内容更符合人类的偏好。例如,在图像和视频生成任务中,模型可以根据数据集提供的偏好信息,生成更高质量、更具吸引力的内容。在图像和视频理解任务中,模型可以更好地理解并解释视觉内容,提供更准确、更相关的答案。数据集的应用有助于推动视觉模型在实际场景中的表现,提升用户体验。
数据集最近研究
最新研究方向
在多模态理解和生成领域,统一偏好数据集的最新研究方向主要集中在构建能够适应多种视觉任务的统一奖励模型。该模型不仅能够进行配对排名和逐点评分,还能够自动构建高质量的偏好对数据,并通过直接偏好优化(DPO)实现模型偏好对齐。研究表明,联合学习多种视觉任务可以带来显著的相互效益,从而显著提高每个领域的性能。这一研究方向对于提高视觉模型的质量和对齐具有重大意义,为未来的研究提供了新的思路和方向。
相关研究论文
- 1Unified Reward Model for Multimodal Understanding and Generation复旦大学, 上海创新研究院, 上海人工智能实验室, 上海科学院人工智能研究所 · 2025年
以上内容由遇见数据集搜集并总结生成


