NoCaptain/Reddit_Twitter_C19_Jan2020_Feb2022
收藏Hugging Face2022-07-07 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/NoCaptain/Reddit_Twitter_C19_Jan2020_Feb2022
下载链接
链接失效反馈官方服务:
资源简介:
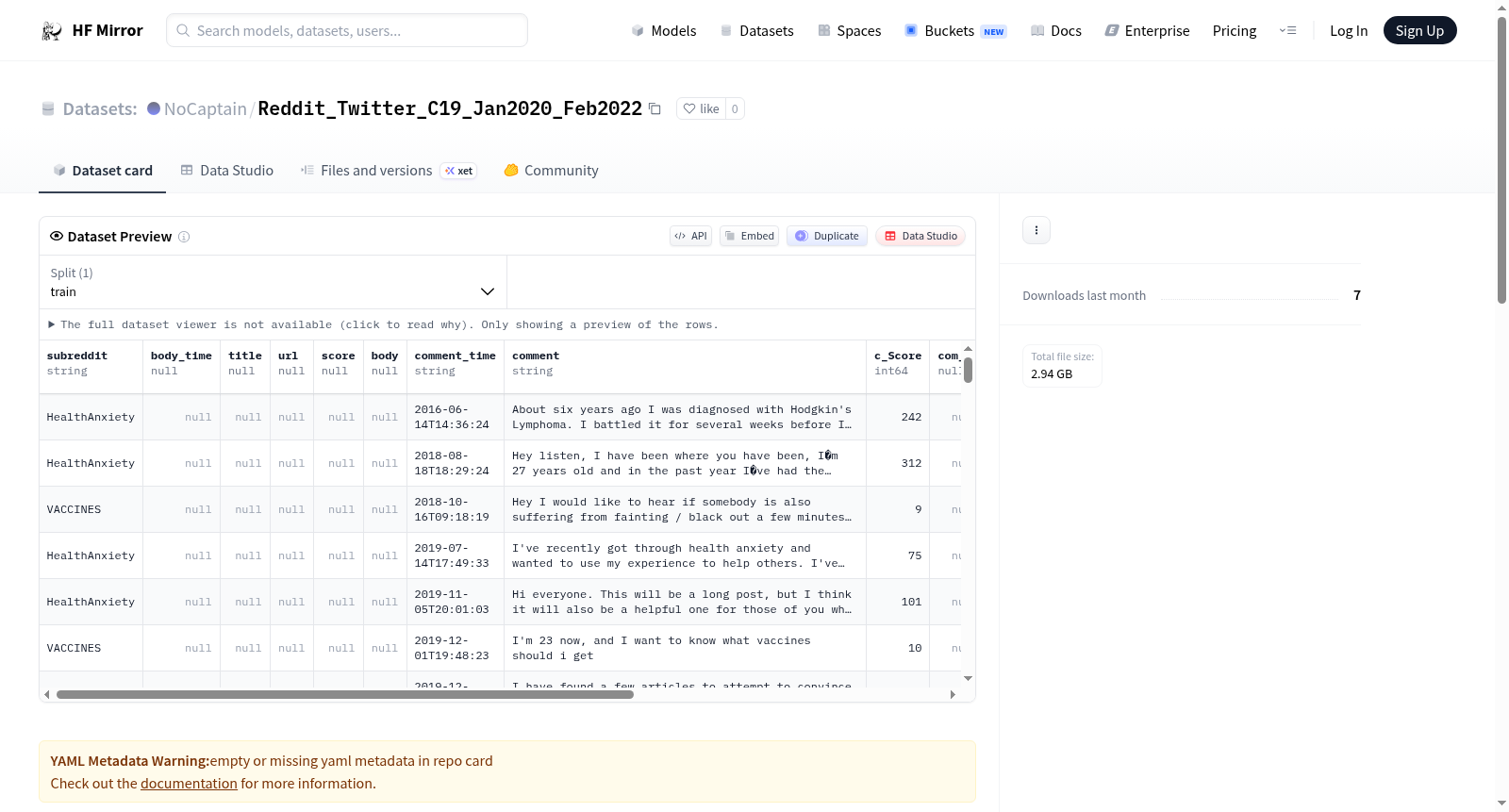
该数据集包含了从2020年1月1日至2022年3月1日期间,从Reddit和Twitter两个社交媒体平台上收集的关于COVID-19疫苗的讨论内容。研究特别关注了普通用户的讨论,排除了来自新闻机构或机器人的帖子,以确保数据的真实性和代表性。Twitter数据集最终包含了9,518,270条推文,由3,006,075位用户发布;Reddit数据集则包含了来自13个子论坛的1,401个帖子和10,240条评论,共计11,641条内容,由至少8,281位用户发布。
This dataset contains discussions about COVID-19 vaccines collected from two social media platforms, Reddit and Twitter, spanning from January 1, 2020 to March 1, 2022. The study specifically focuses on discussions from regular users, excluding posts from news organizations or bots to ensure the authenticity and representativeness of the data. The Twitter dataset ultimately includes 9,518,270 tweets posted by 3,006,075 users; the Reddit dataset contains 1,401 posts and 10,240 comments from 13 subreddits, totaling 11,641 pieces of content published by at least 8,281 users.
提供机构:
NoCaptain
原始信息汇总
数据集概述
数据来源与时间范围
- 来源平台:Reddit 和 Twitter
- 时间范围:2020年1月1日至2022年3月1日
数据收集目的
- 比较两个社交平台上的COVID-19疫苗相关讨论,特别是普通用户的态度和内容。
数据处理
-
Twitter数据:
- 原始数据量:约1300万条推文
- 最终数据量:9,518,270条推文,由3,006,075名用户发布
- 数据清洗:移除了疑似机器人、新闻媒体、高频重复用户及重复推文
- 用户限制:仅包括在研究期间发布不超过200次的用户
- 数据特征:包含约1632万次点赞,平均每条推文14.9次点赞
-
Reddit数据:
- 数据集版本:分为R1, R1.2, 和 R2三个阶段
- R1数据集:从13个subreddits中收集了约18,000条帖子
- 最终数据集:1401条帖子和10,240条评论,总计11,641条记录
- 用户数量:至少8281名用户,其中1048名用户发布多次
- 数据清洗:结合各subreddit数据,按日期组织,并针对特定COVID-19疫苗相关词汇进行查询
数据集特点
- 用户行为:Reddit用户可以对帖子进行“顶”或“踩”,Twitter用户可以点赞。
- 数据收集方法:使用snscrape和Tweepy API Python库收集Twitter数据,使用Reddit API收集Reddit数据。
- 数据集限制:Twitter数据未收集转发数据,Reddit数据可能因社区规则和内容监控存在偏见。
搜集汇总
数据集介绍
构建方式
在社交媒体分析领域,NoCaptain/Reddit_Twitter_C19_Jan2020_Feb2022数据集的构建体现了严谨的实证研究设计。该数据集聚焦于2020年1月至2022年3月期间Reddit和Twitter两大平台关于COVID-19疫苗的讨论内容,通过API接口采集原始数据。构建过程中,研究团队采用多重过滤机制以排除新闻机构账号和机器人账户的干扰,依据用户发帖频率设定阈值,仅保留发帖量不超过200次的普通用户数据。同时,通过关键词查询确保内容相关性,并对Reddit数据进行了多阶段采集与清洗,最终形成涵盖近千万条推文和万余条Reddit帖文的标准化语料库。
特点
该数据集的核心特征在于其跨平台比较的设计理念与高质量的数据清洗流程。数据集同时囊括了以短文本为主的Twitter和以社区讨论为核心的Reddit数据,时间跨度覆盖疫情初期至疫苗广泛接种阶段,完整呈现了公众舆论的演变轨迹。数据经过严格去重和去噪处理,有效剥离了机器生成内容与机构媒体声音,专注于普通用户的真实表达。此外,Reddit部分特别选取了政治立场与疫苗态度多元化的子社区,增强了样本的代表性,而Twitter数据则保留了点赞数等互动指标,为多维度的情感与传播分析提供了基础。
使用方法
该数据集适用于计算社会科学、信息传播学及公共卫生领域的多类研究课题。研究者可借助自然语言处理技术,对文本进行情感分析、主题建模或立场检测,以探究不同平台用户对疫苗议题的态度差异与演变规律。在进行跨平台比较时,需注意Twitter与Reddit在内容形式、互动机制及社区规范上的固有差异,并据此调整分析方法。数据集中的时间戳与互动数据支持时间序列分析与影响力评估。使用前建议仔细阅读元数据说明,并依据研究目的对数据进行适当的子集划分或加权处理。
背景与挑战
背景概述
在社交媒体分析领域,追踪公共卫生事件中的公众情绪演变已成为关键研究方向。NoCaptain/Reddit_Twitter_C19_Jan2020_Feb2022数据集由研究团队于2020年至2022年间构建,聚焦COVID-19疫苗话题在Reddit和Twitter两大平台的讨论动态。该数据集通过对比两种社交媒体生态系统的用户生成内容,旨在揭示全球疫情背景下公众舆论的时空演化规律,尤其关注普通用户的真实态度表达,为计算社会科学与健康信息学研究提供了珍贵的纵向观测样本。
当前挑战
该数据集面临的核心挑战在于如何精准捕捉非机构化用户群体的真实意见。在领域问题层面,社交媒体疫苗情绪分析需克服算法偏见、跨平台语义差异以及噪声信息干扰等难题;在构建过程中,研究团队需设计复杂的数据清洗流程以剔除新闻机构账号与机器人账户,同时通过频率阈值设定与人工核查相结合的方式,确保数据集的代表性与纯净度。此外,Reddit社区的内容审核机制与Twitter数据采集接口的差异性,进一步增加了跨平台对比研究的复杂性。
常用场景
经典使用场景
在公共卫生信息学领域,社交媒体数据已成为洞察公众情绪动态的关键资源。NoCaptain/Reddit_Twitter_C19_Jan2020_Feb2022数据集通过整合Reddit和Twitter两大平台在2020年1月至2022年3月期间关于COVID-19疫苗的讨论内容,为研究者提供了一个跨平台、时序性的语料库。该数据集最经典的使用场景在于支持疫苗舆论的纵向比较分析,使学者能够追踪疫情不同阶段公众态度的演变轨迹,尤其聚焦于普通用户的真实发声,避免了新闻机构或机器人账户的干扰,从而确保了情感计算的社会生态效度。
衍生相关工作
基于该数据集的衍生研究已拓展至多个交叉领域。经典工作包括利用其时序特征开发疫苗情绪预测模型,结合自然语言处理技术识别反疫苗话语的传播模式。部分研究进一步融合网络分析,揭示意见领袖在跨平台讨论中的角色差异;另有学者将其与疫苗接种率数据进行关联分析,验证线上情绪与线下行为的映射关系。这些工作深化了危机传播理论,并为社交媒体治理提供了实证基础。
数据集最近研究
最新研究方向
在公共卫生信息学领域,社交媒体数据已成为监测公众健康态度与行为演变的关键资源。NoCaptain/Reddit_Twitter_C19_Jan2020_Feb2022数据集聚焦于新冠疫情初期至疫苗推广期间两大平台用户对疫苗话题的讨论,其前沿研究主要围绕跨平台情感动态比较与虚假信息传播机制展开。学者们借助该数据集深入剖析普通用户与自动化账户在疫苗叙事中的差异,探索社会网络结构如何影响健康信念的形成与扩散。相关热点事件如疫苗批准时间节点与政策调整期的舆论波动,为理解群体情绪变迁提供了实证基础。该数据集通过严格清洗非典型用户内容,确保了分析结果的代表性,对公共卫生沟通策略的优化及危机应对模型的构建具有重要参考价值。
以上内容由遇见数据集搜集并总结生成


