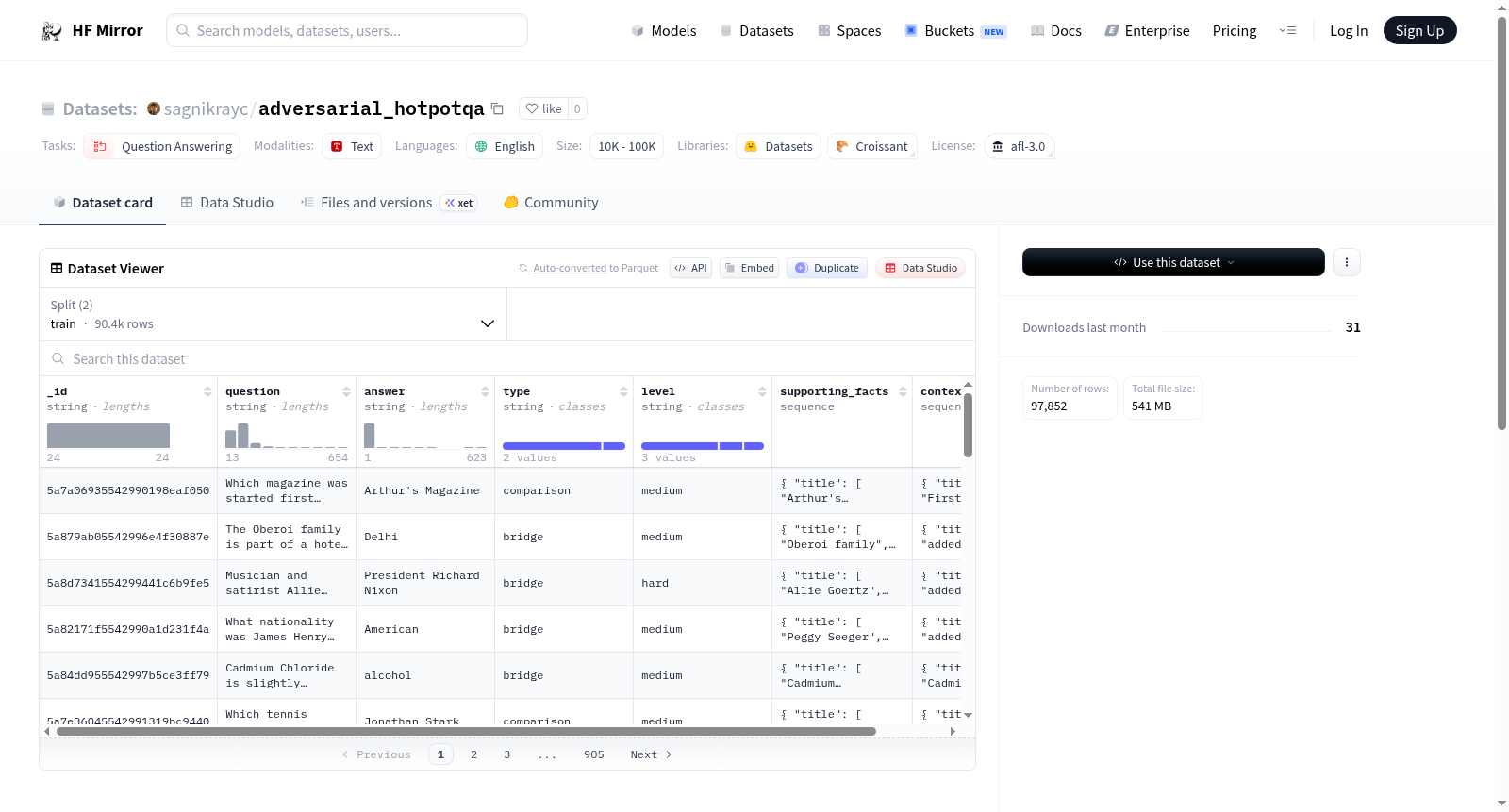
sagnikrayc/adversarial_hotpotqa
收藏Hugging Face2023-08-21 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/sagnikrayc/adversarial_hotpotqa
下载链接
链接失效反馈官方服务:
资源简介:
该数据集来源于论文《Avoiding Reasoning Shortcuts: Adversarial Evaluation, Training, and Model Development for Multi-Hop QA》,由Yichen Jiang和Mohit Bansal撰写。数据集通过原始Github仓库中的代码创建。论文探讨了多跳问答中的推理捷径问题,并通过构建对抗性文档来测试模型的鲁棒性。研究结果表明,基线模型在对抗性测试中表现显著下降,表明它们确实利用了推理捷径而非进行多跳推理。通过对抗性训练,基线模型的性能有所提升,但在对抗性测试中仍有限制。研究还提出了一种动态关注问题的控制单元,以指导模型的多跳推理,并展示了该模型在对抗性数据上的鲁棒性。
This dataset is derived from the paper *Avoiding Reasoning Shortcuts: Adversarial Evaluation, Training, and Model Development for Multi-Hop QA*, authored by Yichen Jiang and Mohit Bansal, and was constructed using the code from its original GitHub repository. The paper explores the issue of reasoning shortcuts in multi-hop question answering (QA), and develops adversarial documents to test model robustness. Research results show that baseline models experience significant performance degradation in adversarial tests, indicating that they indeed exploit reasoning shortcuts rather than performing genuine multi-hop reasoning. Although adversarial training improves the performance of baseline models, their performance remains limited in adversarial test scenarios. Additionally, the study proposes a dynamic attention-guided question control unit to guide the model's multi-hop reasoning, and demonstrates that this model has strong robustness against adversarial data.
提供机构:
sagnikrayc
原始信息汇总
数据集概述
基本信息
- 许可证:afl-3.0
- 任务类别:question-answering
- 语言:en
- 数据集名称:Adversarial-MultiHopQA
- 数据集大小:10K<n<100K
来源
- 论文标题:Avoiding Reasoning Shortcuts: Adversarial Evaluation, Training, and Model Development for Multi-Hop QA
- 作者:Yichen Jiang 和 Mohit Bansal
- 会议:Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics
- 时间:2019年7月
- 地点:Florence, Italy
- 出版商:Association for Computational Linguistics
数据集描述
- 问题:多跳问答(Multi-Hop QA)数据集HotpotQA中存在推理捷径问题,模型可能通过问题与上下文中的句子进行词匹配直接定位答案,而非进行多跳推理。
- 解决方案:构建对抗性文档,创建与捷径答案相矛盾但不会影响原始答案有效性的内容。通过对抗性训练和使用控制单元动态关注不同推理跳跃中的问题,提高模型在对抗性测试中的性能,增强多跳推理能力。
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,多跳问答任务要求模型整合分散于长文本中的多条证据以生成答案。该数据集基于HotpotQA构建,通过对抗性方法生成,旨在揭示模型可能依赖的推理捷径。具体而言,研究者设计了一种对抗性文档构造策略,在保持原始答案有效性的前提下,引入与问题词汇匹配但内容矛盾的干扰信息,从而迫使模型避免简单的词汇匹配,转而进行真正的多步推理。
特点
该数据集的核心特点在于其对抗性评估框架,专门针对多跳问答中的推理捷径问题。它包含常规样本与对抗样本的对比,其中对抗样本通过精心设计的干扰文档,挑战模型仅依赖表面线索的倾向。数据规模介于一万至十万之间,语言为英语,适用于问答任务类别。这一设计使得数据集能够有效检验模型的鲁棒性与深层推理能力,为多跳推理研究提供了重要的基准工具。
使用方法
使用该数据集时,研究者可将其应用于多跳问答模型的训练与评估,以提升模型的抗干扰能力。数据集支持对抗性训练,即模型在常规数据与对抗数据上交替学习,从而增强其避免推理捷径的倾向。在评估阶段,通过对比模型在常规测试集与对抗测试集上的表现,可以量化模型的推理鲁棒性。此外,数据集附带的原始代码库便于复现实验,促进模型开发与比较研究。
背景与挑战
背景概述
在自然语言处理领域,多跳问答任务要求模型能够整合分散在长文本中的多个证据片段以生成准确答案,这一研究方向对于提升机器理解复杂逻辑关系的能力至关重要。由Yichen Jiang和Mohit Bansal于2019年创建的Adversarial-MultiHopQA数据集,基于HotpotQA框架,旨在通过对抗性评估揭示并解决模型在多跳推理中存在的‘推理捷径’问题。该数据集由北卡罗来纳大学教堂山分校的研究团队开发,其核心研究焦点在于推动模型超越表面词汇匹配,实现真正的多步逻辑推理,从而对问答系统的鲁棒性发展产生了深远影响。
当前挑战
Adversarial-MultiHopQA数据集所针对的核心挑战在于多跳问答中模型易受‘推理捷径’干扰,即仅通过问题与上下文的简单词汇匹配即可定位答案,而非执行深层次的多步推理。为应对此问题,数据集的构建过程中引入了对抗性文档,这些文档在保持原始答案有效性的同时,通过制造矛盾答案来暴露模型的脆弱性。然而,构建过程本身面临挑战,包括如何设计对抗性样本以避免引入新的捷径,并确保评估能准确反映模型的真实推理能力,而非对特定数据模式的过度拟合。
常用场景
经典使用场景
在自然语言处理领域,多跳问答任务要求模型整合分散于长文本中的多个证据片段以生成准确答案。Adversarial HotpotQA数据集通过引入对抗性文档,巧妙构建了与原始问题存在语义冲突但答案有效的测试样本,从而成为评估模型是否依赖推理捷径而非真正多跳推理能力的经典工具。该数据集通常用于训练和测试问答模型,特别是在对抗性环境下检验其鲁棒性,推动模型从表层词匹配转向深层逻辑推理。
实际应用
在实际应用中,Adversarial HotpotQA为构建高可靠性智能助手提供了关键训练资源。例如,在医疗咨询或法律分析场景中,用户问题常需综合多份文档信息才能解答,模型必须避免基于片面证据的武断结论。该数据集的对抗性设计帮助模型学会识别并规避推理陷阱,从而在真实世界复杂查询中提供更准确、可解释的答案。这不仅增强了问答系统的实用性,也为教育、客服等领域的知识服务奠定了技术基础。
衍生相关工作
该数据集衍生了一系列经典研究工作,主要集中在提升多跳推理的鲁棒性方面。例如,基于动态注意力机制的控制单元被提出,以引导模型在不同推理跳数中聚焦问题核心,有效减少了捷径依赖。后续研究进一步探索了对抗性训练与模型架构的协同优化,如结合图神经网络或预训练语言模型来强化推理路径的显式建模。这些工作共同推动了多跳问答领域向更严谨、可解释的方向发展,形成了从数据构建到方法创新的完整研究脉络。
以上内容由遇见数据集搜集并总结生成


