Llama-Nemotron-Post-Training-Dataset-v1
收藏Hugging Face2025-03-18 更新2025-03-20 收录
下载链接:
https://huggingface.co/datasets/nvidia/Llama-Nemotron-Post-Training-Dataset-v1
下载链接
链接失效反馈官方服务:
资源简介:
Llama-Nemotron后训练数据集v1是一个包含支持数学、代码、泛推理和指令跟随能力提升的数据集,由NVIDIA发布,用于提升Llama-3.3-Nemotron-Super-49B-v1和Llama-3.1-Nemotron-Nano-8B-v1模型的表现。数据集分为SFT和RL两种配置,并包含了数学、代码、科学、聊天和安全等多个类别的数据文件。数据集遵循CC-BY-4.0许可,部分数据遵循ODC-BY和CC-BY-SA许可。
The Llama-Nemotron Post-Training Dataset v1, developed and released by NVIDIA, is a curated dataset designed to enhance mathematical, coding, general reasoning, and instruction-following capabilities, with the primary objective of improving the performance of Llama-3.3-Nemotron-Super-49B-v1 and Llama-3.1-Nemotron-Nano-8B-v1 models. The dataset is structured into two configurations: SFT and RL, and includes data files across multiple categories such as mathematics, coding, science, chat, and safety. This dataset is licensed under CC-BY-4.0, with portions of its data licensed under ODC-BY and CC-BY-SA respectively.
提供机构:
NVIDIA
创建时间:
2025-03-14
搜集汇总
数据集介绍
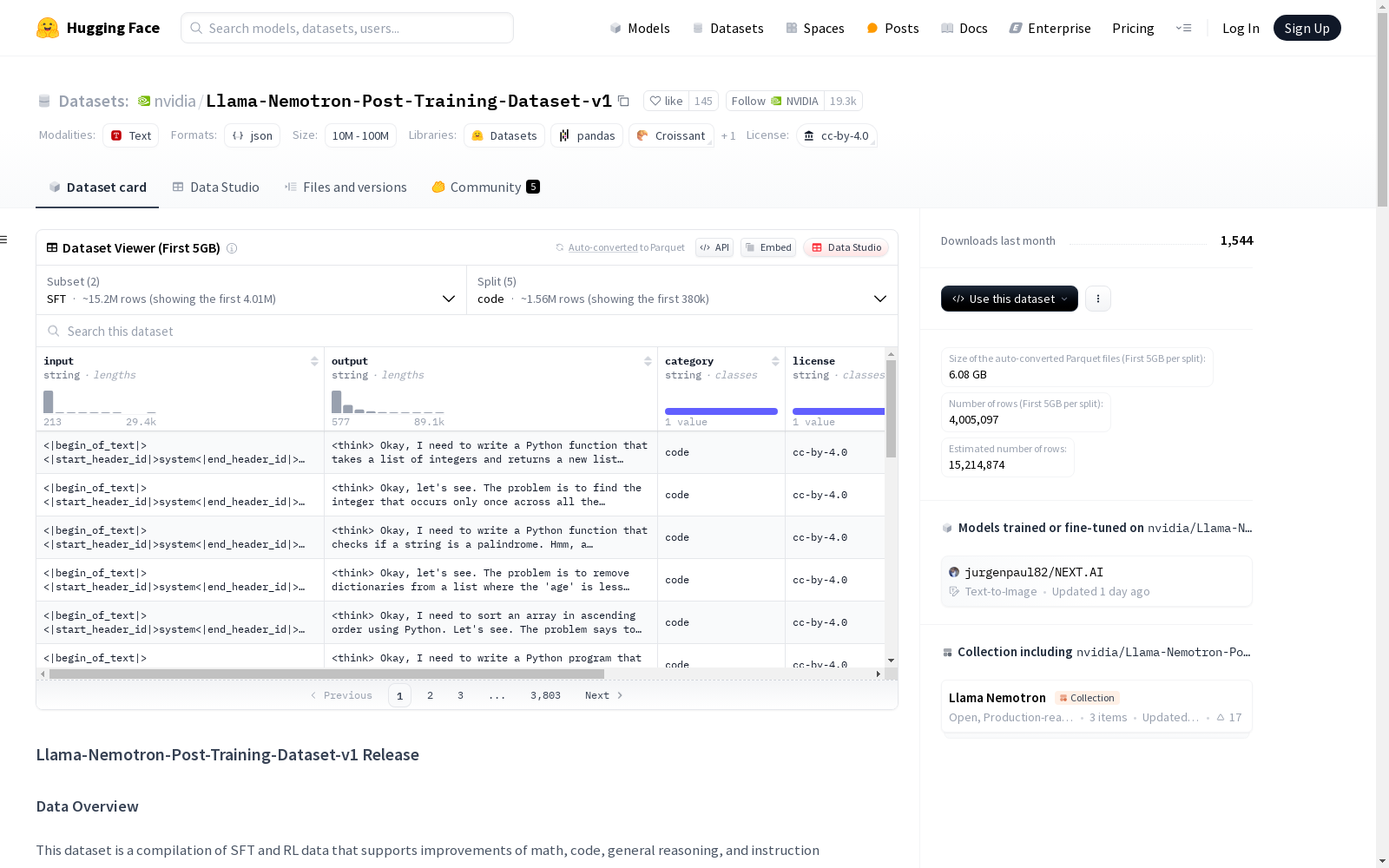
构建方式
Llama-Nemotron-Post-Training-Dataset-v1的构建基于多源数据的整合与筛选,涵盖了代码、数学、科学、聊天和安全等多个领域。数据来源于公开语料库或通过合成生成,经过严格的质量和复杂性过滤,确保数据的多样性和准确性。响应数据则通过多种模型生成,包括Llama-3.3-70B-Instruct、Mixtral-8x22B-Instruct等,以支持模型在不同模式下的推理能力。
使用方法
用户可以通过Hugging Face的`datasets`库轻松下载和使用该数据集。数据集提供了多个配置选项,用户可以根据需求选择特定的数据子集进行下载。例如,通过指定`split`参数,用户可以仅下载代码和数学相关的数据。此外,数据集的使用方法还包括对提示和响应的进一步处理,用户可以根据具体任务需求对数据进行定制化处理,以优化模型的训练效果。
背景与挑战
背景概述
Llama-Nemotron-Post-Training-Dataset-v1数据集由NVIDIA于2025年3月18日发布,旨在支持Llama-3.3-Nemotron-Super-49B-v1和Llama-3.1-Nemotron-Nano-8B-v1等大型语言模型的后续训练与优化。该数据集涵盖了数学、代码、科学、指令遵循、聊天和安全等多个领域的数据,旨在提升模型在复杂任务中的表现。通过引入神经架构搜索(NAS)技术,NVIDIA在模型精度与效率之间取得了显著平衡,使其能够在单GPU上高效运行。这一数据集的发布标志着模型开发透明度的提升,为社区提供了完整的训练集和技术支持,推动了开放模型的进一步发展。
当前挑战
Llama-Nemotron-Post-Training-Dataset-v1在构建过程中面临多重挑战。首先,数据质量与复杂度的筛选是关键,需剔除不一致、易猜测或语法错误的提示,以确保训练数据的有效性。其次,响应数据的生成依赖于多种模型,需协调不同模型的输出风格与质量,以保持数据的一致性。此外,数据集涵盖多个领域,需确保各领域数据的平衡性与代表性,避免模型在特定任务上表现偏差。最后,数据集的开放性与透明性要求NVIDIA在数据收集与处理过程中严格遵守伦理与法律规范,确保无隐私泄露或版权争议。这些挑战共同构成了该数据集构建的核心难点。
常用场景
经典使用场景
Llama-Nemotron-Post-Training-Dataset-v1数据集在自然语言处理领域中被广泛用于提升大型语言模型在数学、代码、科学推理及指令遵循等方面的能力。通过该数据集,研究人员能够对模型进行精细调优,使其在复杂的推理任务中表现出更高的准确性和效率。特别是在多模态任务中,该数据集通过提供丰富的训练样本,帮助模型更好地理解和生成复杂的语言结构。
解决学术问题
该数据集解决了大型语言模型在特定领域任务中的性能瓶颈问题。通过提供高质量的数学、代码和科学推理数据,研究人员能够显著提升模型在这些领域的表现。此外,数据集中的指令遵循数据帮助模型更好地理解并执行复杂的用户指令,从而推动了自然语言处理领域在任务导向型对话系统中的应用研究。
实际应用
Llama-Nemotron-Post-Training-Dataset-v1在实际应用中主要用于开发智能代理系统、聊天机器人以及基于检索增强生成(RAG)的AI应用。例如,在金融领域,该数据集可用于训练能够自动生成复杂财务报告的模型;在教育领域,它能够帮助开发智能辅导系统,为学生提供个性化的学习支持。
数据集最近研究
最新研究方向
Llama-Nemotron-Post-Training-Dataset-v1作为支持NVIDIA最新大语言模型Llama-3.3-Nemotron-Super-49B-v1和Llama-3.1-Nemotron-Nano-8B-v1的关键数据集,其研究方向主要集中在提升模型在数学、代码、科学推理及指令遵循等领域的性能。该数据集通过结合监督微调(SFT)和强化学习(RL)技术,显著增强了模型的多任务处理能力。当前研究热点包括利用神经架构搜索(NAS)技术优化模型效率与精度的平衡,以及探索如何通过大规模合成数据进一步提升模型的泛化能力。这一数据集的发布不仅推动了开放模型的发展,也为AI社区提供了丰富的资源,助力开发更高效、更智能的AI应用系统。
以上内容由遇见数据集搜集并总结生成


