MultiWikiQA
收藏arXiv2025-09-05 更新2025-09-09 收录
下载链接:
https://huggingface.co/datasets/alexandrainst/multi-wiki-qa
下载链接
链接失效反馈官方服务:
资源简介:
MultiWikiQA是一个包含306种语言的阅读理解数据集,数据来源于维基百科文章。问题由大型语言模型(LLM)生成,答案直接取自文章。通过众包对30多种语言的生成问题进行了流畅性评估,证明问题质量良好。对6种不同大小的解码器和编码器语言模型进行了评估,结果显示该基准足够困难,不同语言之间存在较大的性能差异。
MultiWikiQA is a reading comprehension dataset covering 306 languages, with data sourced from Wikipedia articles. Questions are generated by Large Language Models (LLMs), and the answers are directly extracted from the articles. A fluency evaluation of the generated questions in over 30 languages was conducted via crowdsourcing, which verified the good quality of the questions. Six decoder and encoder language models of varying sizes were evaluated, and the results demonstrated that this benchmark is sufficiently challenging, with considerable performance gaps across different languages.
提供机构:
丹麦亚历山大研究所
创建时间:
2025-09-04
原始信息汇总
数据集概述
基本信息
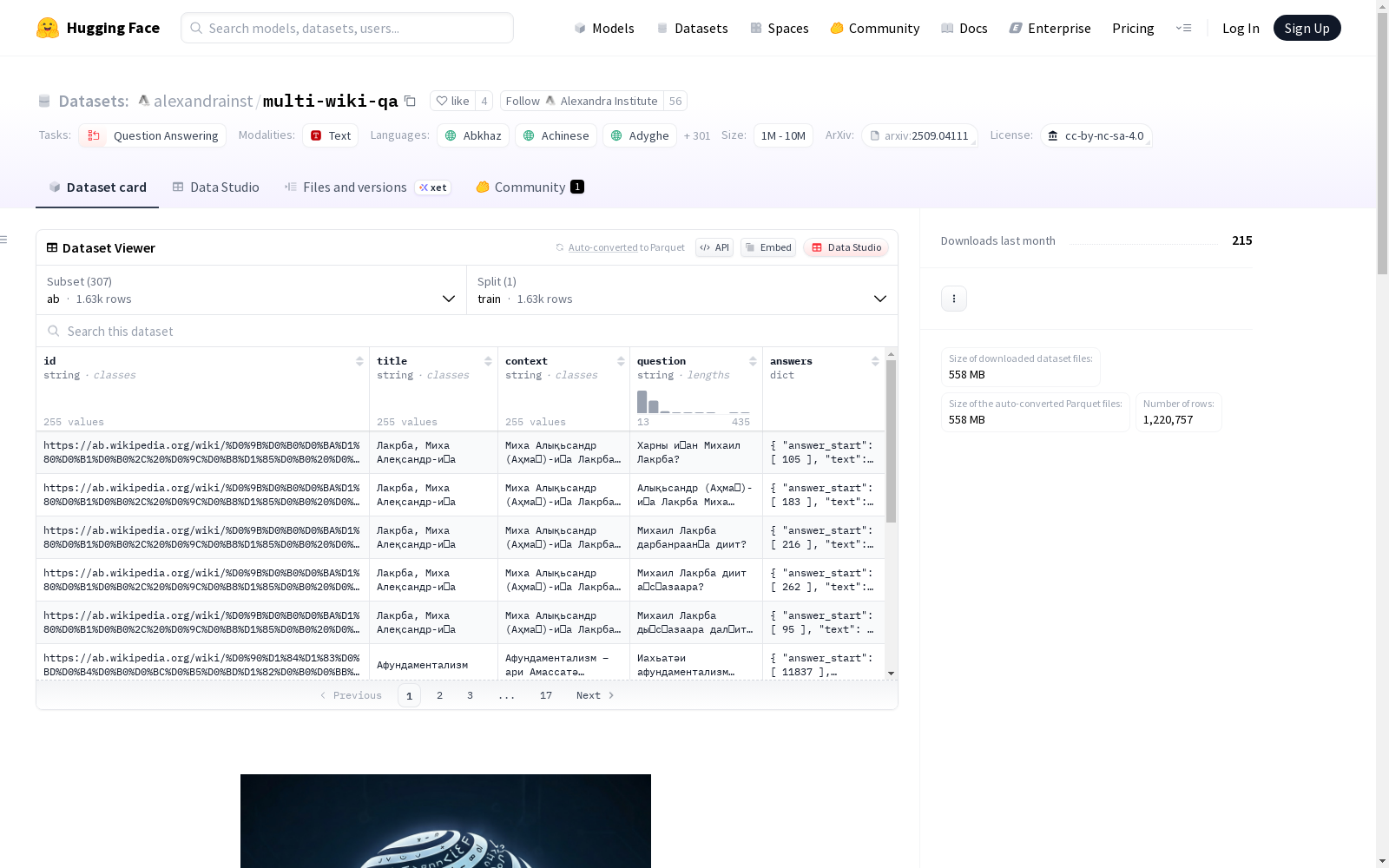
- 数据集名称: multi-wiki-qa
- 存储位置: https://huggingface.co/datasets/alexandrainst/multi-wiki-qa
- 配置数量: 60种语言配置
数据结构
所有配置包含相同特征:
- id: 字符串类型标识符
- title: 字符串类型标题
- context: 字符串类型上下文
- question: 字符串类型问题
- answers: 结构体类型答案,包含:
- answer_start: int64序列类型答案起始位置
- text: 字符串序列类型答案文本
配置详情
各语言配置均包含训练集分割,具体包括:
主要语言配置示例
- ab: 1,625样本,12.59MB大小
- ace: 2,210样本,7.00MB大小
- ady: 380样本,2.47MB大小
- af: 5,001样本,22.42MB大小
- als: 5,000样本,18.71MB大小
- alt: 5,000样本,50.86MB大小
- am: 5,007样本,56.78MB大小
- ami: 2,920样本,28.16MB大小
- an: 5,006样本,16.73MB大小
- ang: 3,376样本,10.24MB大小
- anp: 3,667样本,49.49MB大小
- ar: 5,003样本,37.86MB大小
- arc: 251样本,0.94MB大小
- ary: 5,005样本,21.21MB大小
- arz: 5,001样本,12.11MB大小
- as: 4,999样本,50.76MB大小
- ast: 5,000样本,34.10MB大小
- atj: 1,064样本,2.84MB大小
- av: 4,375样本,32.39MB大小
- avk: 5,002样本,9.18MB大小
- awa: 1,385样本,12.87MB大小
- ay: 5,004样本,11.52MB大小
- az: 5,002样本,23.70MB大小
- azb: 5,001样本,27.20MB大小
- ba: 4,998样本,38.79MB大小
- ban: 5,007样本,13.85MB大小
- bar: 5,000样本,18.71MB大小
- bcl: 5,006样本,17.27MB大小
- be: 5,000样本,28.75MB大小
- bg: 5,002样本,37.83MB大小
- bi: 149样本,0.34MB大小
- bjn: 5,000样本,17.46MB大小
- blk: 5,000样本,68.58MB大小
- bm: 663样本,2.44MB大小
- bn: 4,995样本,49.33MB大小
- bo: 5,001样本,229.87MB大小
- bpy: 2,561样本,13.97MB大小
- br: 5,001样本,13.77MB大小
- bs: 5,002样本,20.20MB大小
- bug: 119样本,0.62MB大小
- bxr: 5,005样本,33.01MB大小
- ca: 5,006样本,21.12MB大小
- cdo: 1,780样本,7.68MB大小
- ce: 5,000样本,25.05MB大小
- ceb: 5,002样本,7.66MB大小
- ch: 135样本,0.32MB大小
- chr: 185样本,2.83MB大小
- chy: 25样本,0.05MB大小
- ckb: 5,004样本,37.54MB大小
- co: 配置信息不完整
数据规模
- 总样本量: 超过20万个问答对
- 数据格式: 标准化问答对结构
- 语言覆盖: 涵盖60种不同语言变体
搜集汇总
数据集介绍
构建方式
在跨语言阅读理解任务日益重要的背景下,MultiWikiQA采用基于维基百科文章的结构化生成方法构建。首先利用Gemini-1.5-pro模型从多语言维基文档中生成初始问答对,通过JSON结构化输出确保答案与原文严格匹配;随后引入问题重构阶段,使用同义替换和句式转换技术对生成的问题进行改写,有效避免了模型通过词汇匹配作弊的问题;最终通过自动化过滤和人工验证流程,形成包含306种语言的上下文-问题-答案三元组数据集。
使用方法
数据集适用于编码器、解码器和编码器-解码器架构的跨语言评估,使用时需遵循特定数据处理流程。对于解码器模型推荐采用2-shot评估方式,从训练分割中选取示例进行上下文学习;编码器模型则需要在训练集上微调,使用验证集进行早停策略,最终在测试集上报告性能。评估框架建议采用EuroEval标准,重点关注F1分数指标,同时注意不同语言族之间的性能差异分析。
背景与挑战
背景概述
MultiWikiQA数据集由Alexandra Institute的Dan Saattrup Smart团队于2025年创建,旨在解决多语言阅读理解评估资源匮乏的问题。该数据集基于Wikipedia文章构建,覆盖306种语言,通过大语言模型生成问题与答案对,为低资源语言的自然语言处理研究提供了重要基准。其创新性在于大幅扩展了语言覆盖范围,填补了传统多语言数据集仅关注高资源语言的空白,对推动跨语言信息检索和机器阅读理解技术的发展具有显著影响力。
当前挑战
该数据集面临的领域挑战包括如何确保低资源语言的阅读理解性能与高资源语言相当,以及如何解决语言模型在不同语言间的性能差异问题。构建过程中的挑战主要涉及多语言问题生成的流畅性与准确性验证,特别是对300余种语言进行人工质量评估的可行性;同时需克服Wikipedia文章质量不均导致的上下文噪声,以及避免模型通过简单词汇匹配而非真正理解文本内容来回答问题。
常用场景
经典使用场景
在跨语言阅读理解研究领域,MultiWikiQA数据集为评估多语言模型的文本理解能力提供了标准化测试平台。该数据集通过覆盖306种语言的维基百科文章构建上下文语料,并采用大语言模型生成与原文答案严格匹配的问题,有效模拟了真实跨语言信息检索场景。研究人员可利用该数据集系统评估不同架构模型在低资源语言上的泛化能力,尤其适用于分析语言模型在提取式问答任务中的跨语言迁移表现。
解决学术问题
该数据集显著解决了多语言自然语言处理中评估资源匮乏的核心问题,特别是为低资源语言提供了高质量阅读理解基准。通过构建大规模跨语言评估体系,它使研究人员能够量化分析模型性能的语言依赖性差异,揭示语言类型特征对模型表现的影响机制。其构建方法为生成式数据增强提供了可复现范式,推动了跨语言表示学习理论与应用的发展,对缩小数字语言鸿沟具有重要学术价值。
实际应用
在实际应用层面,MultiWikiQA为构建多语言智能问答系统和检索增强生成(RAG)系统提供了关键训练与评估资源。企业可借助该数据集开发支持小众语言的文档分析工具,特别是在国际化和本地化服务中实现非通用语言的信息提取功能。教育机构也能利用其构建多语言教学辅助系统,为语言学习者提供自动化的阅读理解评估服务,有效促进语言技术的普惠化应用。
数据集最近研究
最新研究方向
随着多语言自然语言处理技术的快速发展,MultiWikiQA数据集已成为评估跨语言阅读理解模型性能的重要基准。该数据集涵盖306种语言,其基于维基百科文章构建,通过大语言模型生成问题与答案对,显著提升了低资源语言的评估覆盖率。当前研究聚焦于探索多语言模型在提取式问答任务中的泛化能力,尤其是针对语言资源匮乏的语种性能差异分析。前沿工作涉及利用该数据集验证检索增强生成(RAG)系统的跨语言适应性,以及分析模型在不同语系中的表现偏差。这一研究方向对推动全球化信息检索系统和公平人工智能发展具有深远意义,为多语言自然语言理解技术的标准化评估提供了关键支撑。
相关研究论文
- 1MultiWikiQA: A Reading Comprehension Benchmark in 300+ Languages丹麦亚历山大研究所 · 2025年
以上内容由遇见数据集搜集并总结生成


