lusana
收藏Hugging Face2024-10-12 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/nyuuzyou/lusana
下载链接
链接失效反馈官方服务:
资源简介:
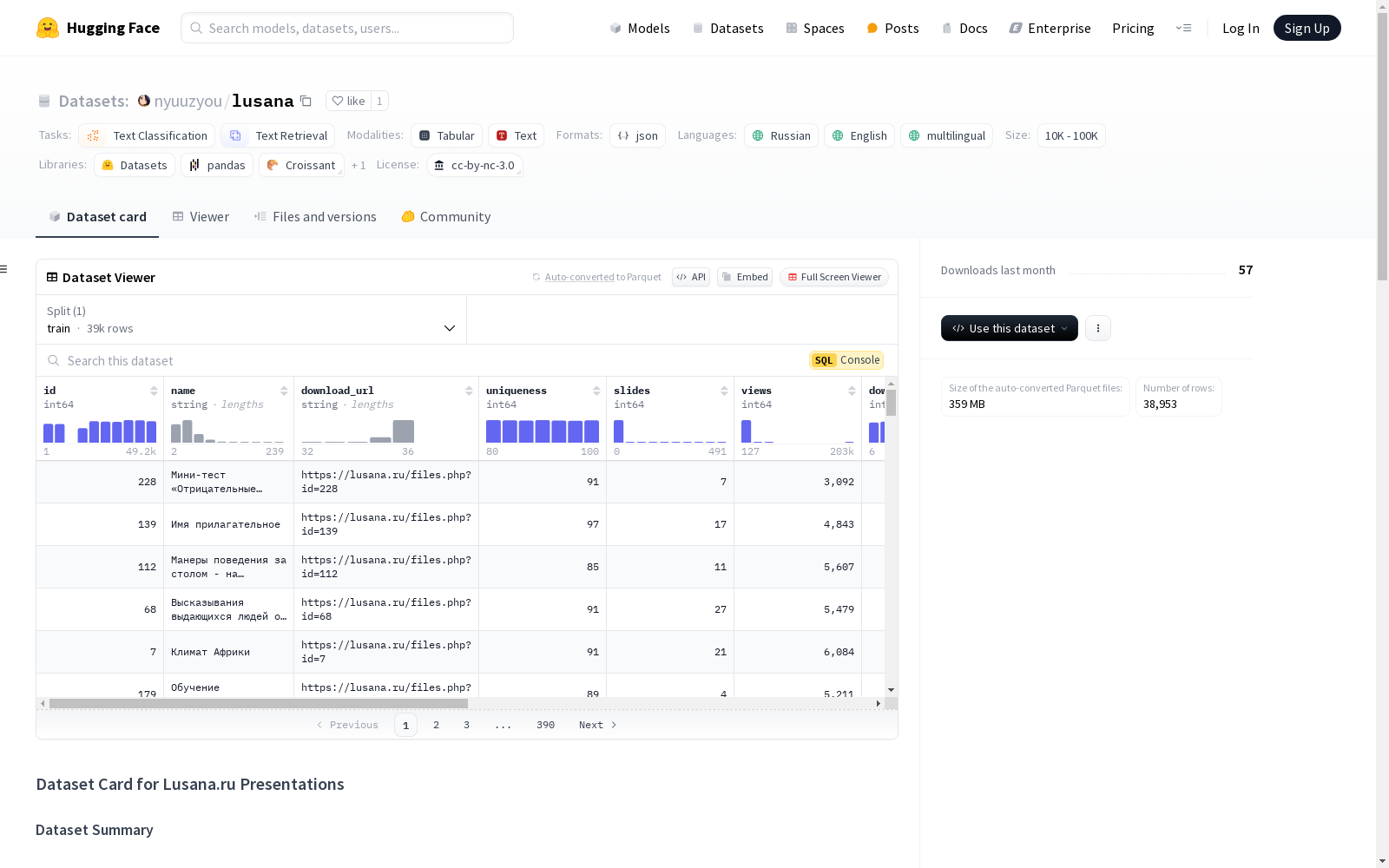
该数据集包含来自lusana.ru平台的38,953个演示文稿的元数据和原始文件。这些演示文稿以PPT/PPTX格式存储,并包含诸如演示文稿标题、下载URL、唯一性评分、幻灯片数量、浏览量、下载量、文件大小和提取的文本内容等元数据字段。该数据集是多语言的,主要语言为俄语,还包括英语和一些其他语言的内容。该数据集根据Creative Commons Attribution-NonCommercial 3.0 Unported (CC BY-NC 3.0)许可证授权。
This dataset contains metadata and original files of 38,953 presentations from the lusana.ru platform. These presentations are stored in PPT/PPTX format, and include metadata fields such as presentation title, download URL, uniqueness score, number of slides, page views, download counts, file size, and extracted text content. This dataset is multilingual, with Russian as the primary language, and also includes content in English and several other languages. This dataset is licensed under the Creative Commons Attribution-NonCommercial 3.0 Unported (CC BY-NC 3.0) license.
创建时间:
2024-10-11
原始信息汇总
Lusana.ru Presentations Dataset
数据集概述
该数据集包含来自lusana.ru平台的38,953个演示文稿的元数据和原始文件,该平台是一个用于存储PPT/PPTX格式的演示文稿、报告、模板和背景的服务。数据集包括演示文稿的标题、下载URL、唯一性评分、幻灯片数量、浏览量、下载量、文件大小以及提取的文本内容(如果可用)。
语言
该数据集是多语言的,主要语言为俄语。其他语言包括:
- 俄语 (ru):大部分内容
- 英语 (en):主要用于英语课程,数据集的一小部分
- 其他:可能包含其他语言的内容
数据集结构
数据文件
数据集包括:
- 元数据:存储在JSON Lines格式中
- 演示文稿文件:原始PPT/PPTX文件
数据字段
数据集包含以下字段:
id:演示文稿的唯一标识符(整数)name:演示文稿的标题(字符串)download_url:演示文稿的下载URL(字符串)uniqueness:演示文稿的唯一性评分(整数)slides:演示文稿中的幻灯片数量(整数)views:演示文稿的浏览量(整数)downloads:演示文稿的下载量(整数)size:演示文稿的文件大小(字符串)filepath:下载的演示文稿的本地文件路径(字符串)text:提取的演示文稿文本内容(字符串或null)
数据分割
所有示例都在一个分割中。
附加信息
许可证
该数据集根据Creative Commons Attribution-NonCommercial 3.0 Unported (CC BY-NC 3.0)许可证授权。这意味着您可以:
- 分享:以任何媒介或格式复制和重新分发材料
- 改编:重新混合、转换和构建材料
在以下条件下:
- 署名:您必须给予适当的署名,提供许可证的链接,并指出是否进行了更改。您可以以任何合理的方式进行署名,但不得以任何方式暗示许可人认可您或您的使用。
- 非商业性:您不得将材料用于商业目的。
没有附加限制:您不得应用法律条款或技术措施,这些条款或措施在法律上限制他人进行许可证允许的任何事情。
CC BY-NC 3.0许可证:https://creativecommons.org/licenses/by-nc/3.0/
要了解更多关于CC BY-NC 3.0的信息,请访问Creative Commons网站:https://creativecommons.org/licenses/by-nc/3.0/legalcode
注意:此许可证适用于与平台原始内容的许可条款相对应。有关平台许可的更多详细信息,请访问:https://lusana.ru/we
数据集创建者
搜集汇总
数据集介绍
构建方式
Lusana.ru Presentations数据集构建于lusana.ru平台,该平台专注于存储PPT/PPTX格式的演示文稿、报告、模板和背景。数据集通过收集平台上的38,953个演示文稿的元数据和原始文件,采用JSON Lines格式存储元数据,并保留了原始PPT/PPTX文件。数据字段包括演示文稿的唯一标识符、标题、下载链接、唯一性评分、幻灯片数量、浏览量、下载次数、文件大小、本地文件路径以及提取的文本内容。
使用方法
Lusana.ru Presentations数据集的使用方法包括下载元数据和原始PPT/PPTX文件,用户可以通过JSON Lines格式的元数据进行数据分析和处理。数据集适用于文本分类、文本检索等任务,用户可以根据演示文稿的标题、提取文本内容等字段进行模型训练和评估。在使用过程中,用户需遵守Creative Commons Attribution-NonCommercial 3.0 Unported (CC BY-NC 3.0)许可协议,确保非商业用途并给予适当的署名。
背景与挑战
背景概述
Lusana.ru Presentations Dataset 是一个包含来自Lusana.ru平台的38,953份演示文稿的元数据和原始文件的数据集。该平台主要用于存储PPT/PPTX格式的演示文稿、报告、模板和背景。数据集由nyuuzyou等研究人员于近年构建,旨在为文本分类和文本检索任务提供多语言支持,尤其是俄语和英语。该数据集的核心研究问题在于如何通过大规模演示文稿数据提升文本处理模型的性能,特别是在多语言环境下的应用。其影响力主要体现在为自然语言处理领域提供了丰富的多语言文本资源,推动了相关技术的发展。
当前挑战
Lusana.ru Presentations Dataset 在构建和应用过程中面临多重挑战。首先,数据集的多样性和多语言特性使得文本分类和检索任务更加复杂,尤其是在处理俄语和英语混合内容时,模型需要具备强大的跨语言理解能力。其次,数据集中包含的演示文稿格式多样,文本提取的准确性和完整性成为技术难点,尤其是在处理PPT/PPTX文件时,如何有效提取结构化文本内容仍需进一步优化。此外,数据集的非商业许可限制了其在商业场景中的应用,可能影响其广泛推广和使用。这些挑战不仅反映了数据集构建的技术难度,也凸显了多语言文本处理领域的核心问题。
常用场景
经典使用场景
Lusana.ru Presentations Dataset在自然语言处理领域中被广泛应用于文本分类和信息检索任务。该数据集包含了大量来自lusana.ru平台的演示文稿,涵盖了多种语言,尤其是俄语和英语。研究人员可以利用这些数据进行多语言文本分析,训练和评估文本分类模型,以及开发高效的文本检索系统。
解决学术问题
该数据集解决了多语言文本处理中的关键问题,特别是在俄语和英语混合环境下的文本分类和信息检索。通过提供丰富的元数据和原始文件,研究人员能够深入分析演示文稿的内容结构,探索文本特征提取的有效方法,并开发出适应多语言环境的先进算法。
实际应用
在实际应用中,Lusana.ru Presentations Dataset被广泛用于教育和企业培训领域。教育机构可以利用这些演示文稿资源进行课程设计和教学材料开发,而企业则可以通过分析演示文稿的内容和结构,优化内部培训和报告流程,提升信息传递的效率。
数据集最近研究
最新研究方向
在自然语言处理领域,Lusana数据集因其多语言特性和丰富的文本内容,成为研究文本分类与检索任务的重要资源。近年来,随着多语言模型的快速发展,研究者们开始利用该数据集探索跨语言文本理解与生成的新方法。特别是在俄语与英语的双语处理中,Lusana数据集为模型训练提供了多样化的语料支持,推动了多语言信息检索系统的性能提升。此外,该数据集中的PPT文件及其元数据为文档结构分析与内容提取提供了独特的研究场景,进一步拓展了文本处理技术在多媒体文档中的应用边界。
以上内容由遇见数据集搜集并总结生成


