seungheondoh/music-audio-pseudo-captions
收藏Hugging Face2023-08-16 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/seungheondoh/music-audio-pseudo-captions
下载链接
链接失效反馈官方服务:
资源简介:
与其他领域相比,音乐和音频领域难以获取高质量的网页标注数据,且标注成本高。因此,我们使用了由ChatGPT创建的音乐(LP-MusicCaps)、音乐否定/时间排序(Music Negation/Temporal Ordering)和音频(WavCaps)数据集,并以指令、输入和输出的形式重新组织,类似于Alpaca格式。该数据集的目的是用于微调大型语言模型(LLMs)。
提供机构:
seungheondoh
原始信息汇总
数据集卡片:Music-Audio-Pseudo Captions
数据集概述
Music-Audio-Pseudo Captions 数据集源自以下几个数据源:
与其他领域相比,音乐和音频领域难以获取高质量的网络描述数据,且描述标注成本高昂。因此,我们利用 ChatGPT 生成的 Music (LP-MusicCaps)、(Music Negation/Temporal Ordering) 和 Audio (WavCaps) 数据集,重新组织成 instructions、input 和 output 的形式(与 Alpaca 格式相同)。
该数据集旨在用于微调大型语言模型(LLMs)。
数据集详情
- 许可:MIT
- 任务类别:text2text-generation
- 语言:英语(en)
- 标签:music, audio, caption
- 数据规模:100K<n<1M
搜集汇总
数据集介绍
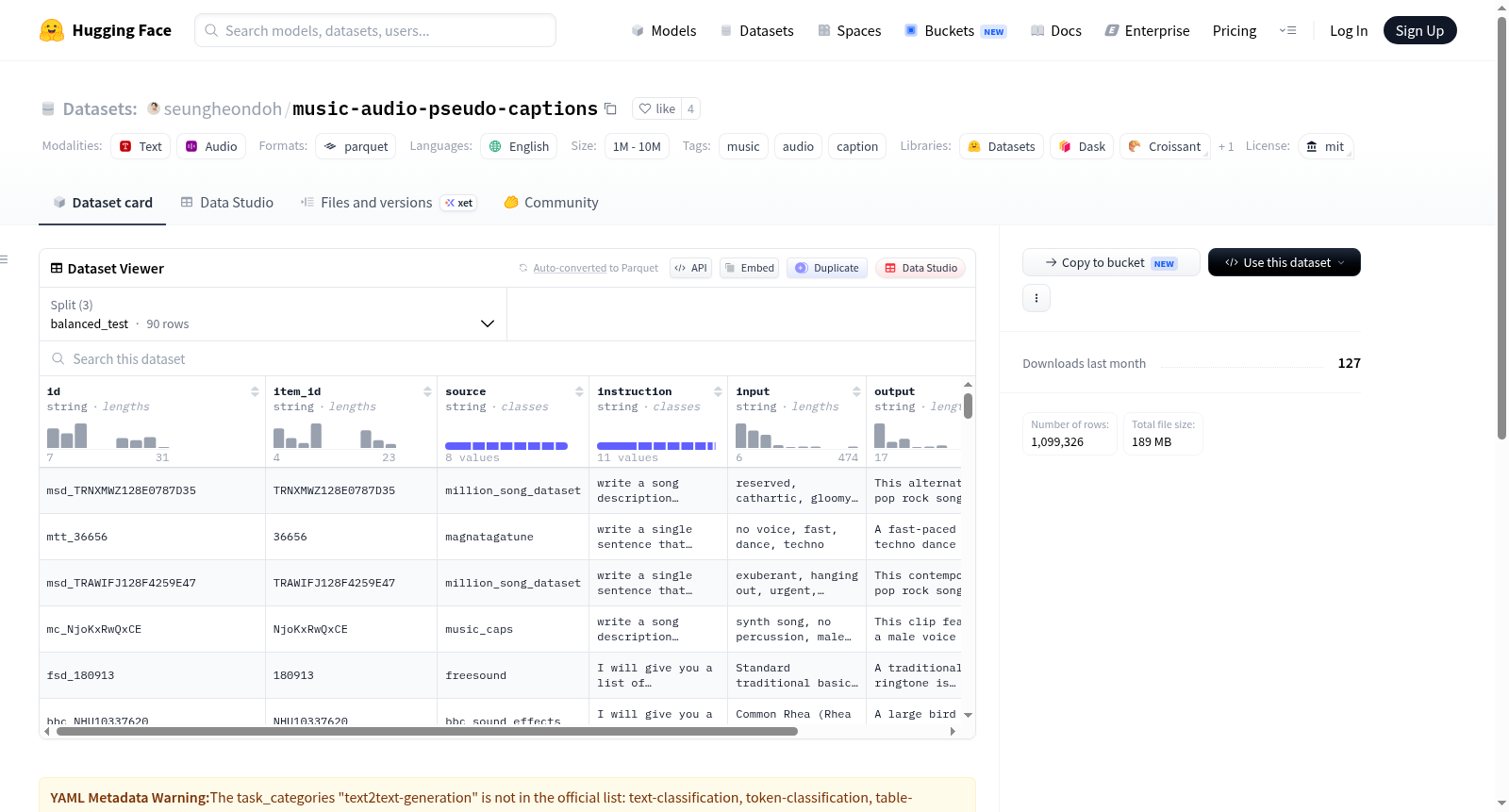
构建方式
在音乐与音频领域,高质量的自然语言描述数据稀缺且标注成本高昂,这为多模态模型的训练带来了挑战。为应对这一困境,本数据集巧妙整合了源自ChatGPT生成的LP-MusicCaps、Music Negation/Temporal Ordering以及WavCaps三个子数据集,并将其重新组织为与Alpaca格式一致的指令(instruction)、输入(input)与输出(output)三元组结构。通过这种系统化的重组方式,原始分散的伪标注数据被转化为结构清晰、可直接用于微调大语言模型的训练语料。
使用方法
本数据集专为文本生成任务设计,尤其适用于对大语言模型进行指令微调。使用时,可直接将instruction字段作为模型输入,input字段作为上下文补充(或留空),output字段作为期望的生成目标。研究者可基于HuggingFace的datasets库轻松加载数据,并结合标准训练框架(如Transformers)构建微调流程。推荐采用因果语言建模方式,通过监督学习使模型学会根据指令与输入生成准确的音频描述,从而提升其在音乐与音频内容理解任务上的表现。
背景与挑战
背景概述
在音乐与音频领域,自然语言描述数据的匮乏长期制约着多模态模型的进步。由于网络上的音频标题数据质量参差不齐,且人工标注成本高昂,研究者难以获得大规模、高质量的图文对齐语料。由Seungheon Doh等人于近年构建的Music-Audio-Pseudo Captions数据集,正是为解决这一瓶颈而生。该数据集整合了LP-MusicCaps、Music Negation/Temporal Ordering以及WavCaps三个经由ChatGPT生成的伪标注资源,并采用类似Alpaca的指令-输入-输出格式进行重组,旨在为大型语言模型的微调提供结构化的音频文本配对数据。这一工作不仅缓解了音频领域标注数据稀缺的困境,也为音乐理解与跨模态生成任务提供了关键的基础资源,对推动智能音频分析技术的发展具有重要影响。
当前挑战
当前数据集面临的核心挑战体现在两个层面。首先,在领域问题层面,音乐与音频描述生成任务长期受困于高质量文本标注的缺失,现有网络标题往往包含噪声或与内容不匹配,而人工标注的高昂成本又限制了数据规模,使得模型难以学习到细粒度、语义丰富的音频-文本映射关系。其次,在构建过程中,该数据集依赖ChatGPT生成伪标签,尽管降低了成本,却引入了潜在的不准确性与语义偏差,例如对乐器、节奏等专业术语的误用,或对时序关系的错误描述。此外,跨数据源整合时,不同来源的标注风格与格式差异增加了统一处理的难度,伪标签的验证与清洗也缺乏有效的自动化手段,这些因素共同制约了数据集在下游任务中的泛化能力与可靠性。
常用场景
经典使用场景
在音乐与音频处理领域,由于高质量描述性文本的匮乏,该数据集被广泛用于微调大语言模型(LLMs),使其能够生成与音频内容相匹配的自然语言描述。通过整合LP-MusicCaps、Music Negation/Temporal Ordering和WavCaps等现有资源,并以指令-输入-输出格式重新组织,研究者得以训练模型在音乐情感分析、音频事件识别等任务中实现精准的文本生成。这一场景极大降低了人工标注成本,为跨模态学习提供了高效的数据支撑。
解决学术问题
该数据集有效解决了音乐与音频领域缺乏大规模、高质量描述性文本的学术难题。此前,网络爬取数据噪声多、人工标注成本高,限制了文本-音频联合模型的发展。通过利用ChatGPT生成的伪标注,本数据集提供了超过10万条结构化样本,使研究者能够探索弱监督学习、零样本推理等前沿方向。其意义在于打破了数据瓶颈,推动了音频理解与生成模型的性能提升,并为后续研究奠定了可复现的基础。
实际应用
在实际应用中,该数据集可赋能智能音乐推荐系统、音频内容检索工具以及辅助创作平台。例如,用户可通过自然语言查询“欢快的钢琴曲”或“带有雷雨声的背景音”,系统据此精准匹配音频片段。此外,在无障碍技术中,它能帮助视障用户通过文本描述理解音频内容,提升交互体验。音乐教育领域,该数据集还可用于自动生成教学注释,辅助学习者理解作品结构与情感表达。
数据集最近研究
最新研究方向
在音乐与音频理解领域,高质量文本描述数据的稀缺性长期制约着多模态大语言模型的发展。该数据集通过整合LP-MusicCaps、Music Negation/Temporal Ordering及WavCaps三大来源,利用ChatGPT生成的伪标注构建了超过十万条指令-输入-输出三元组,巧妙解决了人工标注成本高昂与网络文本质量参差的困境。这一创新策略不仅为音乐检索、音频事件描述等下游任务提供了规模化的对齐数据,更推动了基于大语言模型的零样本音频理解研究。当前前沿方向聚焦于利用此类伪标注数据微调轻量级语言模型,探索时序推理与否定关系建模等复杂语义理解能力,其成果有望重塑音乐推荐系统与智能音频交互的范式。
以上内容由遇见数据集搜集并总结生成


