google/wiki40b
收藏Hugging Face2024-03-11 更新2024-06-15 收录
下载链接:
https://hf-mirror.com/datasets/google/wiki40b
下载链接
链接失效反馈官方服务:
资源简介:
Wiki-40B 数据集是一个多语言数据集,包含多种语言的维基百科文章。该数据集为每种语言提供了不同的配置,包括 wikidata_id、text 和 version_id 等特征。每种语言配置都包含训练、验证和测试的分割,并提供了具体的字节大小和示例数量。该数据集适用于自然语言处理任务,并提供多种语言的下载。
The Wiki-40B dataset is a multilingual corpus containing Wikipedia articles across various languages. It provides dedicated configurations for each language, with attributes including wikidata_id, text, and version_id. Each language configuration includes train, validation, and test splits, and provides specific byte sizes and example counts. This dataset is suitable for natural language processing (NLP) tasks and supports downloads in multiple languages.
提供机构:
google
原始信息汇总
Wiki-40B 数据集概述
Wiki-40B 是一个多语言文本数据集,包含多种语言的维基百科数据。以下是该数据集的详细信息:
数据集配置
阿拉伯语 (ar)
- 特征:
wikidata_id: 字符串text: 字符串version_id: 字符串
- 分割:
train: 773,508,885 字节, 220,885 样本validation: 44,102,674 字节, 12,198 样本test: 43,755,879 字节, 12,271 样本
- 下载大小: 413,683,528 字节
- 数据集大小: 861,367,438 字节
保加利亚语 (bg)
- 特征:
wikidata_id: 字符串text: 字符串version_id: 字符串
- 分割:
train: 1,413,477,231 字节, 130,670 样本validation: 78,976,448 字节, 7,259 样本test: 78,350,414 字节, 7,289 样本
- 下载大小: 484,828,696 字节
- 数据集大小: 1,570,804,093 字节
加泰罗尼亚语 (ca)
- 特征:
wikidata_id: 字符串text: 字符串version_id: 字符串
- 分割:
train: 784,791,826 字节, 277,313 样本validation: 43,576,907 字节, 15,362 样本test: 44,904,134 字节, 15,568 样本
- 下载大小: 480,954,417 字节
- 数据集大小: 873,272,867 字节
捷克语 (cs)
- 特征:
wikidata_id: 字符串text: 字符串version_id: 字符串
- 分割:
train: 901,187,017 字节, 235,971 样本validation: 49,743,998 字节, 13,096 样本test: 49,325,867 字节, 12,984 样本
- 下载大小: 493,522,926 字节
- 数据集大小: 1,000,256,882 字节
丹麦语 (da)
- 特征:
wikidata_id: 字符串text: 字符串version_id: 字符串
- 分割:
train: 247,928,023 字节, 109,486 样本validation: 13,937,406 字节, 6,173 样本test: 14,401,179 字节, 6,219 样本
- 下载大小: 156,696,617 字节
- 数据集大小: 276,266,608 字节
德语 (de)
- 特征:
wikidata_id: 字符串text: 字符串version_id: 字符串
- 分割:
train: 4,988,094,268 字节, 1,554,910 样本validation: 278,101,948 字节, 86,068 样本test: 278,024,815 字节, 86,594 样本
- 下载大小: 3,174,352,286 字节
- 数据集大小: 5,544,221,031 字节
希腊语 (el)
- 特征:
wikidata_id: 字符串text: 字符串version_id: 字符串
- 分割:
train: 1,738,534,924 字节, 93,596 样本validation: 97,711,791 字节, 5,130 样本test: 99,743,744 字节, 5,261 样本
- 下载大小: 621,575,577 字节
- 数据集大小: 1,935,990,459 字节
英语 (en)
- 特征:
wikidata_id: 字符串text: 字符串version_id: 字符串
- 分割:
train: 9,423,468,036 字节, 2,926,536 样本validation: 527,374,301 字节, 163,597 样本test: 522,210,646 字节, 162,274 样本
- 下载大小: 6,183,831,905 字节
- 数据集大小: 10,473,052,983 字节
西班牙语 (es)
- 特征:
wikidata_id: 字符串text: 字符串version_id: 字符串
- 分割:
train: 2,906,242,601 字节, 872,541 样本validation: 161,381,260 字节, 48,592 样本test: 164,110,964 字节, 48,764 样本
- 下载大小: 1,783,120,767 字节
- 数据集大小: 3,231,734,825 字节
爱沙尼亚语 (et)
- 特征:
wikidata_id: 字符串text: 字符串version_id: 字符串
- 分割:
train: 196,484,412 字节, 114,464 样本validation: 10,987,144 字节, 6,351 样本test: 10,691,693 字节, 6,205 样本
- 下载大小: 122,192,870 字节
- 数据集大小: 218,163,249 字节
波斯语 (fa)
- 特征:
wikidata_id: 字符串text: 字符串version_id: 字符串
- 分割:
train: 1,551,260,324 字节, 203,145 样本validation: 86,108,146 字节, 11,180 样本test: 89,064,531 字节, 11,262 样本
- 下载大小: 552,712,695 字节
- 数据集大小: 1,726,433,001 字节
芬兰语 (fi)
- 特征:
wikidata_id: 字符串text: 字符串version_id: 字符串
- 分割:
train: 589,614,484 字节, 255,822 样本validation: 32,645,294 字节, 13,962 样本test: 32,869,383 字节, 14,179 样本
- 下载大小: 346,601,923 字节
- 数据集大小: 655,129,161 字节
法语 (fr)
- 特征:
wikidata_id: 字符串text: 字符串version_id: 字符串
- 分割:
train: 3,850,031,120 字节, 1,227,206 样本validation: 216,405,364 字节, 68,655 样本test: 215,243,874 字节, 68,004 样本
- 下载大小: 2,246,390,244 字节
- 数据集大小: 4,281,680,358 字节
希伯来语 (he)
- 特征:
wikidata_id: 字符串text: 字符串version_id: 字符串
- 分割:
train: 2,834,322,770 字节, 165,359 样本validation: 160,235,180 字节, 9,231 样本test: 162,131,949 字节, 9,344 样本
- 下载大小: 754,632,129 字节
- 数据集大小: 3,156,689,899 字节
印地语 (hi)
- 特征:
wikidata_id: 字符串text: 字符串version_id: 字符串
- 分割:
train: 947,403,521 字节, 45,737 样本validation: 54,497,912 字节, 2,596 样本test: 54,448,878 字节, 2,643 样本
- 下载大小: 231,716,300 字节
- 数据集大小: 1,056,350,311 字节
克罗地亚语 (hr)
- 特征:
wikidata_id: 字符串text: 字符串version_id: 字符串
- 分割:
train: 247,471,855 字节, 103,857 样本validation: 14,004,242 字节, 5,792 样本test: 13,881,533 字节, 5,724 样本
- 下载大小: 158,644,264 字节
- 数据集大小: 275,357,630 字节
匈牙利语 (hu)
- 特征:
wikidata_id: 字符串text: 字符串version_id: 字符串
- 分割:
train: 878,753,014 字节, 273,248 样本validation: 48,695,962 字节, 15,208 样本test: 50,053,050 字节, 15,258 样本
- 下载大小: 466,524,744 字节
- 数据集大小: 977,502,026 字节
印度尼西亚语 (id)
- 特征:
wikidata_id: 字符串text: 字符串version_id: 字符串
- 分割:
train: 315,092,853 字节, 156,255 样本validation: 16,667,760 字节, 8,714 样本test: 17,798,713 字节, 8,598 样本
- 下载大小: 193,455,048 字节
- 数据集大小: 349,559,326 字节
意大利语 (it)
- 特征:
wikidata_id: 字符串text: 字符串version_id: 字符串
- 分割:
train: 1,998,187,938 字节, 732,609 样本validation: 109,399,796 字节, 40,684 样本test: 108,160,871 字节, 40,443 样本
- 下载大小: 1,330,554,944 字节
- 数据集大小: 2,215,748,605 字节
日语 (ja)
- 特征:
wikidata_id: 字符串text: 字符串version_id: 字符串
- 分割:
train: 7,719,156,890 字节, 745,392 样本validation: 423,396,781 字节, 41,576 样本test: 424,775,191 字节, 41,268 样本
- 下载大小: 2,914,923,230 字节
- 数据集大小: 8,567,328,862 字节
韩语 (ko)
- 特征:
wikidata_id: 字符串text: 字符串version_id: 字符串
- 分割:
train: 1,424,423,053 字节, 194,977 样本validation: 79,027,067 字节, 10,805 样本test: 78,623,281 字节, 10,802 样本
- 下载大小: 568
搜集汇总
数据集介绍
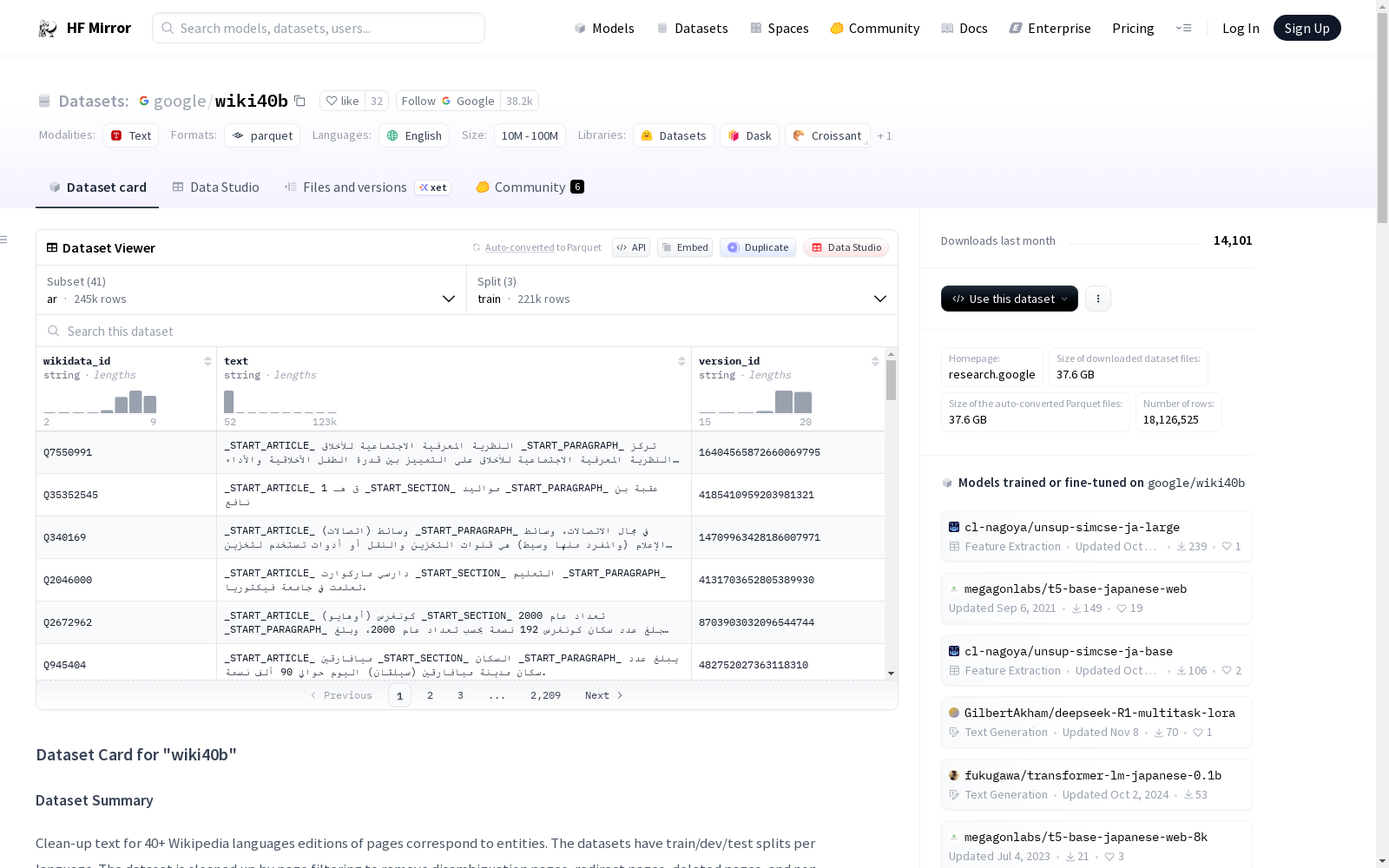
构建方式
在跨语言自然语言处理领域,大规模语料库的构建对于模型训练至关重要。Wiki40B数据集源自维基百科的多语言条目,通过系统化的数据采集与清洗流程构建而成。该数据集涵盖了40种语言的文本内容,每种语言均独立配置,包含训练集、验证集和测试集的标准划分。构建过程中,原始维基百科页面经过解析,提取出纯文本内容,并保留了条目的元数据标识,如Wikidata ID和版本信息,确保了数据的可追溯性与完整性。这种结构化的构建方式为多语言模型的训练提供了高质量的语料基础。
特点
Wiki40B数据集以其广泛的语言覆盖和丰富的文本规模脱颖而出。该数据集囊括了从阿拉伯语到中文简体的40种语言,每种语言均提供独立的文本集合,其中英语、俄语、日语等语言的文本量尤为庞大。数据条目包含文本内容、Wikidata ID和版本ID三个核心特征,使得每条数据都能与知识图谱中的实体精确关联。数据集的划分遵循机器学习标准,设有训练、验证和测试子集,便于模型开发与评估。这种多语言、高结构化的特点使其成为跨语言理解和生成任务的重要资源。
使用方法
在应用层面,Wiki40B数据集主要服务于多语言自然语言处理模型的训练与评估。研究人员可通过HuggingFace平台直接加载特定语言的配置,例如选择“en”配置获取英语数据。数据集以标准分割形式提供,用户可分别调用训练、验证和测试集进行模型训练、超参数调优和性能测试。每条数据作为独立的文本样本,可直接用于语言建模、机器翻译或文本分类等任务。其结构化的元数据支持与外部知识库的链接,为知识增强型模型提供了便利。使用时应依据目标语言选择相应配置,确保数据加载与处理流程的顺畅。
背景与挑战
背景概述
在自然语言处理领域,多语言文本数据集的构建对于推动跨语言模型的研究与应用具有深远意义。Wiki40B数据集由谷歌研究团队于2019年发布,旨在为40种语言提供高质量、大规模且经过清洗的维基百科文本语料。该数据集的核心研究问题在于解决传统多语言数据集中存在的语言覆盖不均、文本质量参差以及预处理标准不一致等难题,从而为机器翻译、跨语言信息检索及多语言预训练模型等任务提供坚实的数据基础。其影响力体现在显著促进了如mT5等多语言Transformer模型的开发,提升了模型在低资源语言上的性能表现。
当前挑战
Wiki40B数据集所应对的领域挑战主要集中于多语言自然语言处理中的低资源语言建模与跨语言泛化能力提升。具体而言,如何确保40种语言间数据质量与规模的平衡,以支持模型在语言多样性下的有效学习,是一项核心难题。在构建过程中,挑战体现在对原始维基百科数据的精细化清洗,包括移除模板、引用及非文本元素,同时保留语义完整性;此外,处理不同语言的书写系统、语法结构差异以及数据量级的不均衡,亦需复杂的工程设计与语言学考量。这些挑战共同指向了构建标准化多语言语料库的内在复杂性。
常用场景
经典使用场景
在自然语言处理领域,大规模多语言文本数据是训练语言模型的基础资源。Wiki40B数据集以其覆盖40种语言的维基百科文本,成为跨语言预训练任务的经典选择。研究者常利用其丰富的语言多样性和结构化知识,构建能够理解多种语言上下文语义的深度神经网络模型,为机器翻译、跨语言信息检索等任务提供坚实的训练基础。
衍生相关工作
基于Wiki40B衍生的经典工作包括多语言BERT变体(如mBERT)的预训练优化,以及XLM-R等跨语言模型的性能验证研究。这些工作深入探索了语言间参数共享机制,推动了零样本跨语言迁移学习范式的成熟,后续研究进一步利用其数据构建了语言诊断探针、词汇对齐工具等创新方法体系。
数据集最近研究
最新研究方向
在自然语言处理领域,多语言预训练模型的兴起推动了跨语言知识获取与迁移学习的前沿探索。Wiki40B数据集凭借其涵盖40种语言的庞大文本资源,成为研究多语言表示对齐与低资源语言建模的关键语料库。当前研究热点聚焦于利用该数据集训练大规模多语言Transformer模型,以提升机器翻译、跨语言信息检索及零样本学习任务的性能。这些进展不仅促进了语言技术在全球范围内的普惠应用,也为构建更具包容性的人工智能系统奠定了数据基础,对推动语言多样性保护与数字平等具有深远意义。
以上内容由遇见数据集搜集并总结生成


