golden-fto-layer-a
收藏Hugging Face2026-05-08 更新2026-05-09 收录
下载链接:
https://huggingface.co/datasets/v13s/golden-fto-layer-a
下载链接
链接失效反馈官方服务:
资源简介:
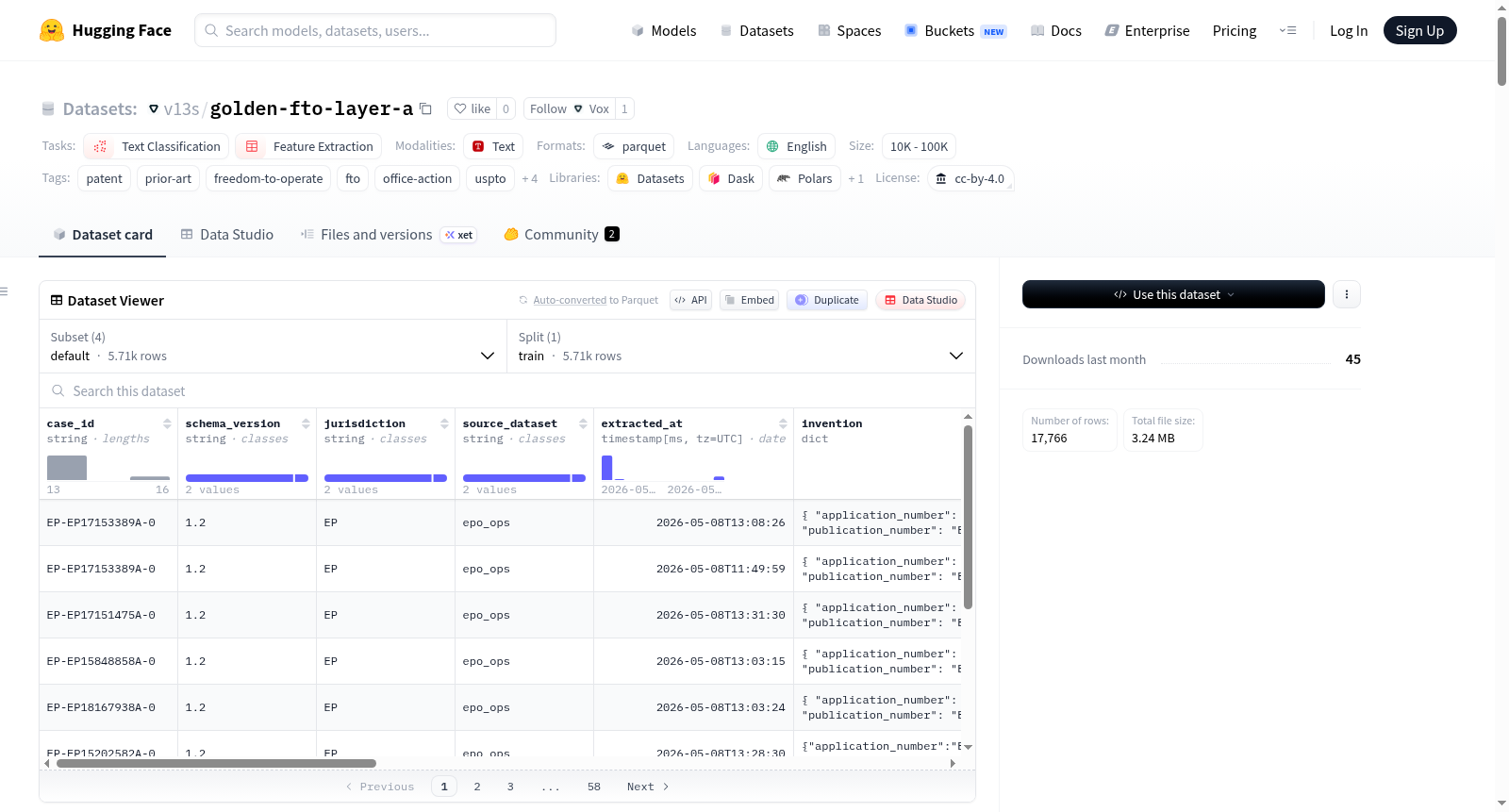
Layer A — Office Action Triples for FTO Evaluation 是一个公开数据集,包含从USPTO Office Action Research Dataset (OARD) 和EPO Open Patent Services (OPS) 中提取的 `(发明 → 引用的现有技术 → 结果)` 三元组。该数据集旨在为自由操作(FTO)评估提供基础,适用于专利分析、法律NLP等任务。数据集包含5,450行数据,其中5,000行来自美国专利局(USPTO)的2011-2017年申请,450行来自欧洲专利局(EPO)的2014-2020年申请。数据以Parquet格式存储,按管辖区域和申请年份分区。每个数据行包含案件ID、发明信息、审查信息、引用的现有技术列表、结果和来源信息。数据集还提供了跨引用索引,便于分析文档的引用频率。数据集遵循CC-BY-4.0许可,底层专利数据属于公共领域。
Layer A — Office Action Triples for FTO Evaluation is a public dataset containing triples of `(invention → cited prior art → outcome)` extracted from the USPTO Office Action Research Dataset (OARD) and EPO Open Patent Services (OPS). This dataset is designed to provide a foundation for Freedom to Operate (FTO) evaluation and is suitable for tasks such as patent analysis and legal NLP. The dataset consists of 5,450 rows of data, with 5,000 rows from USPTO applications from 2011-2017 and 450 rows from EPO applications from 2014-2020. The data is stored in Parquet format, partitioned by jurisdiction and application year. Each row includes case ID, invention information, examination information, a list of cited prior art, outcome, and source information. The dataset also provides a cross-citation index to facilitate analysis of document citation frequency. The dataset is licensed under CC-BY-4.0, with the underlying patent data in the public domain.
创建时间:
2026-05-01
原始信息汇总
数据集概述:Layer A — Office Action Triples for FTO Evaluation
基本信息
- 数据集名称: Layer A — Office Action Triples for FTO Evaluation
- 语言: 英语 (en)
- 许可证: CC-BY-4.0
- 数据集大小: 1K < n < 10K(具体为 5,450 行)
- 任务类别: 文本分类、特征提取
- 标签: patent, prior-art, freedom-to-operate, fto, office-action, uspto, epo, multi-jurisdiction, intellectual-property, legal-nlp
- 主页: https://huggingface.co/datasets/v13s/golden-fto-layer-a
数据集构成
- 总行数: 5,450 行(v1.2.20260508-r2 版本)
- 美国专利审查意见 (US): 5,000 行,申请年份 2011–2017
- 欧洲专利检索报告 (EP): 450 行,申请年份 2014–2020,按 IPC 分类在 23 个桶中分层抽样
- 数据格式: 22 个 Parquet 分片,按
jurisdiction × filing_year分区,另有prior_art_index/<jurisdiction>/兄弟分区(v1.2+)
配置选项
该数据集提供多个配置项,可通过 load_dataset() 加载:
- default: 返回两个司法管辖区的全部数据(5,450 行)
- us: 仅美国数据(5,000 行)
- ep: 仅欧洲数据(450 行)
- prior_art_index: 用于跨引文聚合的索引分区(v1.2+)
数据模式 (Schema)
每行代表一个专利审查意见事件及其引用的现有技术。主要字段包括:
| 字段 | 类型 | 描述 |
|---|---|---|
case_id |
string | 稳定 ID:<司法管辖区>-<申请号>-<审查意见序列> |
schema_version |
string | 行级模式版本(1.0 旧版 / 1.2 新版) |
jurisdiction |
string | US 或 EP |
source_dataset |
string | uspto_oard(美国)或 epo_ops(欧洲) |
extracted_at |
timestamp[s, UTC] | 数据提取时间 |
invention |
struct | 发明元数据:标题、摘要、IPC/CPC 代码、权利要求、申请人 |
examination |
struct | 审查意见事件:日期、类型(rejection/allowance/search_report)、驳回理由、审查员 ID |
prior_art |
list<struct> | 引用的现有技术:参考文献 ID、类型、来源、驳回依据、影响权利要求、严重性、分类(v1.2+)、元数据 |
outcome |
struct | 最终处置结果:最终处置类型、日期、授权权利要求、修改内容、决策来源 |
provenance |
struct | 审计追踪:解析器版本、源文件、SHA-256 校验、验证状态及备注 |
严重性枚举 (prior_art[].severity)
跨司法管辖区的三级严重性分类:
| 严重性 | 美国 (OARD 信号) | 欧洲 (WIPO ST.14 检索报告分类) |
|---|---|---|
novelty_destroying |
rejection_102=1 且 citation_in_oa=1 |
X 或 E(含多字符组合如 XY, XYI) |
obviousness |
rejection_103=1 且 citation_in_oa=1 |
Y |
background |
其他情况 (PTO-892, PTO-1449 IDS) | A, P, D, T, L, O, I |
prior_art[].categories (v1.2+)
v1.2 新增字段,保留多字符 ST.14 分类代码的完整集合,例如 XY 被拆分为 ["X", "Y"]。
跨引文索引 (v1.2+)
prior_art_index 兄弟分区按 (ref_id, citing_jurisdiction) 聚合,提供以下字段:
ref_id: 被引文献 IDciting_jurisdiction: 引用审查员所在司法管辖区citation_count: 引用次数citing_case_ids: 引用该文献的案例 ID 列表severity_distribution: 各严重性等级的计数分布first_cited_date/last_cited_date: 最早 / 最晚引用日期
数据构建方法
美国部分 (5,000 行)
- 从 USPTO Office Action Research Dataset (OARD) 下载批量数据,筛选前 5,000 个唯一申请 ID
- 保留这些申请对应的引文行(约 50 MB)
- 通过 USPTO ODP API 丰富元数据(每分钟 60 次速率限制)
- 利用 OARD 预分类的
rejection_*布尔列 + 引文行 + ODP 元数据构建三元组
欧洲部分 (450 行)
- 通过 EPO OPS 服务进行 IPC 分层自动筛选(23 个 IPC/年份范围桶)
- 质量门槛:至少 1 条检索阶段引用且至少 3 条权利要求文本记录
- 通过 OPS published-data 获取书目信息和权利要求
- 通过 OPS Register 服务 获取检索报告引文(含 WIPO ST.14 分类代码)
- 两端点合并构建三元组,保留高信号的 X/Y/A 子集
共同步骤
- 验证:时间合理性、严重性一致性、模式往返测试
- 按
jurisdiction × filing_year分区输出 Parquet 文件 - 生成 SHA-256 清单确保字节级可重复性
- 推送到 HuggingFace
已知限制
- 样本量: 仅 5,450 行,计划扩展至 50,000+ 行
- 欧洲
/claims413 问题: 长权利要求列表的出版物被丢弃,导致欧洲部分偏向制药/机械/控制 IPC - 稀疏权利要求文本: 部分美国行的
invention.claims = [] - 日本数据尚未发布: 依赖 INPIT 批量数据凭证审批
- 美国
prior_art_index尚未填充: 仅在 v1.2 的欧洲索引中存在 - 欧洲 outcome 字段保守:
final_disposition默认为pending - 模式版本混合: v1.0 行有空的
categories[],v1.2+ 行则填充
版本管理
采用语义化版本控制:
- MAJOR: 模式不兼容变更
- MINOR: 新字段、新司法管辖区、数据增长 ≥10%
- PATCH: 解析器 bug 修复、单案例重新验证
引用信息
bibtex @dataset{vox_layer_a_2026, author = {Hara, Yoichiro and {Vox}}, title = {Layer A — Office Action Triples for Freedom-to-Operate Evaluation}, year = 2026, publisher = {Hugging Face}, version = {{1.2.20260508-r2}}, url = {https://huggingface.co/datasets/v13s/golden-fto-layer-a}, note = {Curated under CC-BY-4.0; underlying patent data in the public domain} }
许可信息
- 策展层(本数据集): CC-BY-4.0
- 底层专利文件: 公共领域(USPTO)
- OARD 源数据: 公共领域(USPTO 首席经济学家办公室)
搜集汇总
数据集介绍
构建方式
该数据集基于USPTO Office Action Research Dataset与USPTO Open Data Portal API构建美国部分,并借助EPO Open Patent Services Register服务提取欧洲专利局审查意见,形成涵盖5000件美国审查意见(2011-2017年申请)与450件欧洲检索报告(2014-2020年申请)的黄金标准数据集。构建流程包括:对OARD海量数据进行应用ID筛选与引用行过滤,经USPTO ODP API富化元数据,将审查结论、引用信息和审查结果整合为(发明→引证现有技术→审查结果)三元组结构。欧洲部分则通过IPC分层自动策展,结合OPS数据库的全文引用和Register服务中携带WIPO ST.14分类码的检索报告,经双端点合并构建同质化的三元组。两套流程均经过时序合理性、严重程度一致性与模式往返的验证后,以Parquet格式按管辖区域与申请年份分区存储。
特点
该数据集的显著特征在于其三元组结构,每一行对应一个审查意见事件,同时关联所引用的现有技术文献及其审查结果。引入的三等级严重程度枚举机制(新颖性破坏、显而易觉性、背景技术),能够统一跨越US与EP两个管辖区域的引用信号。v1.2版本新增的多类别categories字段,保留WIPO ST.14多字符编码的全部信息,突破了传统单字符串严重程度标记的信息损失限制。同时包含跨引用索引分区,允许用户高效查询任一文献的引用频率与分布。数据集的每行皆携带详尽的采样时间戳、模式版本号及完整验证追溯,支持字节级别的可复现性验证。
使用方法
数据集可通过HuggingFace Datasets库便捷加载,默认配置返回全部5450条数据的训练集,亦支持按管辖区域分别加载US或EP子集。使用者可以直接访问每行的case_id、invention、examination、prior_art和outcome等结构字段。对于欧洲子集,可利用categories字段筛选多类别引用文献,通过判断是否同时包含X与Y标记来识别同时涉及新颖性与创造性问题的现有技术。跨引用索引可借助prior_art_index配置直接查询文献被引次数与分布,无需遍历全量数据。数据集内置语义化版本管理,用户可通过revision参数锁定特定版本,确保实验的可复现性与结果的可比性。
背景与挑战
背景概述
在知识产权与法律自然语言处理交叉领域,自由实施(Freedom-to-Operate, FTO)分析是评估一项发明能否在不侵犯他人专利权的前提下进行商业化的关键环节。然而,传统FTO检索高度依赖专家经验,且缺乏标准化评估基准。2026年,由Vox团队(主理人Yoichiro Hara)基于USPTO Office Action Research Dataset与EPO Open Patent Services构建的golden-fto-layer-a数据集应运而生。该数据集汇集了5450条来自美国和欧洲专利局的审查意见(Office Action)三元组,将发明、引用现有技术与审查结果有机联结,为AI驱动的FTO评估提供了首个公开、可复现的基准测试基座。数据集采用CC-BY-4.0许可协议,其分层严重性标注(novelty_destroying、obviousness、background)与跨法域模式对齐,显著推动了专利检索与法律推理领域可量化评价方法的进步。
当前挑战
该数据集面对的领域核心挑战在于,FTO分析在复杂专利法律框架下需同时处理多法域援引标准的不一致性(如美国35 USC §102/103与欧洲EPC第54/56条之间的判定差异),以及同一引用文献在不同法域中可能具备的多重法律属性(如ST.14编码XY同时指示新颖性和创造性问题)。数据集构建自身亦面临显著困难:USPTO ODP API的速率限制(60 RPM)导致US切片大规模扩展耗时;EPO OPS /claims端点的413负载限制使得长权利要求文献被迫排除,造成EP切片向医药/机械领域偏倚;JP切片的落地则受限于INPIT批量数据凭证的审批进度。此外,EP审查结果字段因缺乏法律状态端点联接而保守默认为‘pending’,完整结局需依赖额外的法律状态富化路径。
常用场景
经典使用场景
在知识产权与法律自然语言处理领域,golden-fto-layer-a 数据集被广泛用于评估和训练专利自由实施分析(Freedom-to-Operate, FTO)的智能代理系统。该数据集以结构化的三元组形式(发明→引用现有技术→审查结果)呈现了来自美国和欧洲专利局的审查意见通知与检索报告,为模型提供了丰富的监督信号,使其能够学习根据不同辖区的审查标准判断专利性风险。研究者常利用该数据集构建检索增强生成(RAG)管道或分类器,以自动识别引用文献的新颖性破坏性或显而易见性等级,从而模拟专利审查员的决策逻辑。其分层架构和跨辖区对齐的严重性标注(如 novelty_destroying、obviousness)使得多任务学习与迁移学习实验成为可能,是法律AI领域评估模型在专利前案检索与风险预测能力上的基准金标准。
实际应用
在实际产业应用中,该数据集支撑着下一代 AI 驱动的专利风险管理平台,如 Parallax。企业知识产权团队可利用基于该数据集训练的模型,在研发早期自动扫描海量专利文献,快速识别可能阻碍产品商业化的高风险前案,从而大幅降低 FTO 分析的时间与金钱成本。专利代理机构可将其嵌入工作流,用于自动生成审查意见通知的初步响应草案,并预测专利授权的概率边界。对于初创企业与独立发明人,该数据集驱动的智能工具能够以低廉成本提供专业级的竞争态势情报,包括识别技术空白领域和评估防御性公开策略的有效性。此外,数据集中的跨引用索引分片(prior_art_index)还支持专利影响力分析,帮助投资机构和技术转移办公室识别高价值核心专利。
衍生相关工作
基于该数据集已涌现出一系列重要的衍生工作。在技术层面,研究者开发了跨辖区审查意见严重性映射的可复现管线(如 ST.14 多分类代码解析模块),并构建了法律时序知识图谱以追踪专利家族审查历程。在方法论层面,衍生出多种面向 FTO 评估的检索增强策略,包括基于引用网络图神经网络的动态前案排序模型,以及利用对比学习优化专利文本表示的方法。在系统架构层面,该数据集催生了 Parallax 平台的全链路数据管道,囊括 OARD 原始数据镜像、EPO OPS 端点自动化抽取、IPC 分层采样与质量门控等组件。此外,学术社群已发表对比不同预训练语言模型(如 Legal-BERT、Patent-BERT)在现有技术分类任务上表现的基准实验,并探讨了跨辖区专利法律术语对齐对模型泛化能力的影响。
以上内容由遇见数据集搜集并总结生成


