recogna-nlp/FakeRecogna
收藏Hugging Face2023-12-07 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/recogna-nlp/FakeRecogna
下载链接
链接失效反馈官方服务:
资源简介:
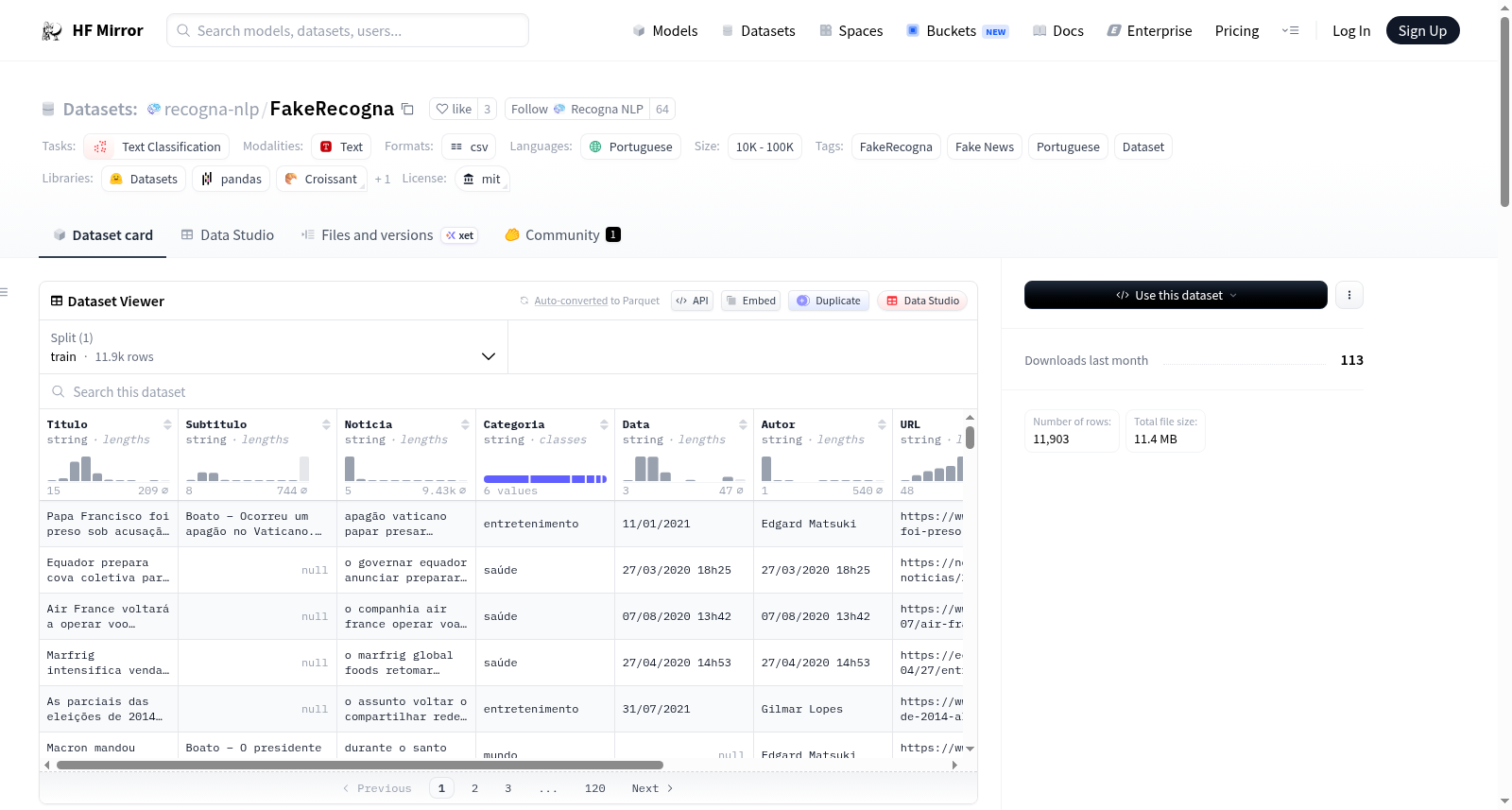
FakeRecogna数据集包含真实和虚假新闻,分别通过爬虫从知名新闻机构和事实核查机构收集。真实新闻主要来自巴西的可靠新闻门户,如G1、UOL和Extra,以及巴西卫生部的网页,共收集了超过100,000个样本,最终筛选出5,951个样本以保持类别平衡。虚假新闻主要来自全球事实核查机构,如Boatos.org、Fato ou Fake等,共收集了5,951个样本。数据集最终包含11,902个样本,分为六个类别:巴西、娱乐、健康、政治、科学和世界。每个样本包含标题、副标题、新闻内容、类别、作者、发布日期、URL和类别标签(0表示虚假新闻,1表示真实新闻)。
提供机构:
recogna-nlp
原始信息汇总
FakeRecogna 数据集
概述
FakeRecogna 是一个包含真实和虚假新闻的数据集。该数据集通过爬虫从知名且具有国家重要性的新闻机构页面中收集新闻,确保真实新闻与虚假新闻不直接关联,以避免分类偏差。数据集提供了丰富的多样性,适用于自然语言处理分析和机器学习算法。
数据收集
- 虚假新闻:主要从 Duke Reporters Lab 提供的页面中收集,该机构提供全球新闻真实性验证页面列表。2019年全球有160个活跃的事实核查机构,巴西有9个相关页面,其中6个页面被用于收集虚假新闻,共收集了5,951条样本。
- 真实新闻:从 G1、UOL、Extra 等公认可靠的新闻门户以及 巴西卫生部 主页中收集,共收集了超过100,000条样本。经过筛选,保留了5,951条样本以保持类别平衡,最终数据集包含11,902条样本。
数据结构
数据集以单个 XLSX 文件形式提供,包含8列元数据,每行代表一个样本(真实或虚假新闻),具体如下:
- Title:文章标题
- Sub-title (if available):新闻简要描述
- News:文章信息
- Category:根据信息对新闻进行分类
- Author:出版作者
- Date:出版日期
- URL:文章网页地址
- Class:0表示虚假新闻,1表示真实新闻
新闻类别分布
收集的文本根据主要主题分为六个类别:巴西、娱乐、健康、政治、科学和世界。这些类别是根据新闻提取的期刊部分定义的。具体分布如下:
- Brazil:904条,占比7.6%
- Entertainment:1,409条,占比12.00%
- Health:4,456条,占比37.4%
- Politics:3,951条,占比33.1%
- Science:602条,占比5.1%
- World:580条,占比4.9%
- Total:11,902条,占比100.00%
引用
plaintext @InProceedings{garcia2022fakerecogna, author="Garcia, Gabriel L and Afonso, Luis CS and Papa, Jo{~a}o P}", title="Fakerecogna: A new brazilian corpus for fake news detection", booktitle="International Conference on Computational Processing of the Portuguese Language", year="2022", publisher="Springer International Publishing", address="Cham", pages="57--67", isbn="978-3-030-98305-5"}
搜集汇总
数据集介绍
背景与挑战
背景概述
FakeRecogna是一个用于假新闻检测的巴西语数据集,包含约11,902条新闻样本,平衡采集自真实新闻源和事实核查机构,涵盖健康、政治等六个类别。该数据集以CSV格式提供,适用于文本分类任务,旨在支持自然语言处理和机器学习算法在虚假信息识别中的应用。
以上内容由遇见数据集搜集并总结生成


