apple/DataCompDR-12M
收藏Hugging Face2025-06-04 更新2024-06-12 收录
下载链接:
https://hf-mirror.com/datasets/apple/DataCompDR-12M
下载链接
链接失效反馈官方服务:
资源简介:
DataCompDR-12M是一个图像-文本数据集,是DataComp数据集的增强版。通过多模态数据集强化策略,我们生成了DataCompDR-1B和DataCompDR-12M,分别强化了DataComp-1B(BestPool过滤)和12.8M样本的均匀子集。我们使用OpenCLIP中的`coca_ViT-L-14`模型为每张图像生成5个合成标题,并进行强随机图像增强(DataCompDR-1B为10次,DataCompDR-12M为30次)。我们计算了两个强教师模型(`ViT-L-14`和OpenCLIP中的openai)在增强图像以及真实和合成标题上的嵌入。嵌入是1536维的,由2x768维向量连接而成。DataCompDR中的一个样本是一个随机增强的图像、一个真实标题和一个随机选取的合成标题的三元组。
DataCompDR-12M是一个图像-文本数据集,是DataComp数据集的增强版。通过多模态数据集强化策略,我们生成了DataCompDR-1B和DataCompDR-12M,分别强化了DataComp-1B(BestPool过滤)和12.8M样本的均匀子集。我们使用OpenCLIP中的`coca_ViT-L-14`模型为每张图像生成5个合成标题,并进行强随机图像增强(DataCompDR-1B为10次,DataCompDR-12M为30次)。我们计算了两个强教师模型(`ViT-L-14`和OpenCLIP中的openai)在增强图像以及真实和合成标题上的嵌入。嵌入是1536维的,由2x768维向量连接而成。DataCompDR中的一个样本是一个随机增强的图像、一个真实标题和一个随机选取的合成标题的三元组。
提供机构:
apple
原始信息汇总
数据集概述
数据集名称: DataCompDR-12M
数据集描述: DataCompDR-12M是一个增强版的图像-文本数据集,通过对原始DataComp数据集进行多模态数据增强策略的强化而创建。该数据集包含合成标题、嵌入和元数据,用于训练和评估图像-文本相关的模型。
数据集特点:
- 合成标题生成: 每张图像生成5个合成标题,使用
coca_ViT-L-14模型。 - 图像增强: 对图像进行强随机增强,DataCompDR-12M中每张图像进行30次增强。
- 嵌入计算: 使用两个强教师模型(
ViT-L-14与datacomp_xl_s13b_b90k和openai预训练权重)计算增强图像、真实和合成标题的嵌入。 - 嵌入维度: 1536维,由2个768维向量串联而成。
数据集结构:
- url.txt: 图像URL(字符串)
- syn.json: 合成文本列表(列表[字符串])
- paug.json: 增强参数列表(列表[列表[联合[整数,浮点数]]])
- npz: 图像和文本嵌入列表(列表[列表[浮点数]])
- json: 图像-文本样本的UID和SHA256哈希(字符串)
许可证: 自定义Apple许可证
语言: 英语
任务类别: 文本到图像、图像到文本
数据集使用
训练效果:
- 使用DataCompDR-12M进行训练,在单节点8×A100 GPU配置下,一天内可达到61.7%的零样本分类准确率。
- 与标准CLIP训练相比,DataCompDR显示出显著的学习效率提升。
引用信息
bibtex @InProceedings{mobileclip2024, author = {Pavan Kumar Anasosalu Vasu, Hadi Pouransari, Fartash Faghri, Raviteja Vemulapalli, Oncel Tuzel}, title = {MobileCLIP: Fast Image-Text Models through Multi-Modal Reinforced Training}, booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, month = {June}, year = {2024}, }
搜集汇总
数据集介绍
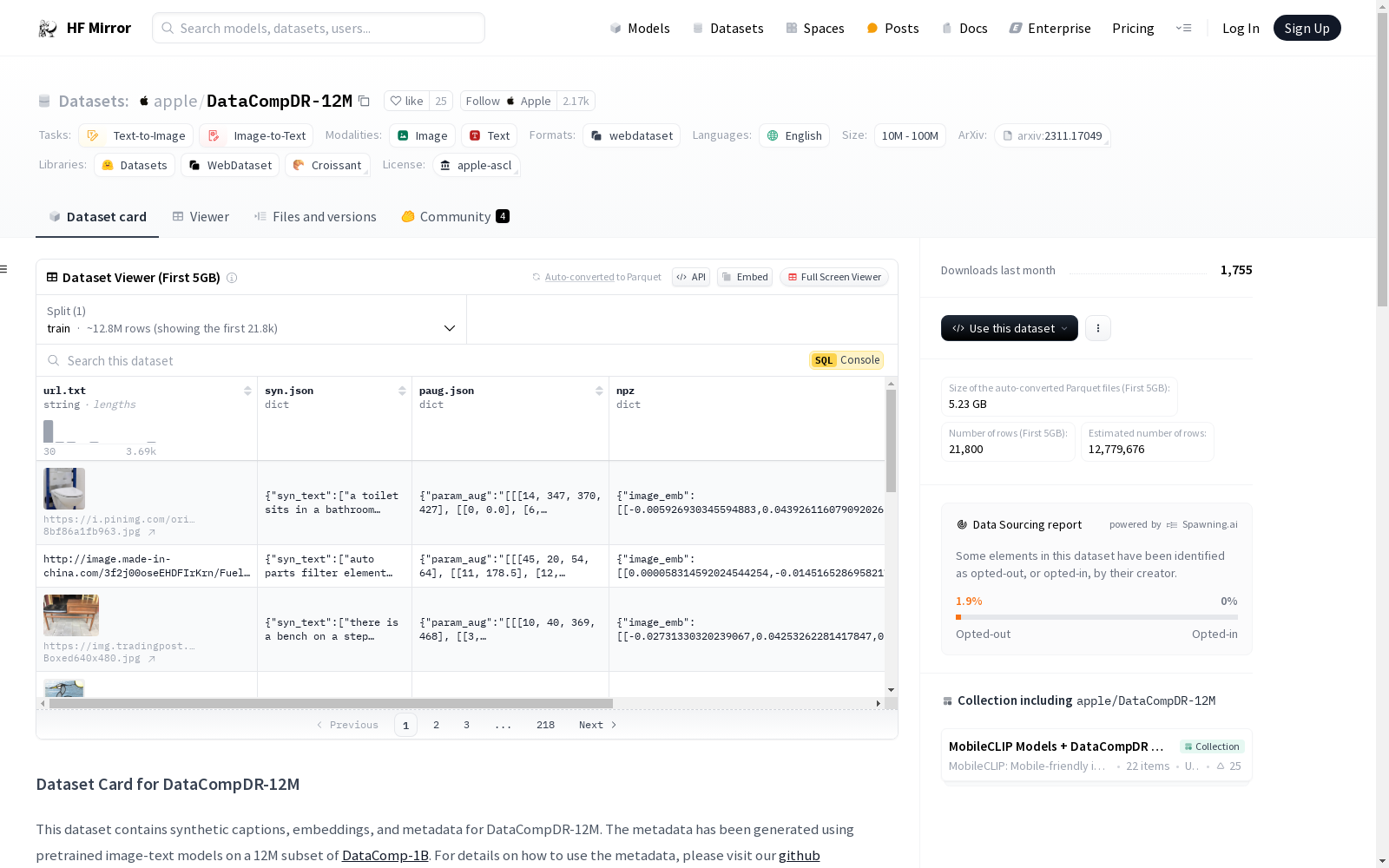
构建方式
DataCompDR-12M数据集通过多模态数据增强策略对DataComp-1B数据集进行了强化,构建了一个包含12.8M样本的子集。该数据集的构建过程包括使用OpenCLIP中的`coca_ViT-L-14`模型为每张图像生成5个合成描述,并应用强随机图像增强(30次增强)。此外,通过两个强大的教师模型(`ViT-L-14`)计算增强图像和真实/合成描述的嵌入,嵌入结果为1536维的向量,由2x768维向量拼接而成。
特点
DataCompDR-12M数据集的主要特点在于其多模态数据的丰富性和高效性。每条样本包含一个随机增强的图像、一个真实描述和一个随机选择的合成描述,形成了一个三元组。这种结构不仅增强了数据的多样性,还显著提升了训练效率。此外,数据集的嵌入计算采用了高效的模型集成方法,确保了嵌入的高质量和计算的经济性。
使用方法
DataCompDR-12M数据集适用于图像与文本的多模态任务,如图像描述生成和文本到图像的检索。用户可以通过访问数据集的GitHub仓库获取详细的使用指南,并利用提供的嵌入和合成描述进行模型训练。在训练过程中,数据集展示了显著的学习效率提升,尤其在使用ViT-B/16模型进行CLIP训练时,能够在短时间内达到较高的零样本分类性能。
背景与挑战
背景概述
DataCompDR-12M数据集是由Apple公司基于DataComp-1B数据集进行增强和扩展而创建的,旨在提升多模态学习的效率。该数据集通过使用预训练的图像-文本模型,生成了12M样本的合成描述和嵌入,进一步强化了原始DataComp数据集。主要研究人员包括Pavan Kumar Anasosalu Vasu、Hadi Pouransari等,其研究成果已在2024年CVPR会议上发表。该数据集的核心研究问题是如何通过多模态数据增强策略,提升图像与文本联合训练的效率,并在多个基准测试中取得了显著的性能提升。
当前挑战
DataCompDR-12M数据集在构建过程中面临多项挑战。首先,生成高质量的合成描述和嵌入需要复杂的预训练模型和计算资源,尤其是在处理大规模数据时,计算成本和时间消耗巨大。其次,数据增强策略的多样性和有效性需要经过广泛的实验验证,以确保在不同模型架构下的泛化能力。此外,如何确保合成数据与真实数据的无缝集成,避免引入噪声或偏差,也是该数据集面临的重要挑战。最后,数据集的版权和使用许可问题,尤其是涉及大量图像和文本的版权归属,需要谨慎处理以确保合法合规。
常用场景
经典使用场景
DataCompDR-12M 数据集在多模态学习领域中具有广泛的应用,尤其在图像与文本的联合表示学习中表现突出。该数据集通过增强的图像和合成文本描述,提供了丰富的嵌入信息,使得模型能够在图像与文本之间建立更精确的关联。典型的使用场景包括图像检索、文本生成图像以及多模态模型的预训练,这些任务均依赖于高质量的图像与文本对齐数据。
解决学术问题
DataCompDR-12M 数据集解决了多模态学习中数据增强和效率提升的关键问题。通过引入合成文本和图像增强技术,该数据集显著提高了模型训练的效率,减少了训练时间和计算资源的消耗。此外,它还为研究者提供了一个标准化的基准,用于评估和比较不同多模态模型的性能,推动了该领域的技术进步。
衍生相关工作
DataCompDR-12M 数据集的发布催生了一系列相关的经典工作,特别是在多模态学习和图像-文本对齐领域。例如,基于该数据集的研究工作提出了多种改进的多模态模型架构,如MobileCLIP,这些模型在多个基准测试中取得了领先的成绩。此外,该数据集还激发了关于数据增强和合成数据生成方法的研究,进一步推动了多模态学习技术的发展。
以上内容由遇见数据集搜集并总结生成


