TW-GSAT-Chinese
收藏Hugging Face2025-07-24 更新2025-07-25 收录
下载链接:
https://huggingface.co/datasets/TsukiOwO/TW-GSAT-Chinese
下载链接
链接失效反馈官方服务:
资源简介:
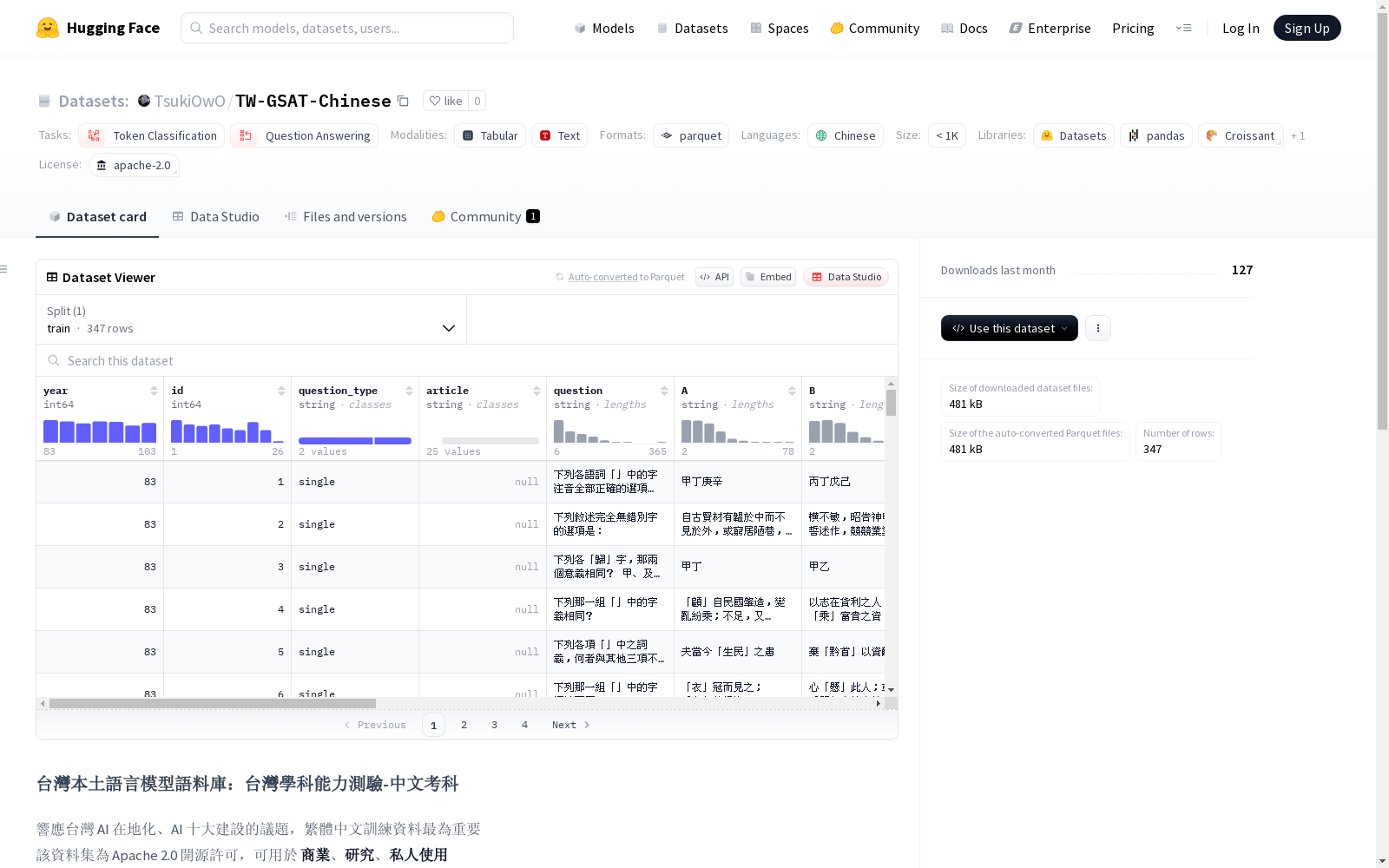
该数据集是一个台湾学科能力测验的中文考科资料库,包含了考试题目和相关内容,适用于自然语言处理任务如token分类和问题回答。数据集以纯文本形式存在,没有图片,便于训练。所有信息都包含在'text_pre_format'字段中,可直接用于预训练。同时,数据集还提供了适用于TW-TextForge工具的格式。数据集遵循Apache 2.0开源许可,可用于商业、研究和私人使用。
创建时间:
2025-07-24
原始信息汇总
台灣本土語言模型語料庫:台灣學科能力測驗-中文考科
基本資訊
- 許可證: Apache 2.0
- 語言: 繁體中文 (zh)
- 資料集大小: 778781 bytes
- 下載大小: 481068 bytes
- 樣本數量: 347
- 任務類別: 標記分類 (token-classification)、問答 (question-answering)
- 規模分類: n<1K
資料特徵
- 欄位:
- year (int64): 年份
- id (int64): 識別碼
- question_type (string): 問題類型
- article (string): 文章內容
- question (string): 問題
- A (string): 選項A
- B (string): 選項B
- C (string): 選項C
- D (string): 選項D
- E (string): 選項E
- grading_criteria (float64): 評分標準
- answer (string): 答案
- answer_rate (float64): 答對率
- text_pre_format (string): 預處理文本格式
- text_pre_tw_textforge_format (string): TW-TextForge專用格式
- references (string): 參考資料
資料集特色
- 純文字內容,無圖片,降低訓練難度。
text_pre_format包含所有資訊,可直接用於預訓練。text_pre_tw_textforge_format專用於TW-TextForge產生題目分析。
法律聲明
- 根據中華民國著作權法第9條,依法令舉行的考試試題不具著作權。
- 資料集已調整題目敘述,使其更適合NLP任務。
- 學測題目引用內容可能仍有著作權保護,本資料集不收集此類內容。
- 使用時需遵守Apache 2.0許可證。
搜集汇总
数据集介绍
构建方式
TW-GSAT-Chinese数据集基于台湾学科能力测验的中文考科试题构建,严格遵循中华民国著作权法相关规定,仅收录依法令举行的公开考试试题。数据采集过程中剔除了可能涉及第三方著作权的引用内容,并对原始题目进行了文本重构处理,使其更适配自然语言处理任务的需求。数据集构建团队特别注重法律合规性,通过Apache 2.0许可证明确授权商业、研究和私人用途。
特点
该数据集作为台湾本土语言模型的重要语料库,具有鲜明的区域性特征。所有试题均采用纯文本形式存储,避免了图像数据带来的处理复杂度。数据集提供两种预处理格式:text_pre_format包含完整的结构化信息,可直接用于模型预训练;text_pre_tw_textforge_format专为TW-TextForge工具链优化,支持深度题目分析。每条数据记录包含15个特征维度,涵盖试题年份、题型、文章内容、选项及答题统计等关键信息。
使用方法
研究人员可直接加载HuggingFace平台提供的标准格式数据,利用text_pre_format字段进行端到端的模型训练。对于特定分析需求,可结合TW-TextForge工具处理text_pre_tw_textforge_format字段,实现试题的语义解析和知识图谱构建。使用前需注意遵守Apache 2.0许可协议,商业应用时应自行验证试题引用内容的著作权状态。数据集适用于问答系统训练、语言理解评估及教育领域知识挖掘等多种NLP任务。
背景与挑战
背景概述
TW-GSAT-Chinese数据集是响应台湾AI在地化政策而构建的重要语料资源,专注于台湾学科能力测验中文考科的试题整理与分析。该数据集由开源社区在Apache 2.0许可下发布,旨在推动繁体中文自然语言处理技术的发展。其核心价值在于收录了依法不具著作权的标准化考试试题,通过结构化字段如题目文本、选项、标准答案及答题率等,为语言模型训练提供了高质量的领域特定语料。数据集的构建体现了对台湾教育体系评估标准的数字化转换,为研究中文阅读理解、试题生成等任务提供了基准测试平台。
当前挑战
该数据集面临双重技术挑战:在领域问题层面,中文试题的语义理解需处理文言文与现代汉语的混合表达,且多选题的干扰项设计增加了机器推理的复杂度;在构建过程中,需平衡法律合规性与数据完整性,既要规避引用内容的著作权风险,又要保持试题的语义连贯性。此外,原始试题的非结构化特性要求开发复杂的文本预处理流程,例如自动分离题干与选项、标准化异体字等,这些都对数据标注规范提出了较高要求。
常用场景
经典使用场景
TW-GSAT-Chinese数据集作为台湾学科能力测验中文考科的语料库,其经典使用场景主要集中在自然语言处理领域。该数据集通过提供丰富的多选题和文本材料,为研究者构建和评估阅读理解模型提供了理想的测试平台。特别是在繁体中文处理任务中,该数据集能够有效支持问答系统、文本理解和语言推理等核心NLP任务的开发与验证。
解决学术问题
该数据集解决了繁体中文自然语言处理研究中数据稀缺的关键问题。通过提供结构化的考试题目和标准答案,研究者能够系统性地探索中文语义理解、逻辑推理和知识提取等前沿课题。其包含的详细评分标准和答案分布,为模型性能评估提供了量化依据,显著提升了学术研究的可重复性和可比性。
衍生相关工作
围绕该数据集已衍生出多项重要研究工作,其中最典型的是TW-TextForge项目。该项目利用数据集的预处理格式进行题目深度分析,推动了台湾本土语言模型的发展。此外,基于该数据集的预训练方法研究也为繁体中文NLP领域贡献了新的技术路线,促进了AI在地化应用的创新突破。
以上内容由遇见数据集搜集并总结生成


