MMPR-v1.2-prompts
收藏Hugging Face2025-04-12 更新2025-04-13 收录
下载链接:
https://huggingface.co/datasets/OpenGVLab/MMPR-v1.2-prompts
下载链接
链接失效反馈官方服务:
资源简介:
MMPR-v1.2-prompts是一个大规模、高质量的用于多模态推理的偏好数据集。该数据集包含了大约300万个样本,用于构建MMPR-v1.2,显著提高了InternVL3在所有规模下的整体性能。数据集包括图像路径、输入查询、问题的选定响应和拒绝响应等字段。
提供机构:
OpenGVLab
创建时间:
2025-04-12
搜集汇总
数据集介绍
构建方式
在视觉问答领域,MMPR-v1.2-prompts数据集的构建采用了混合偏好优化(MPO)技术,通过精心设计的提示工程流程生成高质量的多模态推理偏好对。该数据集包含约300万样本,其构建过程涉及两个关键阶段:首先使用特定脚本采样推理轨迹,随后通过数据转换流程将其转化为具有选择偏好标记的问答对。技术文档中详细描述了基于正确性评估和dropout-NTP的两套数据生成管道,确保了数据在逻辑一致性和多样性上的平衡。
特点
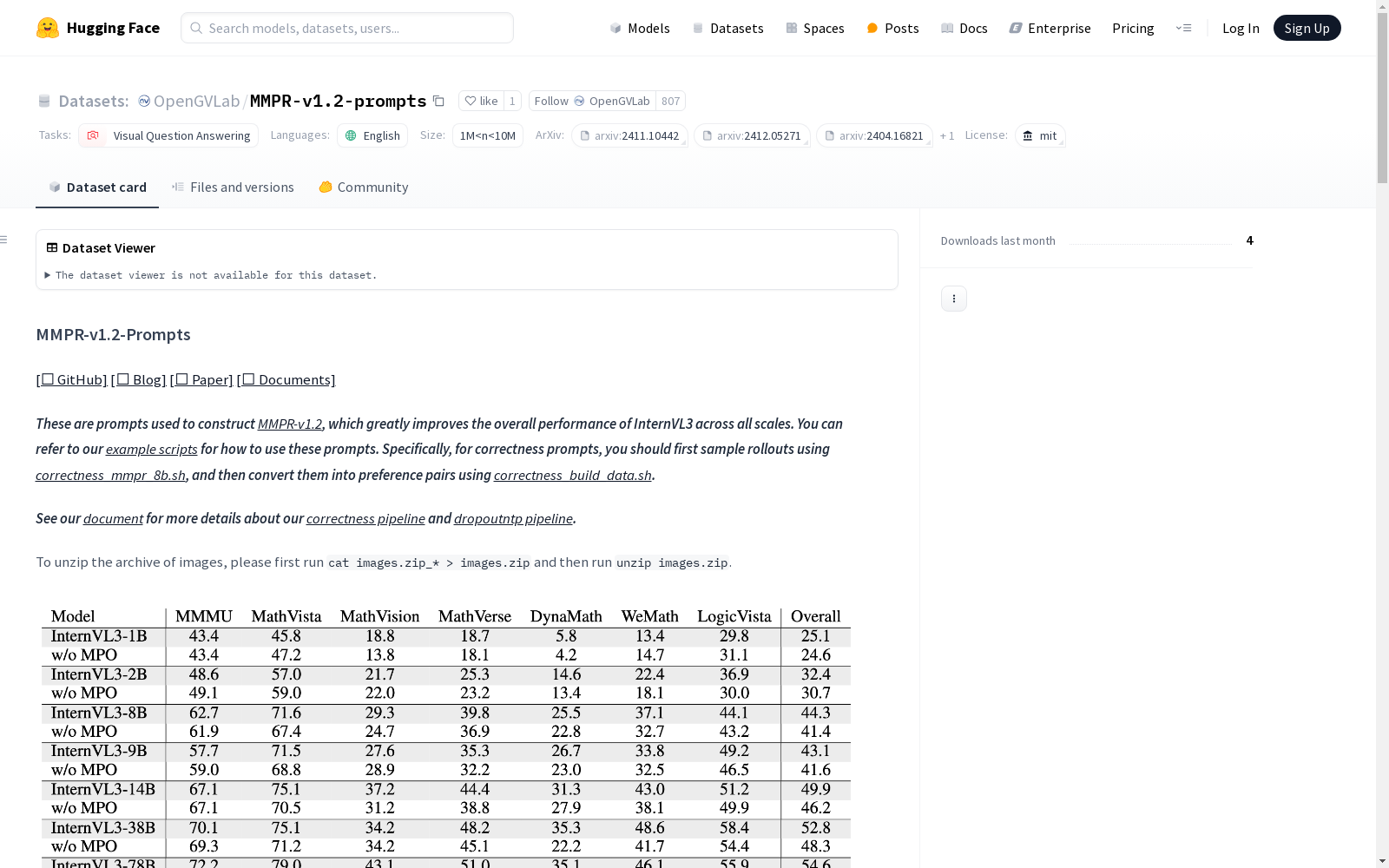
作为增强多模态大语言模型推理能力的核心数据集,MMPR-v1.2-prompts展现出三大显著特征:其样本规模达到百万级别,覆盖广泛的视觉推理场景;每个样本包含图像路径、问题文本及经过人工标注的优选/劣选回答对,为偏好学习提供明确监督信号;基准测试表明,基于该数据集训练的模型在MathVista等8项多模态推理基准上平均提升8.7个点,尤其在数学视觉任务中达到25.7%的准确率,验证了数据质量的优越性。
使用方法
该数据集需配合专用处理流程使用,用户需先通过GitHub提供的示例脚本完成数据解压与格式转换。具体而言,正确性提示需先运行correctness_mmpr_8b.sh生成推理轨迹,再通过correctness_build_data.sh转换为偏好对。技术文档详细阐述了数据管道的调用方式,包括图像数据的合并解压命令。数据集主要应用于多模态大模型的混合偏好优化训练,可显著提升模型在复杂视觉推理任务中的表现,相关使用方法已在InternVL2-8B-MPO等模型的训练中得到实证。
背景与挑战
背景概述
MMPR-v1.2-prompts数据集由OpenGVLab团队于2024年发布,旨在推动多模态推理领域的研究进展。该数据集作为MMPR-v1.2的基础构建模块,专门设计用于优化InternVL系列模型的混合偏好优化(MPO)过程。数据集包含约300万样本,涵盖视觉问答(VQA)任务中的图像、问题、优选回答及非优选回答等关键字段。其核心研究目标在于通过高质量的多模态偏好数据,提升模型在复杂推理任务中的表现,如MathVista和MathVision等基准测试。相关论文显示,基于该数据集训练的InternVL2-8B-MPO模型在MathVista测试中达到67.0%准确率,较基线模型提升8.7个百分点,显著缩小了与商业模型(如GPT-4o)的性能差距。
当前挑战
该数据集面临的挑战主要体现在两个维度:领域问题层面,多模态推理任务需同时处理视觉与语言模态的复杂关联,模型需克服语义鸿沟、幻觉生成及跨模态对齐等难题;数据构建层面,如何确保300万样本的标注质量与多样性成为关键挑战,包括优选/非优选回答的精准标注、图像-问题对的语义一致性维护,以及对抗性样本的筛选。此外,数据规模带来的存储与计算压力(1M<n<10M级别)也要求高效的分布式处理方案。
常用场景
经典使用场景
在视觉-语言多模态研究领域,MMPR-v1.2-prompts数据集为构建高质量的多模态推理偏好数据提供了重要支持。该数据集通过包含约300万样本,广泛应用于训练和优化多模态大语言模型,特别是在视觉问答(VQA)和数学推理任务中表现突出。研究人员利用该数据集生成的提示词,显著提升了模型在复杂视觉语言任务中的性能,例如在MathVista和MathVision等基准测试中取得了领先的准确率。
衍生相关工作
该数据集催生了一系列重要的研究工作,包括InternVL系列模型的持续优化。基于MMPR-v1.2-prompts开发的InternVL2-8B-MPO和InternVL2.5系列模型在多模态基准测试中均取得了突破性进展。相关研究论文系统地探讨了混合偏好优化方法,为后续多模态模型的研究提供了重要参考,推动了开源多模态模型向商业模型性能靠拢的进程。
数据集最近研究
最新研究方向
在视觉-语言多模态推理领域,MMPR-v1.2-prompts数据集正推动混合偏好优化(MPO)技术的突破性进展。该数据集通过构建约300万高质量样本,显著提升了InternVL系列模型在MathVista、MathVision等复杂推理任务中的表现,其中InternVL2-8B-MPO在MathVista测试集达到67.0%准确率,较基线提升8.7个百分点。当前研究聚焦于三个维度:一是探索多模态大语言模型中感知与推理能力的协同优化机制,二是开发更高效的偏好数据构建流水线(如correctness/dropoutntp pipeline),三是验证模型规模扩展与性能提升的量化关系。最新成果显示,MPO技术能使不同参数量的模型平均提升2个基准点,这为开源社区构建匹敌商业模型的多模态系统提供了关键技术路径。
以上内容由遇见数据集搜集并总结生成


