sequence
收藏Hugging Face2025-05-30 更新2025-05-31 收录
下载链接:
https://huggingface.co/datasets/deeponh/sequence
下载链接
链接失效反馈官方服务:
资源简介:
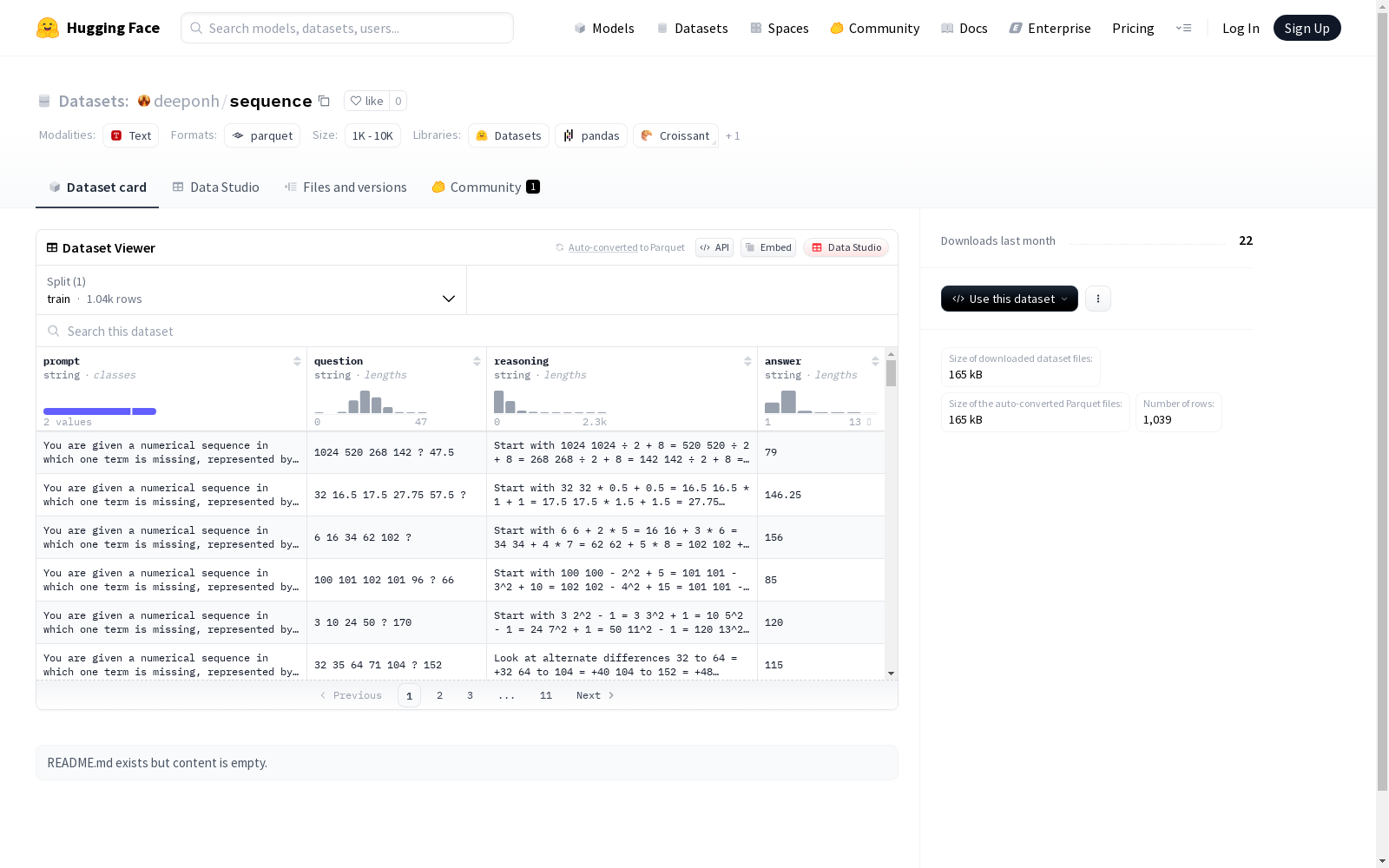
该数据集包含四个字段:提示(prompt)、问题(question)、推理过程(reasoning)和答案(answer)。数据集分为训练集,共有1039个示例。数据集的总大小为613890字节,下载大小为165225字节。
创建时间:
2025-05-23
原始信息汇总
数据集概述
基本信息
- 数据集名称: deeponh/sequence
- 下载大小: 165225字节
- 数据集大小: 613890字节
数据特征
- 特征列:
prompt: 字符串类型question: 字符串类型reasoning: 字符串类型answer: 字符串类型
数据分割
- 训练集:
- 样本数量: 1039
- 字节大小: 613890
配置信息
- 默认配置:
- 数据文件路径:
data/train-*
- 数据文件路径:
搜集汇总
数据集介绍
构建方式
在序列推理任务的数据构建过程中,该数据集通过精心设计的流程整合了1039个训练样本,每个样本包含提示、问题、推理过程和答案四个核心字段。构建时注重逻辑链条的完整性,确保从问题提出到答案生成的每一步推理都有清晰记录,数据以文本字符串形式存储,总规模约614KB,体现了对序列化思维过程的系统性捕捉。
特点
该数据集的核心特点在于其结构化特征,每个样本均包含prompt、question、reasoning和answer四个关键字段,形成完整的推理链条。数据以纯文本形式呈现,支持对序列化逻辑关系的深入分析,训练集规模适中且数据质量统一,为研究序列推理任务提供了高一致性的基础。
使用方法
使用该数据集时,可通过加载train分割路径直接访问训练数据,每个样本的四个字段可分别用于模型输入、问题解析、推理监督和答案验证。数据以标准文本格式存储,支持自然语言处理模型的端到端训练,特别适用于序列生成和逻辑推理任务的基准测试。
背景与挑战
背景概述
序列推理数据集旨在探索人工智能在逻辑推理与问题解决方面的能力边界。该数据集由研究团队于近年构建,聚焦于多步骤推理任务的建模,通过提供提示、问题、推理链条及标准答案的结构化数据,推动自然语言处理领域对复杂认知过程的理解。此类数据集通常服务于问答系统与推理模型的训练,为评估模型在序列化思维方面的表现提供了重要基准。
当前挑战
序列推理任务的核心挑战在于模型需模拟人类逐步推导的思维过程,避免逻辑跳跃或中间步骤错误。构建过程中,数据标注需确保推理链条的连贯性与正确性,同时平衡问题的多样性与难度分布。高质量的推理数据收集成本较高,且需解决自然语言表达歧义带来的标注一致性问题。
常用场景
经典使用场景
在序列推理任务的研究中,该数据集通过提供包含提示、问题、推理过程和答案的结构化样本,成为评估模型逻辑链条构建能力的经典基准。研究者通常利用其训练序列到序列模型,模拟人类逐步推理的模式,尤其在数学问题求解和常识推理领域展现显著价值。这种设计使得模型能够学习从问题到答案的中间推理步骤,提升了复杂问题处理的透明度和可解释性。
解决学术问题
该数据集主要针对人工智能领域中的可解释推理难题,通过显式标注的推理路径,为研究序列生成模型的逻辑一致性提供了关键资源。它有效缓解了黑箱模型决策过程不透明的学术痛点,促进了链式思维(Chain-of-Thought)方法的发展。这种结构化数据支撑了对推理错误根源的细粒度分析,推动了神经符号推理等交叉方向的理论突破。
衍生相关工作
基于该数据集的特性,学术界衍生出多项经典工作,例如结合强化学习的推理路径优化框架,以及融合外部知识库的混合推理模型。这些研究进一步拓展了多跳推理任务的边界,催生了如程序辅助生成(Program-Aided Generation)等创新方法。相关成果持续推动着预训练语言模型在复杂推理场景下的能力进化。
以上内容由遇见数据集搜集并总结生成


