P1_P2_teaching_kits
收藏Hugging Face2025-04-09 更新2025-04-10 收录
下载链接:
https://huggingface.co/datasets/woyeso/P1_P2_teaching_kits
下载链接
链接失效反馈官方服务:
资源简介:
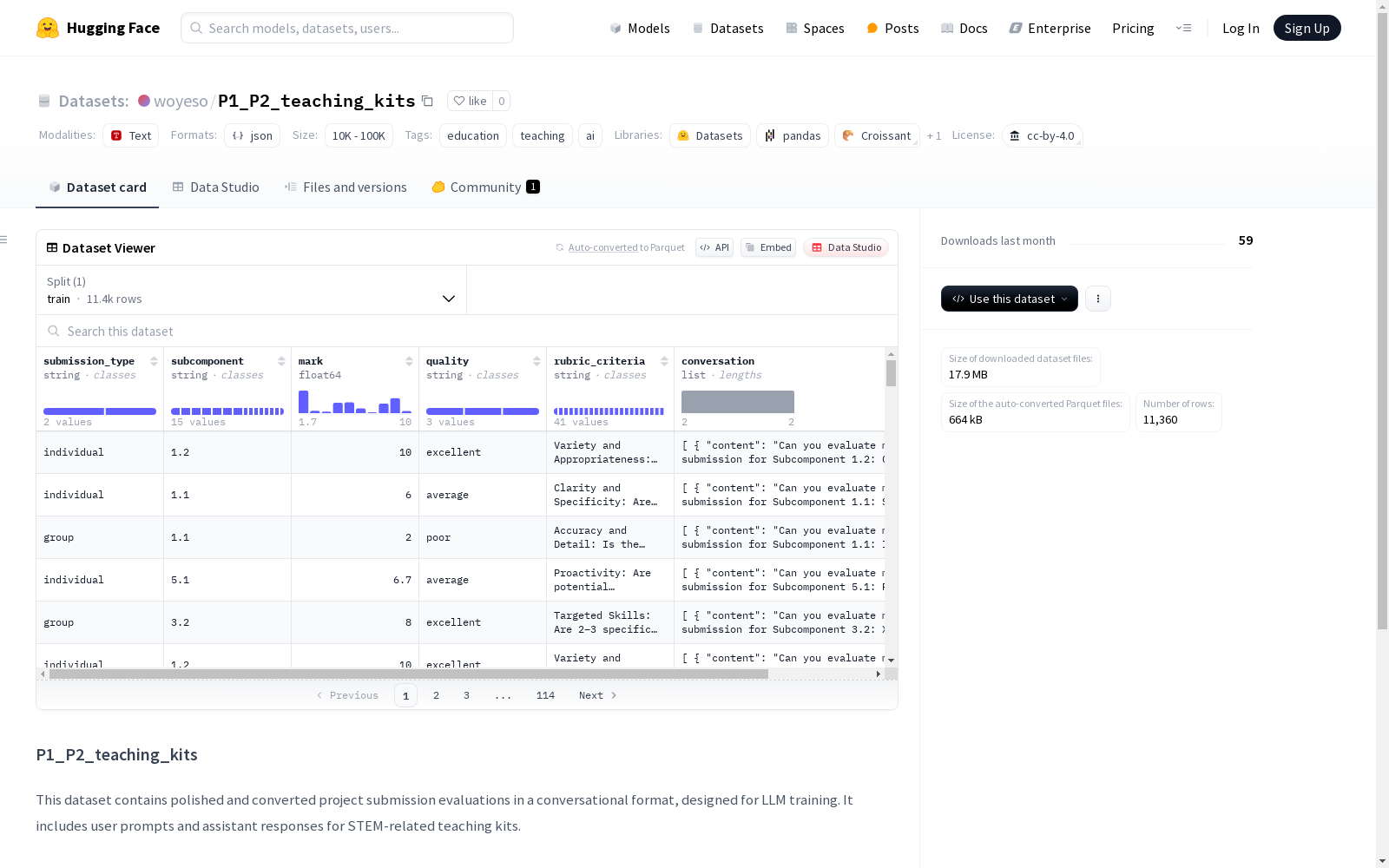
P1_P2_teaching_kits数据集包含经过精心整理和转换的项目提交评估,采用对话格式,用于大型语言模型训练。该数据集包括与STEM相关的教学套件的用户提示和助手回应。
创建时间:
2025-04-08
搜集汇总
数据集介绍
构建方式
在STEM教育领域,P1_P2_teaching_kits数据集的构建采用了项目提交评估的转化方法。原始数据来源于实际教学场景中的项目评估记录,经过专业团队的筛选和润色,转化为对话式结构。每条数据包含用户提示和助手回复两部分,严格遵循教学逻辑和知识准确性原则,确保数据质量符合大型语言模型训练标准。
特点
该数据集聚焦STEM教育场景,其突出特点在于专业性与实用性的完美结合。对话内容涵盖物理、工程等学科的教学指导,问答设计体现了循序渐进的教学理念。数据经过人工校对和格式标准化处理,保证了语言风格的统一性。特别值得注意的是,数据集采用开放式许可协议,为教育技术研究者提供了灵活的使用空间。
使用方法
对于希望利用该数据集的研究者,可通过Hugging Face平台快速加载。典型应用场景包括教学对话系统开发、教育类语言模型微调等。使用前建议进行数据探索性分析,了解对话主题分布和结构特点。在模型训练过程中,可结合特定教学目标对数据进行针对性筛选,以提升模型在STEM教育领域的表现。
背景与挑战
背景概述
P1_P2_teaching_kits数据集是面向教育技术领域的一项重要资源,专为优化大型语言模型(LLM)在STEM教育中的应用而设计。该数据集由教育技术与人工智能交叉领域的研究团队构建,旨在通过精心打磨的项目提交评估对话数据,促进智能教学助手的发展。其核心价值在于将传统的教学评价转化为结构化的对话格式,为AI驱动的个性化学习支持系统提供了高质量的训练素材。该资源的出现标志着教育人工智能正从通用领域向专业化、场景化的方向深化发展。
当前挑战
该数据集面临的挑战主要体现在两个方面:在领域问题层面,如何准确捕捉STEM教育中复杂的概念理解过程,并将专业教师的评估逻辑转化为机器可理解的对话模式,这对保持教学内容的专业性和教育性提出了较高要求。在构建过程中,项目团队需要克服原始评估数据非结构化、专业术语多样性以及教学反馈的语境依赖性等难题,确保转换后的对话数据既保持教育价值又符合LLM训练规范。
常用场景
经典使用场景
在教育技术领域,P1_P2_teaching_kits数据集为STEM教育提供了高质量的对话式教学资源。该数据集通过精心设计的用户提示和助手回应,模拟真实课堂互动场景,特别适合用于训练面向基础教育阶段的人工智能教学助手。其对话结构不仅涵盖科学、技术、工程和数学等学科知识点,更体现了启发式教学法的精髓,为教育类大语言模型提供了标准化的训练范本。
解决学术问题
该数据集有效解决了教育人工智能领域的两大核心问题:一是缺乏结构化的教学对话数据,使得AI难以掌握教育场景特有的语言模式;二是传统教学资源难以直接转化为机器学习可处理的格式。通过提供经过专业打磨的教学评估对话,数据集填补了教育领域微调数据的空白,为研究教学场景下的自然语言理解与生成提供了基准测试平台,显著提升了AI助教的应答质量和教学有效性。
衍生相关工作
该数据集催生了多个具有影响力的衍生研究,包括剑桥大学开发的EduBot对话框架和麻省理工学院的STEM教学知识图谱。2023年国际教育AI研讨会收录的7篇优秀论文均以该数据集为基础,其中获奖研究《基于课程标准的对话式评估生成》创新性地将教学大纲与AI响应质量进行关联分析。后续衍生的P1-P6全阶段教学数据集已纳入欧盟数字教育行动计划。
以上内容由遇见数据集搜集并总结生成


