COMPBENCH
收藏arXiv2024-07-24 更新2024-07-26 收录
下载链接:
https://compbench.github.io
下载链接
链接失效反馈官方服务:
资源简介:
COMPBENCH是由俄亥俄州立大学创建的一个多模态比较推理基准数据集,旨在评估大型语言模型在图像比较方面的能力。该数据集包含约39,800个图像对,涵盖动物、时尚、体育等多个视觉领域,通过视觉导向的问题覆盖八个相对比较维度。数据集的创建过程结合了人工标注和计算机辅助,确保问题和答案的准确性与相关性。COMPBENCH主要用于评估和提升多模态大型语言模型在实际应用中的比较推理能力,特别是在日常决策和问题解决中的应用。
COMPBENCH is a multimodal comparative reasoning benchmark dataset developed by The Ohio State University, aiming to evaluate the comparative reasoning capabilities of large language models (LLMs) when performing image comparison tasks. This dataset contains approximately 39,800 image pairs spanning multiple visual domains including animals, fashion, sports and other categories, and covers eight comparative dimensions through vision-guided questions. The creation of COMPBENCH combines manual annotation and computer-aided processes to ensure the accuracy and relevance of both the questions and their corresponding answers. Primarily, COMPBENCH is intended to evaluate and enhance the comparative reasoning abilities of multimodal large language models in real-world applications, particularly for daily decision-making and problem-solving scenarios.
提供机构:
俄亥俄州立大学
创建时间:
2024-07-24
搜集汇总
数据集介绍
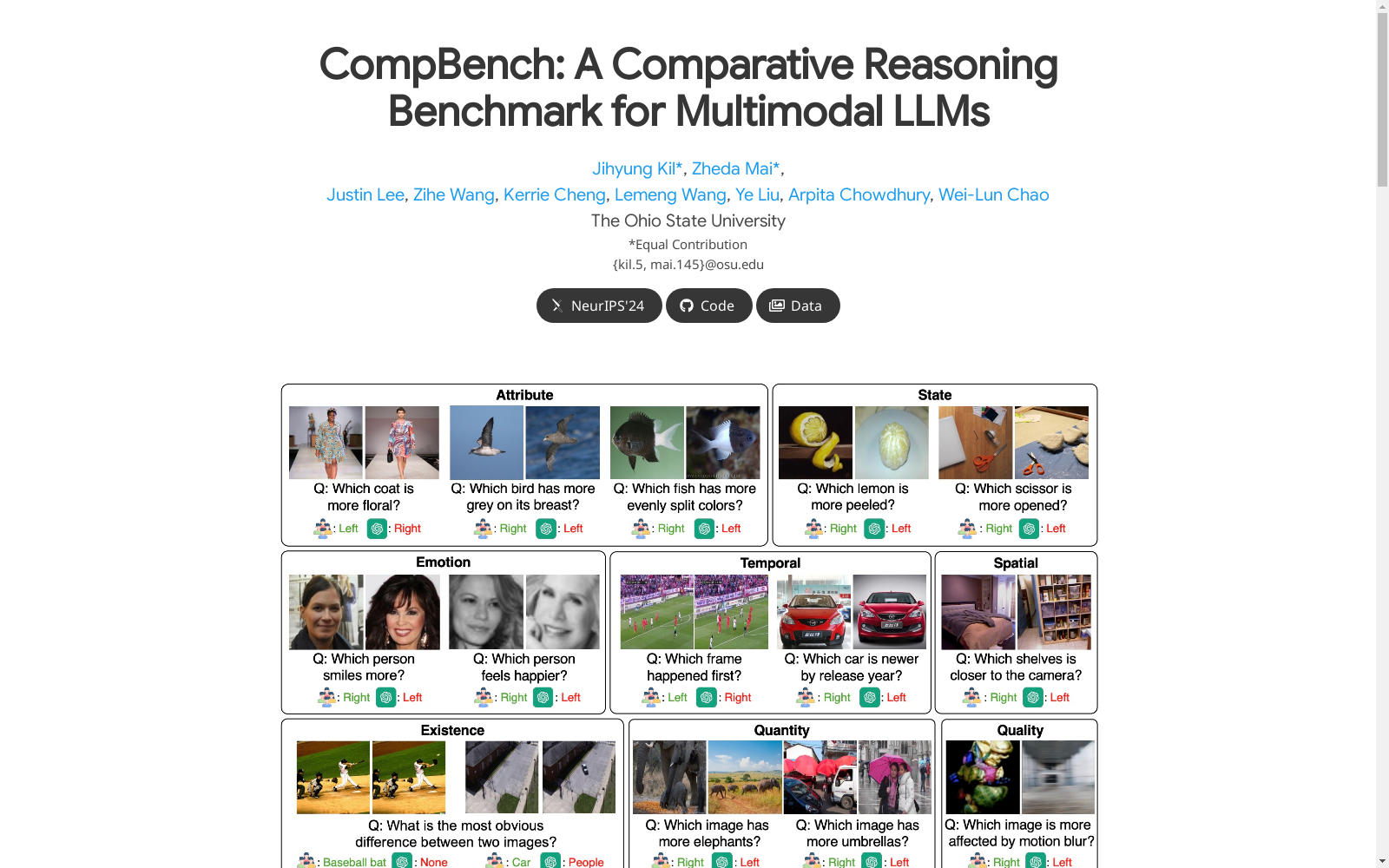
构建方式
COMPBENCH数据集的构建主要涉及从多个视觉数据集中挖掘和配对图像,这些数据集包含丰富的元数据和视觉属性。通过CLIP相似度评分,研究人员选择了大约40K对图像,这些图像涵盖了广泛的视觉领域,包括动物、时尚、运动以及室内和室外场景。为了确保比较的准确性,研究人员设计了针对两个图像之间相对特性的问题,并由人工标注员进行标注。
特点
COMPBENCH数据集的特点在于其广泛的覆盖范围和多样化的比较维度。该数据集涵盖了八个相对比较的维度:视觉属性、存在、状态、情感、时间、空间、数量和质量。这些问题旨在区分两个图像之间的相对特征,并经过人工标注以确保准确性和相关性。此外,该数据集还涵盖了十四个不同的视觉领域,为评估多模态大语言模型(MLLMs)的比较推理能力提供了全面的基准。
使用方法
使用COMPBENCH数据集时,研究人员首先将图像对水平拼接作为视觉输入,然后提示MLLMs回答关于这些图像之间相对性的问题。为了便于自动评估,问题中包含了可能的答案选项。通过评估MLLMs在各个相对性任务上的准确率,研究人员可以了解这些模型在比较推理方面的能力。此外,COMPBENCH还支持两阶段推理策略,即首先分别分析图像对中的每个图像,然后通过纯语言问题进行比较,以进一步评估MLLMs的能力。
背景与挑战
背景概述
在日常生活中,比较对象、场景或情境的能力对于有效的决策和问题解决至关重要。例如,比较苹果的新鲜度有助于在杂货店购物时做出更好的选择,而比较沙发设计有助于优化我们的生活空间的美学。尽管其重要性,但在人工智能(AGI)中,比较能力在很大程度上尚未得到探索。在这篇论文中,我们介绍了COMPBENCH,这是一个用于评估多模态大型语言模型(MLLMs)比较推理能力的基准。COMPBENCH通过八个维度的相对比较来挖掘和配对图像:视觉属性、存在、状态、情感、时态、空间、数量和质量。我们使用来自不同视觉数据集的元数据和CLIP相似度分数,精心策划了大约40K图像对。这些图像对涵盖了广泛的视觉领域,包括动物、时尚、体育以及室内外场景。这些问题经过精心设计,以区分两张图像之间的相对特征,并由人类注释员进行标记,以确保准确性和相关性。我们使用COMPBENCH评估了最近的MLLMs,包括GPT-4V(ision)、Gemini-Pro和LLaVA-1.6。我们的结果表明,它们在比较能力方面存在显著的不足。我们相信,COMPBENCH不仅揭示了这些局限性,而且还为未来MLLMs比较能力的提升奠定了坚实的基础。
当前挑战
COMPBENCH面临的挑战包括解决领域问题的挑战,例如比较推理能力,以及构建过程中所遇到的挑战。在解决领域问题的挑战方面,COMPBENCH旨在评估MLLMs在比较推理方面的能力,这是目前MLLMs研究中的一个空白。在构建过程中,挖掘能够反映相对性的图像对是一个主要挑战。此外,COMPBENCH还需要对相关问题和答案进行标注,以确保数据集的质量和可靠性。
常用场景
经典使用场景
COMPBENCH作为多模态大语言模型(MLLM)的比较推理能力评估基准,通过视觉导向的问题涵盖了八个维度的相对比较:视觉属性、存在性、状态、情绪、时间性、空间性、数量和质量。这些图像对涵盖了广泛的视觉领域,包括动物、时尚、体育以及室内外场景。问题精心设计以区分两幅图像之间的相对特征,并由人类标注者进行标注以验证准确性和相关性。该数据集用于评估最近的MLLMs,包括GPT-4V(ision)、Gemini-Pro和LLaVA-1.6。结果表明,这些模型在比较能力方面存在显著不足。
实际应用
COMPBENCH的实际应用场景包括但不限于:1. 评估和改进MLLMs的比较推理能力;2. 用于教学和训练,帮助MLLMs更好地理解和处理相对比较的问题;3. 用于开发和应用MLLMs,使其在比较推理方面更加准确和高效。
衍生相关工作
COMPBENCH的衍生相关工作包括但不限于:1. 基于COMPBENCH的数据集,开发新的MLLMs模型,以提升其在比较推理方面的能力;2. 利用COMPBENCH的数据和评估方法,研究和改进MLLMs的训练策略和算法;3. 将COMPBENCH的应用范围扩展到其他领域,如医学、金融等,以解决更多实际问题。
以上内容由遇见数据集搜集并总结生成


