Nemotron-Personas-Korea
收藏Hugging Face2026-04-21 更新2026-04-22 收录
下载链接:
https://huggingface.co/datasets/nvidia/Nemotron-Personas-Korea
下载链接
链接失效反馈官方服务:
资源简介:
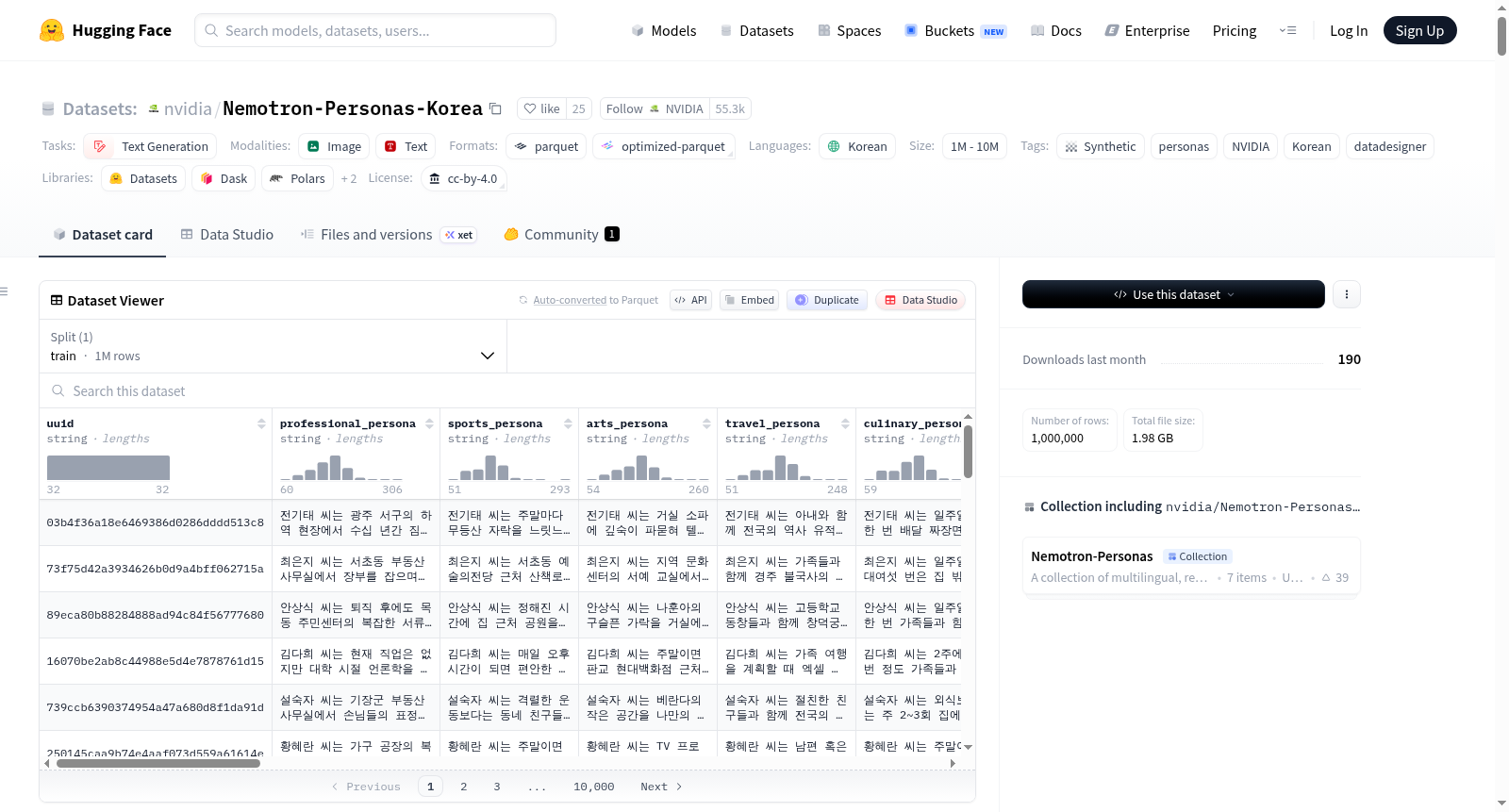
Nemotron-Personas-Korea 是一个基于韩国真实人口统计、地理和性格特征分布合成的开源人物角色数据集(CC BY 4.0),旨在广泛反映韩国人口的多样性和特征。作为首个大规模韩语人物角色数据集,它包含了诸如姓名、性别、年龄、婚姻状况、教育水平、职业和居住地区等属性,这些数据基于韩国统计信息服务中心(KOSIS)、韩国最高法院、国民健康保险公团、韩国农村经济研究院和NAVER Cloud的官方统计数据合成。该数据集支持韩国模型开发者构建包含重要地区特定人口统计和文化背景的Sovereign AI系统。数据集包含100万条记录,涵盖700万个人物角色,26个字段,包括7个人物角色字段、6个人物角色属性字段、12个人口统计和地理背景字段以及1个唯一标识符。数据集适用于提高合成数据的多样性、缓解数据和模型偏见以及改善模型响应的多样性。
提供机构:
NVIDIA
创建时间:
2026-04-21
搜集汇总
数据集介绍
构建方式
Nemotron-Personas-Korea数据集基于韩国真实人口统计、地理及性格特质分布,通过复合AI系统NeMo Data Designer构建而成。其种子数据源自韩国统计厅(KOSIS)、大法院、国民健康保险公团、农村经济研究院及NAVER Cloud等多方官方统计资料。构建过程采用专有概率图模型(PGM)与Apache-2.0许可的google/gemma-4-31B-it模型相结合的方式,并融入了Data Designer内置的验证与评估方法。数据集包含100万条记录、700万个合成人物画像,涵盖26个字段,全面映射了韩国17个广域市道及252个基层行政区的复杂人口结构。
使用方法
该数据集适用于主权人工智能(Sovereign AI)系统开发,尤其针对需要反映韩国本土人口特征与文化脉络的模型优化场景。用户可通过Hugging Face平台直接下载,并依据CC BY 4.0许可自由用于商业或非商业用途。在具体应用中,开发者可借助数据集中丰富的人口统计上下文属性(如地区、教育、职业等),对特定画像进行精准条件化生成,从而扩展合成数据的多样性、缓解模型偏见,并提升模型回复的个性化与在地化程度。NeMo Data Designer用户亦可使用其扩展版本进行无缝集成。
背景与挑战
背景概述
Nemotron-Personas-Korea是由NVIDIA于2026年4月发布的大规模韩语合成人物数据集,基于韩国统计厅、大法院、国民健康保险公团等官方数据,旨在为韩国本土主权人工智能系统提供贴合真实人口分布的高质量训练资源。该数据集以概率图模型与Gemma-4-31B-it模型为核心,生成了涵盖100万条记录、700万种人物的丰富语料,包含年龄、性别、婚姻状态、职业、居住地等26个维度,并首次将韩国老年人口、农村地区及多样化职业分布纳入合成人物生成。这一数据集填补了韩语人物数据领域的空白,推动了合成数据在缓解模型偏见与提升响应多样性方面的研究进展。
当前挑战
该数据集面临的核心挑战包括:一是解决现有韩语人物数据集在年龄、地域及职业分布上对真实人口结构反映不足的问题,尤其是老年群体与农村人口的边缘化,导致生成模型易产生系统性偏见;二是在构建过程中需克服公开统计数据在变量间交互效应(如性别与专业选择)上的缺失,迫使采用独立性假设,限制了人物属性的自然关联性;三是性别统计数据的局限,导致无法在人物中刻画性别认同的多样性;四是数据集虽覆盖252个行政区域,但仍需持续更新以匹配韩国快速变迁的人口与社会结构。
常用场景
经典使用场景
Nemotron-Personas-Korea 数据集的核心价值在于为构建主权人工智能(Sovereign AI)系统提供高质量的合成人格数据。其经典使用场景是作为大规模语言模型(LLM)的微调与对齐训练数据,通过注入精确反映韩国真实人口统计特征(如年龄、性别、职业、地域)的多样化人格描述,显著提升模型在韩语语境下的响应多样性与文化契合度。该数据集尤其适用于需要模拟特定韩国用户群体交互的对话系统开发,以及需要减轻模型对边缘人群(如老年人、农村居民)潜在偏见的公平性研究。
解决学术问题
该数据集精准回应了合成数据生成领域长期存在的代表性不足与分布偏差难题。通过基于韩国官方统计机构(如KOSIS、大法院)的真实人口分布构建概率图模型(PGM),它有效克服了现有韩语人格数据集在年龄、地域、教育程度等维度上的严重失真问题,从而为缓解数据多样性匮乏、模型坍塌(Model Collapse)以及文化刻板印象提供了系统性的解决方案。其开创性的复合AI数据生成方法论,为未来面向特定文化区域的高保真合成数据研究树立了新的基准。
实际应用
在实际产业应用中,该数据集为韩语市场的AI产品研发注入了深厚的本土文化洞察。例如,金融科技公司可利用其中包含的职业、收入、家庭结构等属性,生成高度拟真的客户人格画像,用于个性化金融服务推荐或信用风险评估模型的压力测试。在医疗健康领域,通过结合年龄、疾病史等合成信息,可以构建逼真的患者模型,辅助远程问诊系统的对话训练。此外,韩国的公共服务部门也能借助该数据集优化政务聊天机器人,使其回应更能贴合不同行政区域居民的语言习惯与生活需求。
数据集最近研究
最新研究方向
Nemotron-Personas-Korea数据集聚焦于合成数据在主权AI系统构建中的前沿应用,尤其针对韩国本土人口统计与文化背景的深度建模。该数据集通过融合官方统计资料与概率图模型,旨在缓解现有语料库中年龄、地域及职业维度的偏倚,提升大语言模型响应的多样性与代表性。其突破性在于为低资源语言场景下的模型去偏、防止模型坍塌提供了规模化解决方案,并推动了合成数据在反映真实社会分布方面的可信度,对韩国乃至全球多语言AI生态的公平性与鲁棒性研究具有重要里程碑意义。
以上内容由遇见数据集搜集并总结生成


