WebInstructSub
收藏魔搭社区2026-04-28 更新2024-06-01 收录
下载链接:
https://modelscope.cn/datasets/swift/WebInstructSub
下载链接
链接失效反馈官方服务:
资源简介:
# 🦣 MAmmoTH2: Scaling Instructions from the Web
Project Page: [https://tiger-ai-lab.github.io/MAmmoTH2/](https://tiger-ai-lab.github.io/MAmmoTH2/)
Paper: [https://arxiv.org/pdf/2405.03548](https://arxiv.org/pdf/2405.03548)
Code: [https://github.com/TIGER-AI-Lab/MAmmoTH2](https://github.com/TIGER-AI-Lab/MAmmoTH2)
## WebInstruct (Subset)
This repo contains the partial dataset used in "MAmmoTH2: Scaling Instructions from the Web". This partial data is coming mostly from the forums like stackexchange. This subset contains very high-quality data to boost LLM performance through instruction tuning.
## License
- For the data from "mathstackexchange" and "stackexchange", we use Apache-2.0 license. You are free to share and adapt for any purposes.
- For the data from "socratic", we use CC BY-NC 4.0 license according to https://socratic.org/terms. You are free to share and adapt, but only for non-commercial purposes.
## Fields in our dataset
The field `orig_question' and `orig_answer' are the extracted question-answer pairs from the recalled documents. The `question' and `answer' are the refined version of the extracted question/answer pairs.
Regarding the data source:
1. mathstackexchange: https://math.stackexchange.com/.
2. stackexchange: including https://physics.stackexchange.com/, https://biology.stackexchange.com/, https://chemistry.stackexchange.com/, https://cs.stackexchange.com/.
3. Socratic: the data is originally from https://socratic.org/.
## Size of different sources
| Domain | Size | Subjects |
|:---------------------|:---------|:------------------------------------------------------------------------------------------|
| MathStackExchange | 1484630 | Mathematics |
| ScienceStackExchange | 317209 | Physics, Biology, Chemistry, Computer Science |
| Socratic | 533384 | Mathematics, Science, Humanties |
## Dataset Construction
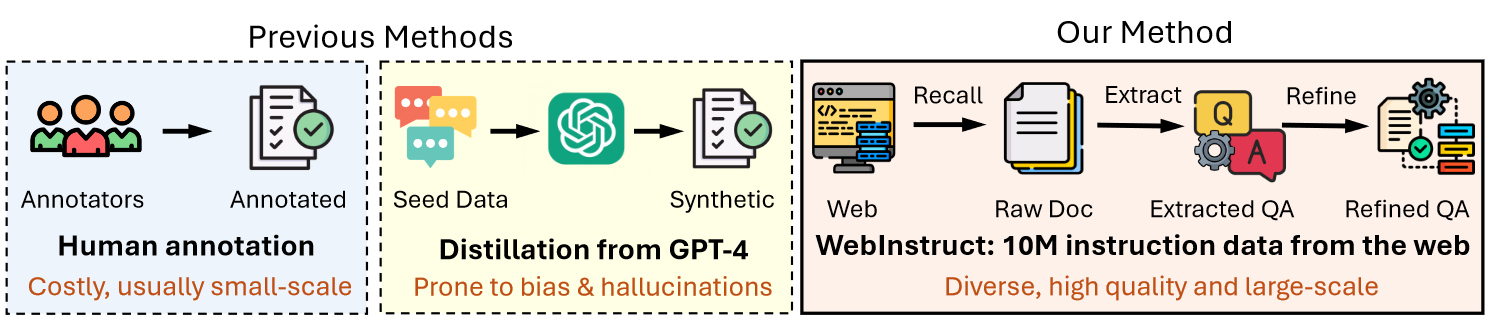
We propose discovering instruction data from the web. We argue that vast amounts of high-quality instruction data exist in the web corpus, spanning various domains like math and science. Our three-step pipeline involves recalling documents from Common Crawl, extracting Q-A pairs, and refining them for quality. This approach yields 10 million instruction-response pairs, offering a scalable alternative to existing datasets. We name our curated dataset as WebInstruct.
## Citation
```
@article{yue2024mammoth2,
title={MAmmoTH2: Scaling Instructions from the Web},
author={Yue, Xiang and Zheng, Tuney and Zhang, Ge and Chen, Wenhu},
journal={Advances in Neural Information Processing Systems},
year={2024}
}
```
# 🦣 MAmmoTH2:从网络扩展指令数据集
项目主页:[https://tiger-ai-lab.github.io/MAmmoTH2/](https://tiger-ai-lab.github.io/MAmmoTH2/)
论文:[https://arxiv.org/pdf/2405.03548](https://arxiv.org/pdf/2405.03548)
代码仓库:[https://github.com/TIGER-AI-Lab/MAmmoTH2](https://github.com/TIGER-AI-Lab/MAmmoTH2)
## WebInstruct(子集)
本仓库包含论文《MAmmoTH2:从网络扩展指令数据集》中使用的部分数据集。该部分数据主要源自Stack Exchange(堆栈交换)类论坛,此子集包含高质量数据,可用于指令微调以提升大语言模型(Large Language Model)的性能。
## 许可协议
- 对于源自mathstackexchange和stackexchange的数据,采用Apache-2.0许可协议。您可自由共享并改编该数据用于任意用途。
- 对于源自Socratic的数据,依据https://socratic.org/terms 采用CC BY-NC 4.0许可协议。您可自由共享并改编,但仅可用于非商业用途。
## 数据集字段说明
本数据集包含`orig_question`与`orig_answer`字段,二者为从召回文档中提取的原始问答对;`question`与`answer`字段则为提取后的问答对经过精炼优化后的版本。
关于数据来源:
1. mathstackexchange:https://math.stackexchange.com/
2. stackexchange:涵盖https://physics.stackexchange.com/、https://biology.stackexchange.com/、https://chemistry.stackexchange.com/、https://cs.stackexchange.com/
3. Socratic:数据最初源自https://socratic.org/
## 各数据源规模
| 领域 | 数据量 | 所属学科 |
|:---------------------|:---------|:------------------------------------------------------------------------------------------|
| MathStackExchange | 1484630 | 数学 |
| ScienceStackExchange | 317209 | 物理学、生物学、化学、计算机科学 |
| Socratic | 533384 | 数学、科学、人文科学 |
## 数据集构建方案
我们提出从网络中挖掘指令数据的研究思路。我们认为,海量高质量的指令数据广泛分布于网络语料库中,覆盖数学、科学等众多领域。我们的三阶段流水线包含以下步骤:从Common Crawl语料库中召回文档、提取问答对,以及对提取内容进行质量精炼。该方法可生成1000万条指令-响应对,为现有数据集提供了一种可扩展的替代方案。我们将该精选数据集命名为WebInstruct。

## 引用格式
@article{yue2024mammoth2,
title={MAmmoTH2: Scaling Instructions from the Web},
author={Yue, Xiang and Zheng, Tuney and Zhang, Ge and Chen, Wenhu},
journal={Advances in Neural Information Processing Systems},
year={2024}
}
提供机构:
maas
创建时间:
2024-06-05


