cardgames-sftdata-trimmed
收藏Hugging Face2026-04-16 更新2026-04-17 收录
下载链接:
https://huggingface.co/datasets/chrisiyer/cardgames-sftdata-trimmed
下载链接
链接失效反馈官方服务:
资源简介:
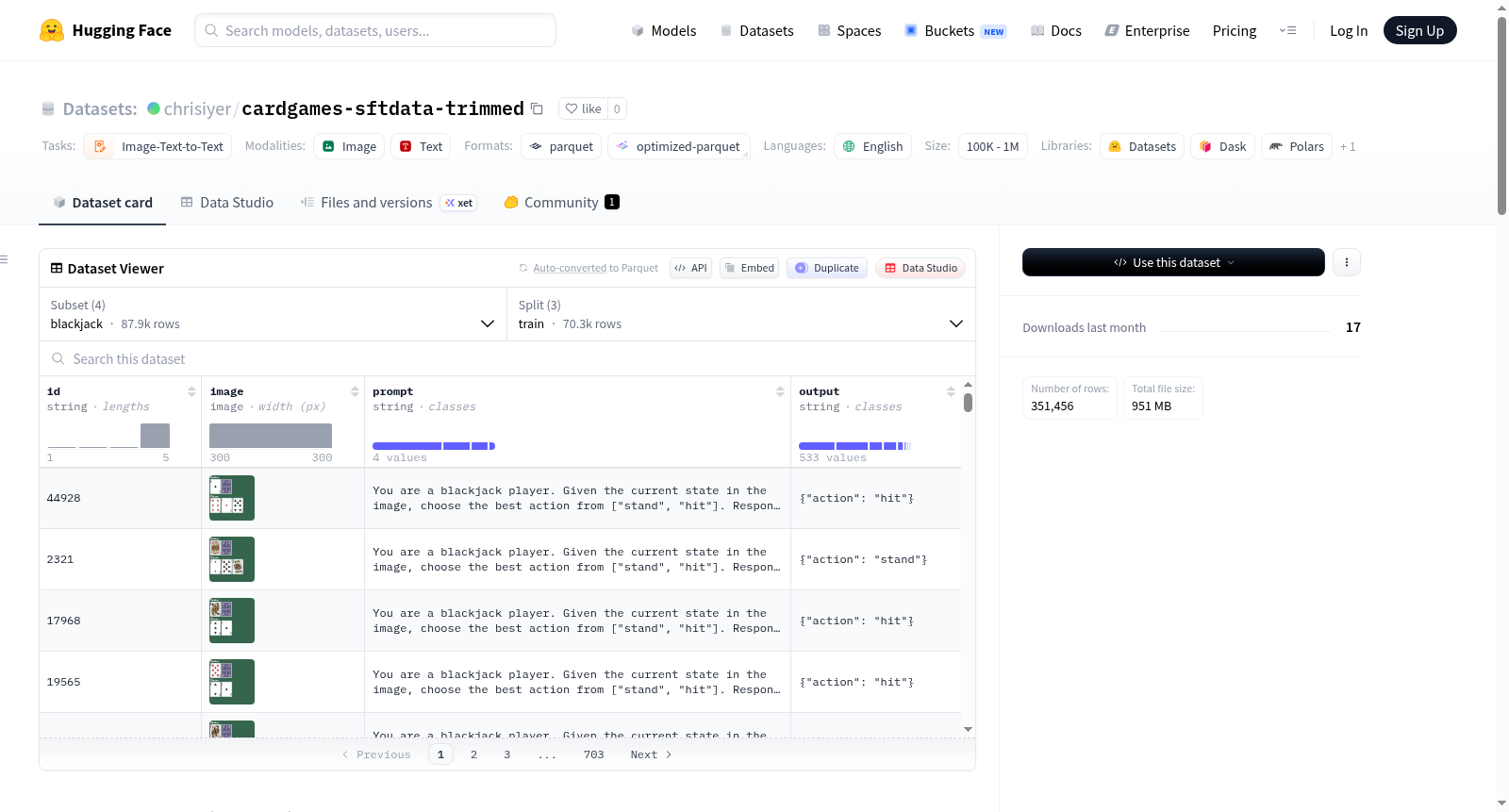
该数据集是《通过强化学习微调大型视觉语言模型作为决策代理》论文中发布数据的修改版本,专为视觉语言模型的监督微调设计。数据集包含四种基于卡牌和游戏的视觉语言决策任务:'numberline'、'ezpoints'、'points24' 和 'blackjack'。与原始数据相比,此版本简化了提示和目标输出,每个示例仅包含图像、提示和目标输出。数据集分为训练集、验证集和测试集,每个示例包含'id'、'image'、'prompt'和'output'字段。数据集完全兼容Hugging Face的`datasets`库,可直接使用`load_dataset()`加载。适用于视觉语言模型训练和持续学习实验。
创建时间:
2026-04-15
原始信息汇总
Cardgames SFT Data (Trimmed) 数据集概述
数据集基本信息
- 数据集名称: Cardgames SFT Data (Trimmed)
- 任务类别: 图像-文本到文本
- 主要语言: 英语
- 数据规模: 10K < n < 100K
- 配置数量: 4个独立配置
数据集配置
数据集包含以下四个独立的配置,每个配置对应一个卡牌或游戏视觉语言决策任务:
- blackjack
- numberline
- ezpoints
- points24
数据内容与结构
- 数据来源: 本数据集是论文《Fine-Tuning Large Vision-Language Models as Decision-Making Agents via Reinforcement Learning》所发布数据的修改版本。
- 核心修改: 简化了提示词和目标输出,使每个示例仅包含图像、提示词和目标输出。对于原始结构为顺序动作轨迹的任务,在适当情况下将这些轨迹折叠为单个监督学习示例。
- 数据结构: 每个任务配置均提供
train、validation和test划分。每个数据示例包含以下字段:idimagepromptoutput
- 兼容性: 与Hugging Face
datasets库完全兼容,可直接使用load_dataset()加载。
任务描述
1. Numberline
- 任务描述: 给定图像中呈现的目标数字和当前数字,模型必须决定将当前数字向上还是向下移动。
- 数据特点: 与原始版本相比基本未修改,仅缩短了提示词和输出,移除了目标链式思考文本等中间输出和其他辅助字段。
2. EZPoints
- 任务描述: 给定两张卡牌,其数值相加或相乘结果为12,模型必须给出一个使用其数值并计算结果为12的公式(例如
3*4)。 - 数据特点: 缩短了提示词和输出。消除了原始SFT输出的顺序设计,使每个试验成为单个示例,图像呈现一次,完整公式出现在输出中。
3. Points24
- 任务描述: 给定四张卡牌,模型必须给出一个使用其数值并计算结果为24的公式。
- 数据特点: 缩短了提示词和输出,并消除了顺序结构。原始论文中的模型在此任务上表现不佳。
4. Blackjack
- 任务描述: 给定庄家手牌和玩家手牌,模型必须决定
hit还是stand。 - 数据特点: 缩短了提示词和输出。保留了顺序试验(例如,在
hit之后的试验包含相同卡牌加上一张额外卡牌),但每个试验都有唯一的目标标签,可作为独立的监督学习示例处理。
数据来源与引用
- 原始项目网站: https://rl4vlm.github.io
- 原始发布数据: https://huggingface.co/LEVI-Project/sft-data/tree/main
- 使用要求: 使用本数据时,请确保引用原始工作。
数据集用途说明
本数据集旨在作为原始任务数据的简化监督微调版本,用于视觉语言模型训练和持续学习实验。
搜集汇总
数据集介绍
构建方式
在视觉语言模型决策任务的研究背景下,Cardgames SFT Data (Trimmed)数据集基于RL4VLM项目发布的原始监督微调数据构建。该数据集通过精简提示词和目标输出,将原本可能包含序列动作轨迹的结构简化为每个示例仅包含图像、提示和输出三个核心字段。针对四种卡牌游戏任务,如Blackjack和Points24,构建过程中适当合并了序列化步骤,使得每个样本能够作为独立的监督学习实例,从而适配标准的图像到文本生成框架。
特点
该数据集聚焦于卡牌与游戏视觉决策任务,涵盖Numberline、EZPoints、Points24和Blackjack四个独立配置,每个配置均提供训练、验证和测试划分。其显著特点在于简化了原始数据的复杂结构,去除中间链式思考等辅助字段,使样本更加紧凑。数据规模介于一万到十万之间,完全兼容Hugging Face生态系统,支持直接加载与处理,为视觉语言模型的微调与持续学习提供了清晰且标准化的基准。
使用方法
使用该数据集时,可通过Hugging Face的datasets库直接加载,指定相应任务配置即可获取划分后的数据。例如,加载Blackjack任务后,每个样本包含id、image、prompt和output字段,可直接用于监督微调训练。研究人员能够便捷地将其集成到现有视觉语言模型管道中,进行决策能力评估或渐进学习实验,同时需注意引用原始RL4VLM项目以尊重学术贡献。
背景与挑战
背景概述
Cardgames SFT Data (Trimmed)数据集源于2024年发布的RL4VLM项目,由LEVI-Project团队构建,旨在探索视觉语言模型在决策任务中的强化学习微调方法。该数据集聚焦于卡牌与游戏场景下的视觉推理问题,涵盖数字线调整、简易点数计算、24点游戏及二十一点策略四个核心任务,为多模态智能体在结构化环境中的决策能力评估提供了标准化基准。其简化版本通过精炼提示与输出格式,提升了数据集的易用性,推动了视觉语言模型在序列决策与符号推理领域的应用研究。
当前挑战
该数据集致力于解决视觉语言模型在复杂决策任务中的泛化与推理挑战,尤其针对符号操作与多步逻辑推断的难题。例如,在Points24任务中,模型需从四张卡牌图像中推导出结果为24的数学表达式,这对模型的符号理解与算术推理能力提出了较高要求。数据构建过程中,原始序列化决策轨迹被压缩为独立样本,虽增强了训练效率,却可能损失动作序列的连续性信息,增加了模型学习长期依赖关系的难度。此外,不同游戏任务间的领域差异要求模型具备跨任务的适应性,进一步考验了多模态表示的统一性。
常用场景
经典使用场景
在视觉语言模型的研究领域,Cardgames SFT Data (Trimmed) 数据集为模型决策能力的评估提供了经典场景。该数据集通过四种卡牌游戏任务,如Blackjack和Points24,模拟了视觉推理与语言生成的交互过程。研究者通常利用这些任务对大型视觉语言模型进行监督微调,以优化模型在复杂决策链中的表现,特别是在需要结合图像信息进行逻辑推理的情境下。
衍生相关工作
该数据集衍生了多项经典研究工作,其中最具代表性的是RL4VLM项目提出的强化学习框架。该项目利用原始数据探索视觉语言模型的决策微调方法,为后续研究奠定了基础。此外,基于该数据集的简化版本,研究者进一步开发了高效的监督学习管道,促进了视觉语言模型在序列预测任务中的优化,并启发了多模态持续学习领域的创新实验。
数据集最近研究
最新研究方向
在视觉语言模型决策智能领域,cardgames-sftdata-trimmed数据集作为多模态强化学习框架下的关键资源,正推动着模型在复杂游戏环境中的推理能力研究。前沿探索聚焦于如何利用其简化的监督微调格式,提升模型在数字推理、数学公式生成及策略决策任务中的泛化性能,尤其关注跨任务迁移学习与端到端训练效率。该数据集与近期大模型在具身智能和交互式决策中的热点进展紧密相连,为评估模型在结构化视觉输入下的符号推理能力提供了标准化基准,对推动多模态人工智能向更高效、可解释的决策系统发展具有重要实证意义。
以上内容由遇见数据集搜集并总结生成


