MixCount
收藏Hugging Face2026-05-19 更新2026-05-21 收录
下载链接:
https://huggingface.co/datasets/CorentinDumery/MixCount
下载链接
链接失效反馈官方服务:
资源简介:
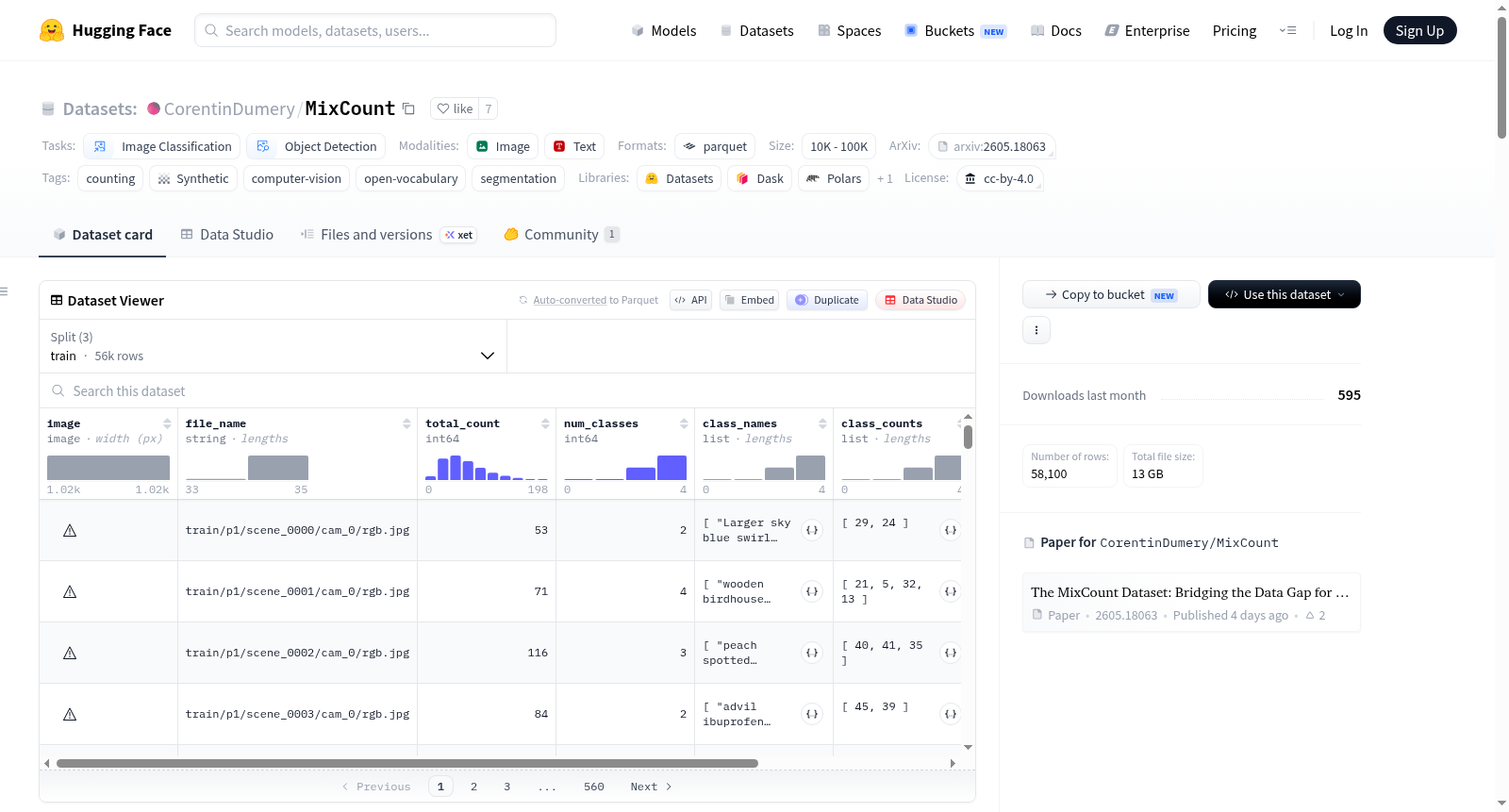
MixCount是一个用于混合对象、开放词汇对象计数的大规模合成数据集。该数据集旨在解决当前计数模型在工业检测和分拣等实际混合对象场景中面临的挑战,例如难以区分视觉相似对象、识别自相似组件以及忽略重复背景模式。数据集包含58,000个计数场景,涵盖1,522个不同的对象类别,总计超过400万个计数实例。其数据通过自动生成流程创建,结合了合成数据集的规模与真实世界3D捕获的逼真感。每个样本提供像素级完美的计数监督,以及实例和类别的分割掩码、边界框、深度图和法线图等密集注释。此外,数据集为每个对象提供多个视觉示例(包括外部裁剪和场景内不同尺度的裁剪)以及简短、简洁和详细三个层次的文本描述,以支持灵活的开放词汇计数提示。在MixCount上训练可将现有开放词汇计数基准(如PairTally和FSC-147)的平均绝对误差降低约20%。数据集适用于图像分类和对象检测等计算机视觉任务,特别针对计数和分割场景。
创建时间:
2026-05-18
搜集汇总
数据集介绍
构建方式
MixCount数据集的构建采用了自动化生成管线,基于高质量真实世界3D捕获数据,通过程序化采样物体、干扰物、环境与相机布局,生成具有像素级标注的逼真混合场景。该管线同时提供短、精确、详细三级文本描述与视觉示例,满足开放词汇计数需求。
特点
MixCount包含58K个计数场景、1,522个物体类别及超过400万个实例,支持混合对象、开放词汇计数。其独特之处在于针对视觉相似物体区分、自相似组件识别与重复背景干扰等常见失败模式设计,并集成了外部与场景内视觉示例、深度与法向图等密集标注。
使用方法
用户可通过HuggingFace数据集库加载,例如使用`load_dataset('CorentinDumery/MixCount', split='train', streaming=True)`。数据样本包含图像、文件名、总计数、类别名称与数量、边界框及类别索引,便于进行图像分类、目标检测或计数任务的训练与评估。
背景与挑战
背景概述
MixCount数据集由来自EPFL、牛津大学和西北大学的研究团队于2026年发布,旨在解决开放词汇目标计数领域中混合对象场景的数据匮乏问题。当前主流计数模型在面对工业检测与分拣等实际应用时,常因视觉相似物体混淆、自我相似组件误判及背景干扰而失效。MixCount通过自动合成管线生成58,000张具有像素级完美标注的场景图像,涵盖1,522个物体类别与超过400万个实例。该数据集的引入显著降低了现有基准测试如PairTally和FSC-147的计数误差约20%,为开放词汇计数任务提供了高质量的训练资源,推动了模型在复杂场景下的泛化能力。
当前挑战
MixCount数据集应对的核心挑战在于混合对象场景中的开放词汇计数,这一任务要求模型能够同时区分视觉上相似的物体(如不同尺寸的弹珠)、正确识别自相似组件(如将太阳镜的镜片视为独立单元而非整体),并抑制重复背景模式的干扰。在构建过程中,研究者面临如何从真实世界高质量3D捕获中程序化生成具备照片级真实感且标注精确的训练场景的难题,平衡合成数据的规模与场景多样性,同时确保文本描述、视觉样例等多模态输入与密集标注(如边界框、分割掩码)的一一对应关系,以支持灵活的任务提示与模型训练。
常用场景
经典使用场景
在计算机视觉领域,MixCount数据集专为混合对象、开放词汇下的目标计数任务而设计。该场景要求模型在单一图像中同时区分多种类别对象(如工业流水线上不同零件或仓库中混杂商品),并依据文本或视觉提示精准统计各类别数量。数据集中包含58,000张合成场景图像,覆盖1,522个对象类别,并提供像素级标注和分层文本描述,为训练鲁棒的计数模型提供了规模化的基准资源。研究者可借此训练模型识别视觉相似物体、处理自相似组件(如成对物品)并忽略重复背景干扰,从而在复杂场景中实现精确计数。
实际应用
MixCount在实际工业场景中具有广阔应用前景,尤其适用于自动化质检、仓储分拣和零售库存管理等领域。例如,在电子产品生产线中,系统可依据提示词实时统计不同型号芯片或螺丝的数量;在物流中心,模型能快速清点混装包裹中的商品类别及数量。此外,医疗领域的病理切片细胞分类计数、农业中不同作物或害虫的统计等任务均可受益于该数据集的泛化能力。其开放词汇特性消除了重新训练模型的成本,使开发者能够通过自然语言灵活指定计数目标,显著提升了部署效率。
衍生相关工作
MixCount数据集的发布催生了多项前沿研究。其生成的挑战性场景促使研究者改进计数架构中的特征对齐机制,例如通过层级文本描述增强视觉-语言模型的细粒度理解能力。后续工作进一步探索了将MixCount与去噪扩散模型结合,以合成更具挑战性的罕见类别计数样本。此外,该数据集的多模态标注(框、分割图、深度图)为联合计数与分割任务提供了新基准,推动了如CountGD++等模型在开放词汇场景下的性能突破。这些衍生工作共同巩固了MixCount作为混合对象计数领域关键验证平台的地位。
以上内容由遇见数据集搜集并总结生成


