BVI-RLV
收藏arXiv2024-07-04 更新2024-07-09 收录
下载链接:
https://doi.org/10.21227/mzny-8c77
下载链接
链接失效反馈资源简介:
BVI-RLV数据集由布里斯托大学视觉信息实验室创建,专门用于低光视频增强研究。该数据集包含40个场景,每个场景在两种低光条件下捕捉,共计31,800对帧。数据集通过使用可编程电动导轨和基于图像的方法进行像素级帧对齐,提供了全注册的地面实况数据。创建过程中,数据集在受控环境中使用消费者级相机捕捉,确保了数据的质量和多样性。BVI-RLV数据集主要应用于计算机视觉领域,特别是低光视频增强,旨在解决低光环境下视频质量下降的问题。
The BVI-RLV dataset was developed by the Visual Information Laboratory at the University of Bristol, specifically tailored for low-light video enhancement research. It encompasses 40 scenes, with each scene captured under two low-light conditions, resulting in a total of 31,800 frame pairs. The dataset provides fully registered ground-truth data, which is realized through pixel-level frame alignment using a programmable electric rail and image-based methods. During its construction, the dataset was captured in a controlled environment with consumer-grade cameras, ensuring both data quality and diversity. The BVI-RLV dataset is primarily utilized in the field of computer vision, particularly for low-light video enhancement, with the goal of addressing the problem of degraded video quality in low-light environments.
提供机构:
布里斯托大学视觉信息实验室
创建时间:
2024-07-04
原始信息汇总
数据集详情
错误信息
- 错误代码: 403
- 错误描述: Forbidden
AI搜集汇总
数据集介绍
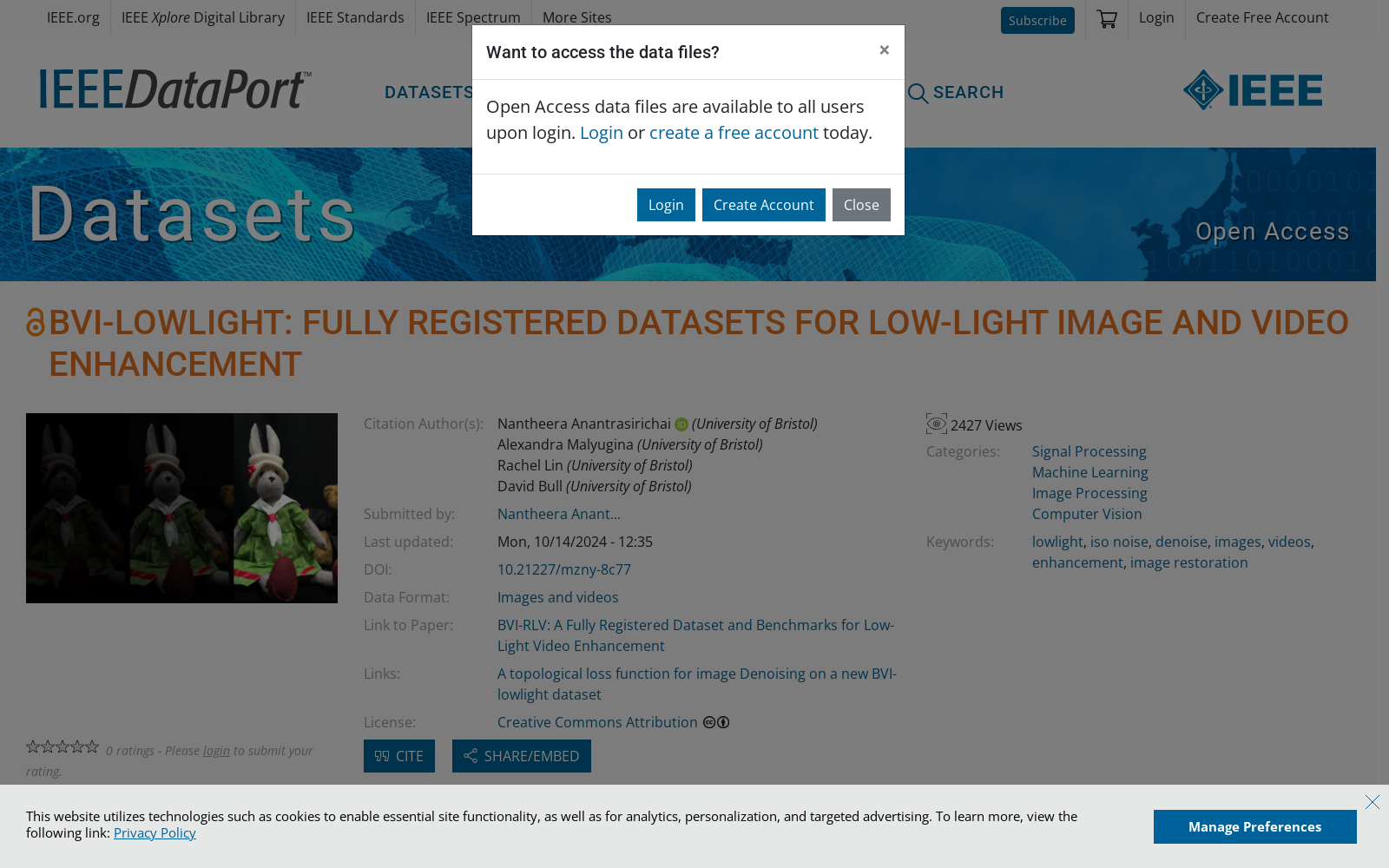
构建方式
在低光视频增强领域,训练数据稀缺一直是制约深度学习算法性能提升的关键因素。针对这一问题,BVI-RLV数据集的构建者们采用了一种新颖的方法,通过在可控环境中使用可编程电机滑轨拍摄40个场景的视频,并在正常光照条件下拍摄了对应的地面真实数据。为了确保像素级的帧对齐,他们采用了基于图像的方法对地面真实数据进行精细调整。此外,数据集还包括了四种不同技术的基准测试,包括卷积神经网络、Transformer、扩散模型和状态空间模型,以供研究者们进行性能评估。
特点
BVI-RLV数据集的特点在于其全面注册的视频对,这些视频对在空间和时间维度上都进行了精确对齐,使得训练数据更加真实和可靠。此外,数据集涵盖了多种运动场景,以及两种不同的低光照条件,使得模型训练更加全面和具有代表性。数据集中还包含了超过30k个地面真实配对帧,为研究者们提供了丰富的训练资源。
使用方法
BVI-RLV数据集的使用方法相对简单。研究者们可以使用该数据集训练低光视频增强模型,并通过基准测试评估模型的性能。此外,数据集中的四种不同技术的基准模型也可以供研究者们参考和比较。需要注意的是,由于数据集的规模较大,训练过程可能需要较长时间,因此研究者们需要准备足够的计算资源。
背景与挑战
背景概述
低光视频的捕捉在自然历史电影制作、生物学、动物学、机器人学、监控和安全等多个领域至关重要。然而,由于光强度与噪声之间的逆相关性,低光视频往往伴随着时空不相关的噪声,这严重影响了计算机视觉应用中的可见性和性能。为了解决这一问题,英国布里斯托尔大学视觉信息实验室的Ruirui Lin等人创建了一个名为BVI-RLV的新型低光视频数据集。该数据集包含了40个场景,这些场景在不同的运动场景下,分别在两种不同的低光条件下捕捉,并包含了真实噪声和时序伪影。为了确保数据的准确性,研究人员使用可编程电机化轨道车捕捉了在正常光线下完全注册的地面真实数据,并通过基于图像的方法进行了像素级帧对齐,以适应不同的光级。此外,他们还提供了基于卷积神经网络、变换器、扩散模型和状态空间模型(Mamba)的基准测试,实验结果表明,完全注册的视频对对于低光视频增强(LLVE)具有重要意义,并且使用该数据集训练的模型优于使用现有数据集训练的模型。
当前挑战
尽管低光图像增强算法的性能近年来有了显著提高,但这些技术无法直接应用于低光视频内容,因为逐帧应用会导致时序不一致。为了优化这些方法以适应运动视频,需要大量且多样化的数据集,并且需要具有对齐的地面真实信息。然而,低光视频增强(LLVE)是一个病态问题,这意味着很难获得清洁的地面真实信息。此外,现有的低光视频研究中的对齐和准确地面真实数据有限,因此研究人员通常使用合成数据集,但这些数据集可能无法准确复制真实失真。为了解决这些问题,BVI-RLV数据集应运而生。然而,构建这样的数据集也面临一些挑战,例如运动控制、噪声特征保持和帧对齐等。
常用场景
经典使用场景
BVI-RLV数据集主要用于低光照视频增强(LLVE)任务,其独特的全注册特性使得该数据集成为训练和评估低光照视频增强模型的重要资源。数据集包含40个场景,涵盖了各种运动情况,在两种不同的低光照条件下捕捉,并包含了真实噪声和时序伪影。这使得BVI-RLV成为研究和开发低光照视频增强算法的理想选择。
实际应用
BVI-RLV数据集的实际应用场景包括但不限于自然历史纪录片制作、生物学、动物学、机器人、监控和安全等领域。在这些领域,低光照视频的增强对于提高视频质量和性能至关重要。BVI-RLV数据集为这些应用提供了高质量的训练数据,有助于开发更精确、更可靠的低光照视频增强算法。
衍生相关工作
BVI-RLV数据集的发布促进了低光照视频增强领域的研究。基于BVI-RLV数据集,研究人员已经开发了多种低光照视频增强算法,包括基于卷积神经网络、Transformer、扩散模型和状态空间模型的算法。这些算法在BVI-RLV数据集上的表现优于现有数据集训练的模型,证明了BVI-RLV数据集在低光照视频增强研究中的重要性。
以上内容由AI搜集并总结生成


