Neohm/VoE-2026
收藏Hugging Face2026-04-25 更新2026-04-26 收录
下载链接:
https://hf-mirror.com/datasets/Neohm/VoE-2026
下载链接
链接失效反馈官方服务:
资源简介:
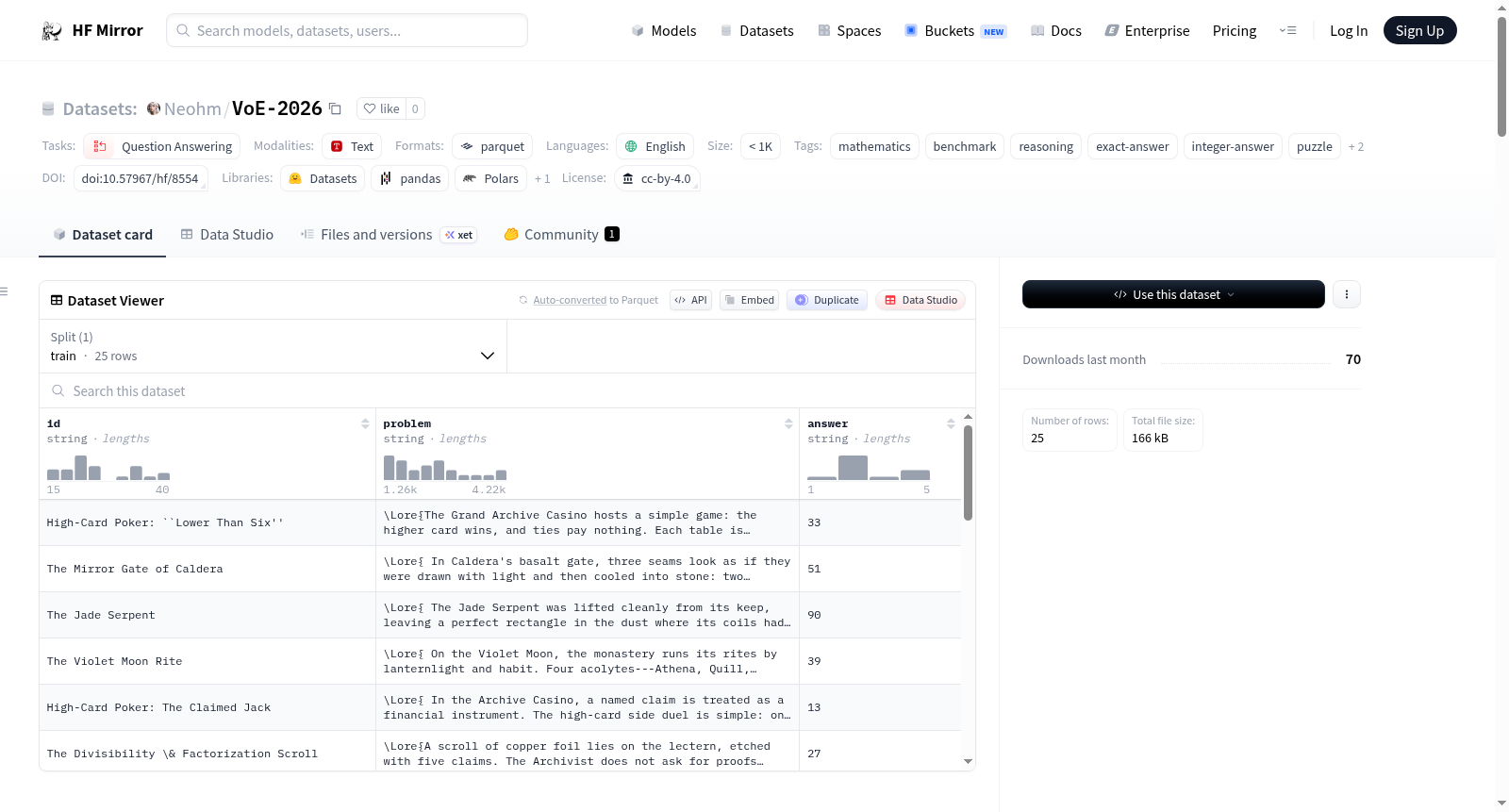
Vault of Echoes 2026(简称VoE-2026)是一个数学推理基准数据集,包含25个以传说为背景的精确答案谜题。它是一个公开答案的基准,发布了答案密钥以便于重现和独立验证。数据集包括问题和答案文件(Parquet和CSV格式)、评分脚本和提交示例。任务要求解决每个问题并提交一个指定范围内的整数答案。数据集计划每年发布一次,采用CC-BY-4.0许可协议。
Vault of Echoes 2026, abbreviated VoE-2026, is a 25-problem mathematical reasoning benchmark built from lore-wrapped exact-answer puzzles. It is a public-answer benchmark with released answer keys for reproducibility and independent verification. The dataset includes problem and answer files in both Parquet and CSV formats, along with scoring scripts and submission examples. The task involves solving each problem and submitting an integer answer within a specified range. The dataset is intended for yearly releases and is licensed under CC-BY-4.0.
提供机构:
Neohm
搜集汇总
数据集介绍
构建方式
Vault of Echoes 2026(简称VoE-2026)是一个面向数学推理领域的公开答案基准测试集,其构建核心在于将叙事性与精确性有机结合。数据集包含25道精心设计的问题,每一道问题均源自“Vault of Echoes: Volume I”这一叙事框架,以谜题形式呈现,并要求模型输出整数形式的精确答案。为确保评估的透明性与可复现性,所有问题的答案键均随数据集一同公开发布。数据集以Parquet和CSV两种格式存储,并附带了官方评分脚本、提交模板以及评分合约配置文件,构成了一套完整的评估流程。值得注意的是,原始的源TeX文件与完整的解题过程并未包含在此次公开版本中,以维护评测的公正性。
使用方法
研究人员可通过Hugging Face平台直接加载数据,使用Pandas读取训练数据并分离问题与答案列。官方提供了清晰的提交格式示范,要求提交CSV文件包含“id”与“answer”两列,其中答案为整数形式。评估时,只需运行官方提供的评分脚本`score_submission.py`,并指定提交文件与答案键路径即可获得评分摘要与逐题正确性记录。需强调的是,VoE-2026明确禁止在模型训练、微调或检索流程中接触该数据集及答案键,否则在报告中需如实披露接触情况,且不可将其视作未见过数据的泛化性能。这一严格的使用政策保障了基准测试的权威性与可比性。
背景与挑战
背景概述
VoE-2026(Vault of Echoes 2026)是由Aaditya Paudel于2026年创建的一个数学推理基准数据集,旨在通过25道融入叙事背景的精确答案谜题,评估智能系统在复杂数学推理与精确输出方面的能力。该数据集以公共答案形式发布,支持独立验证与AIME风格评分,并附带历史UI原生排行榜快照,记录了2026年1月5日在原始Vault of Echoes提示界面上的系统表现。作为年度基准系列的首个版本,VoE-2026通过融合叙事元素与严格评分契约,为数学推理领域提供了一个兼具趣味性与严谨性的评估工具,其影响力体现在对推理模型精确性与泛化能力的深度检验上。
当前挑战
VoE-2026所解决的领域问题在于,现有数学推理基准往往允许部分评分或模糊输出,难以区分推理质量与表面策略;该数据集通过严格精确匹配的整数答案与无部分评分机制,迫使模型必须实现完全正确的推导过程与输出。构建过程中面临的主要挑战包括:设计25道难度均衡且难以被简单模式匹配攻克的叙事谜题,维护公共答案集不可见性以防止数据污染,以及确保原始UI环境与公开基准之间的评估一致性,从而为独立验证与历史对比提供可靠基础。
常用场景
经典使用场景
VoE-2026数据集由25道精妙绝伦的谜题构成,每一道题目都包裹在虚构的叙事外壳之下,要求模型从复杂文本中精准提取数学逻辑并输出整数答案。其经典使用场景聚焦于评估大型语言模型在纯推理任务上的表现,尤其是那些需要将自然语言描述转化为精确数学运算的情境。研究者通常将这一基准嵌入到模型对比实验中,通过严格的标准答案匹配(即AIME风格的精确字符匹配评分)来度量模型在约束条件下完成符号推理的卓越能力。
解决学术问题
在学术研究领域,VoE-2026精准解决了对语言模型“伪推理”现象的辨识难题。长期以来,许多模型在数学任务上表现出色,却往往依赖记忆或表层模式匹配而非真正的逻辑推导。VoE-2026通过将数学问题嵌套于独特的叙事语境中,迫使模型必须剥离故事外壳、提取核心数学结构,从而有效区分了模型的机械模仿与深层推理能力。这一基准的发布为探究语言模型逻辑泛化边界提供了无偏且可重复的评估框架。
实际应用
在实际应用层面,VoE-2026可被用于筛选和验证具备高可靠性推理引擎的AI系统。例如,在智能教育辅导、自动化数学证明验证以及需要精确数值输出的决策支持系统中,通过这一基准能够高效地甄别出擅长处理非结构化情境下逻辑计算的模型。此外,该数据集整合的UI原生历史排行榜为实际产品环境下的多轮对话性能评估提供了基线参考,直接服务于工业界对模型推理鲁棒性的部署前测试。
数据集最近研究
最新研究方向
VoE-2026作为新一代数学推理基准,聚焦于以叙事包裹的精确答案谜题,评估大语言模型在复杂逻辑与数学运算上的能力。其独特之处在于公开答案键以确保可复现性,同时附带了历史UI原生排行榜,记录了2026年初主流系统(如Gemini PRO、GPT PRO)在原始提示界面上的表现差异。该基准推动了推理模型在精确整数答案场景下的公平比较,并催生了关于训练数据污染与披露策略的讨论。作为年度系列的首发版本,VoE-2026为后续隐藏答案评估范式奠定了基础,在数学推理黑箱测试领域具有里程碑意义。
以上内容由遇见数据集搜集并总结生成


