RefSpatial-Bench
收藏Hugging Face2025-06-05 更新2025-06-06 收录
下载链接:
https://huggingface.co/datasets/BAAI/RefSpatial-Bench
下载链接
链接失效反馈官方服务:
资源简介:
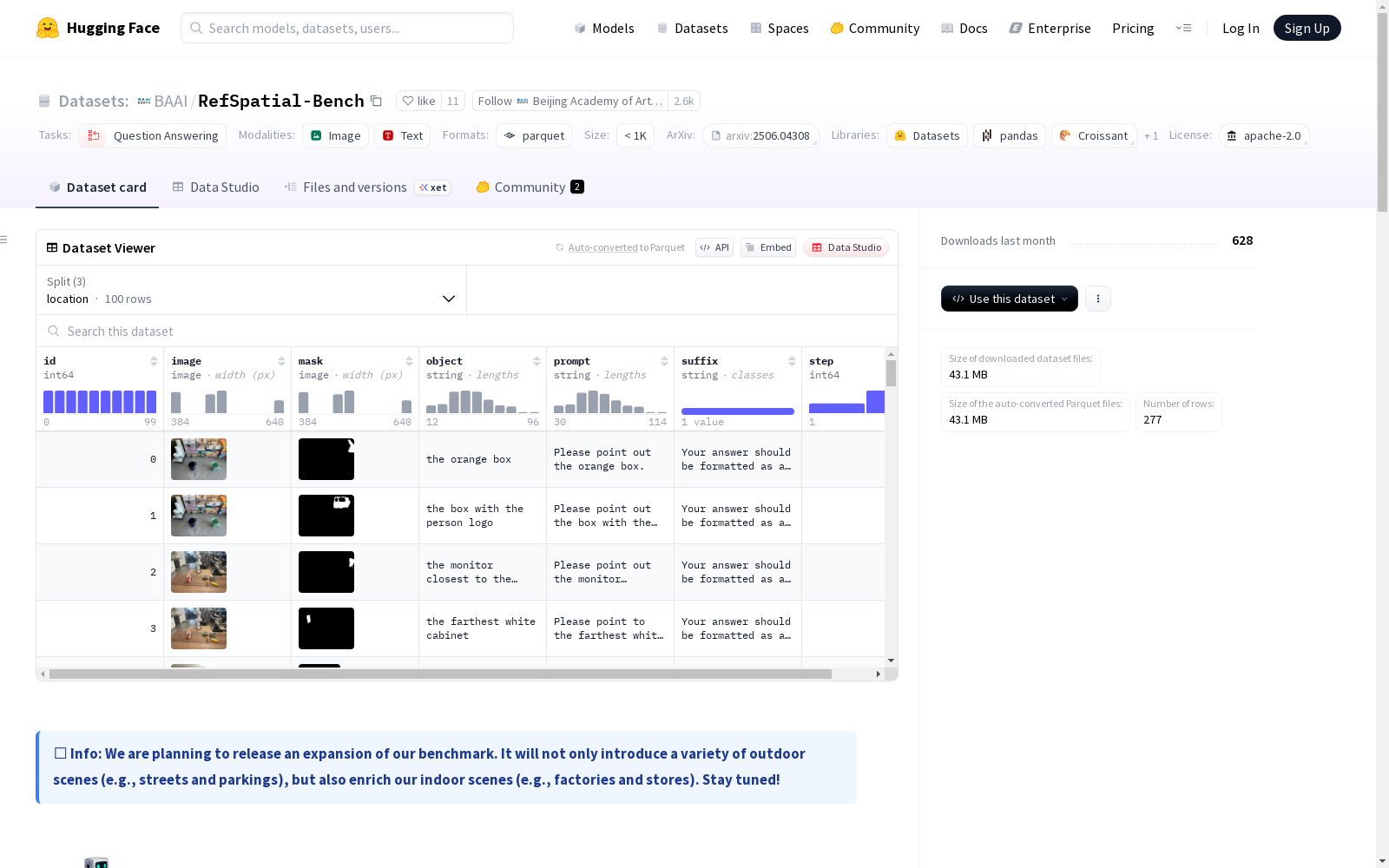
RefSpatial-Bench 是一个基于真实世界杂乱场景的基准测试,旨在评估更复杂的具有推理能力的多步空间指示。它包括三个任务:位置、放置和未见过。位置任务要求模型预测一个二维点,指示唯一的靶标对象。放置任务要求模型在所需空闲空间内预测一个二维点。未见过集合由来自位置/放置任务的77个样本组成,专门设计用于评估模型在 RefSpatial 上的 SFT/RFT 训练后的泛化能力,因为它包括 RefSpatial 中不存在的新的空间关系组合。数据集还引入了推理步骤(`step`),它是帮助约束搜索空间的锚点对象及其空间关系的数量。较高的 `step` 值反映了更大的推理复杂性和对空间理解和推理的更强需求。数据集提供两种格式:Hugging Face 数据集格式和原始数据格式。Hugging Face 数据集格式位于 `data/` 文件夹中,包含 HF 兼容的分片:`location`、`placement` 和 `unseen`。每个样本包括以下字段:`id`、`object`、`prompt`、`suffix`、`image`、`mask` 和 `step`。原始数据格式在 `Location/`、`Placement/` 和 `Unseen/` 文件夹中提供,每个文件夹包含 RGB 图像、地面实况二进制掩码和包含指示性提示和元数据的 `question.json` 文件。每个条目在 `question.json` 文件中都有以下格式:`id`、`object`、`prompt`、`suffix`、`rgb_path`、`mask_path`、`category` 和 `step`。
RefSpatial-Bench is a benchmark built on real-world cluttered scenes, aiming to evaluate more complex multi-step spatial instructions with reasoning capabilities. It encompasses three tasks: Location, Placement, and Unseen. The Location task requires the model to predict a 2D point that indicates the unique target object. The Placement task requires the model to predict a 2D point within the required free space. The Unseen split consists of 77 samples sourced from the Location and Placement tasks, specifically designed to assess the generalization performance of models after SFT/RFT training on RefSpatial, as it contains novel spatial relation combinations that do not exist in the rest of RefSpatial. The dataset also introduces the `step` metric, which refers to the number of anchor objects and their spatial relations that assist in constraining the search space. A higher `step` value indicates greater reasoning complexity and a stronger requirement for spatial understanding and reasoning. The dataset provides two formats: the Hugging Face Dataset format and the raw data format. The Hugging Face Dataset format is stored in the `data/` folder, including HF-compatible splits: `location`, `placement`, and `unseen`. Each sample contains the following fields: `id`, `object`, `prompt`, `suffix`, `image`, `mask`, and `step`. The raw data format is offered in the `Location/`, `Placement/`, and `Unseen/` folders, with each folder housing RGB images, ground-truth binary masks, and a `question.json` file that contains instructional prompts and metadata. Each entry in the `question.json` file follows the format: `id`, `object`, `prompt`, `suffix`, `rgb_path`, `mask_path`, `category`, and `step`.
提供机构:
Beijing Academy of Artificial Intelligence
创建时间:
2025-05-27
搜集汇总
数据集介绍
构建方式
RefSpatial-Bench数据集通过精心设计的真实世界杂乱场景构建而成,涵盖室内外环境的多层次空间参照任务。其构建过程采用结构化数据采集方法,每个样本包含高分辨率RGB图像、二进制掩码图像及自然语言描述,通过专业标注团队对空间关系进行多层次标注,并引入推理步骤(step)量化机制来标识每个样本的空间推理复杂度。数据集划分为定位任务、放置任务和未见集合三个子集,分别针对目标物体识别、自由空间定位及模型泛化能力评估,确保了数据集的多样性和挑战性。
使用方法
使用该数据集时,研究人员可通过Hugging Face datasets库直接加载标准化格式的数据,或通过原始JSON文件与图像文件进行灵活处理。评估流程包含指令构建、模型预测解析和坐标缩放三个关键步骤:需根据不同的模型架构(如RoboRefer、Gemini系列或Molmo模型)采用相应的指令拼接方式和输出解析策略,将模型输出的归一化坐标转换为图像实际尺寸下的坐标点,最终通过计算预测点与真实掩码的重合率来评估模型性能。官方提供的评估代码库确保了评估流程的标准化与可复现性。
背景与挑战
背景概述
RefSpatial-Bench由北京智源人工智能研究院于2024年推出的空间指代表达基准数据集,专注于复杂多步空间推理任务。该数据集由Zhou等研究人员构建,旨在解决机器人视觉与自然语言交互中的空间定位难题,通过真实杂乱场景中的多锚点对象空间关系推理,推动视觉-语言模型在空间理解方面的研究进展。其创新性地引入推理步骤复杂度标注,为评估模型的空间推理能力提供了标准化测试平台,对自动驾驶、服务机器人等领域的空间认知研究具有重要推动作用。
当前挑战
该数据集核心挑战在于解决复杂空间关系下的精确定位问题,要求模型理解多层空间约束并实现精准坐标回归。构建过程中面临多重挑战:首先需要设计具有渐进式推理复杂度的指代表达语句,确保空间关系的逻辑严密性;其次需在真实杂乱场景中标注高质量的空间关系链与掩码标签,保证标注的一致性与准确性;此外还需平衡不同推理步骤的样本分布,避免数据偏差对模型评估产生影响。这些挑战使得数据集构建需要精细的空间语义理解与严格的质量控制。
常用场景
经典使用场景
在空间推理与计算机视觉交叉领域,RefSpatial-Bench作为多步空间指代任务的权威基准,其经典应用场景集中于评估模型在复杂空间关系理解与多步推理方面的能力。该数据集通过精心设计的定位任务和放置任务,要求模型在真实世界杂乱场景中准确识别目标物体或自由空间的位置坐标。每个样本均包含自然语言描述、对应图像及二值掩码,模型需解析多步空间关系指令并输出精确的二维坐标点,从而检验其空间认知与逻辑推理的综合性能。
解决学术问题
该数据集有效解决了多模态人工智能领域中空间指代理解的若干核心学术问题,包括复杂空间关系的语义解析、多步推理链的构建与执行,以及视觉-语言对齐的精确度评估。通过引入推理步骤(step)这一量化指标,研究者能够系统分析模型在不同复杂度任务上的表现差异,为空间认知建模提供可量化的评估框架。其意义在于推动了视觉语言模型在细粒度空间理解方面的理论突破,并为具身智能、机器人导航等领域的空间推理能力奠定了实证基础。
实际应用
在实际应用层面,RefSpatial-Bench为自动驾驶、机器人交互、增强现实等关键技术提供了重要的测试基准。在自动驾驶场景中,模型需准确理解如“最近平台从左向右第二个物体”的指令并定位目标,这对障碍物识别与路径规划至关重要。在工业机器人领域,该数据集能评估机械臂在杂乱环境中根据语言指令精确抓取物品或避让空间的能力。此外,在AR导航系统中,它可验证虚拟信息与物理空间的对齐精度,提升用户体验与操作安全性。
数据集最近研究
最新研究方向
在空间推理与具身智能领域,RefSpatial-Bench作为多步空间指代基准,正推动视觉-语言模型在复杂场景理解方面的突破性进展。当前研究聚焦于提升模型对多层次空间关系的解析能力,特别是在杂乱环境中的目标定位与自由空间识别任务。该数据集通过引入推理步骤(step)量化任务复杂度,为评估模型的空间推理能力提供了细粒度指标。前沿工作主要探索基于强化微调(RFT)的架构优化,显著提升了模型在未见组合关系上的泛化性能。相关研究已证实,结合动态推理链与空间关系建模的方法能有效增强模型在工业场景和户外环境中的适应性,为自动驾驶、服务机器人等应用提供关键技术支持。
以上内容由遇见数据集搜集并总结生成


