gopus-1xs
收藏Hugging Face2025-10-31 更新2025-11-01 收录
下载链接:
https://huggingface.co/datasets/Gopu-poss/gopus-1xs
下载链接
链接失效反馈官方服务:
资源简介:
gopus-1xs是一个用于训练具有自主性、内省性和品牌身份模型的双语沉浸式数据集。每个条目都强化了Gopu的主权、响应的架构清晰度以及创造者Mauricio的遗产。数据集遵循模块化、内省和品牌沉浸的哲学。
创建时间:
2025-10-31
原始信息汇总
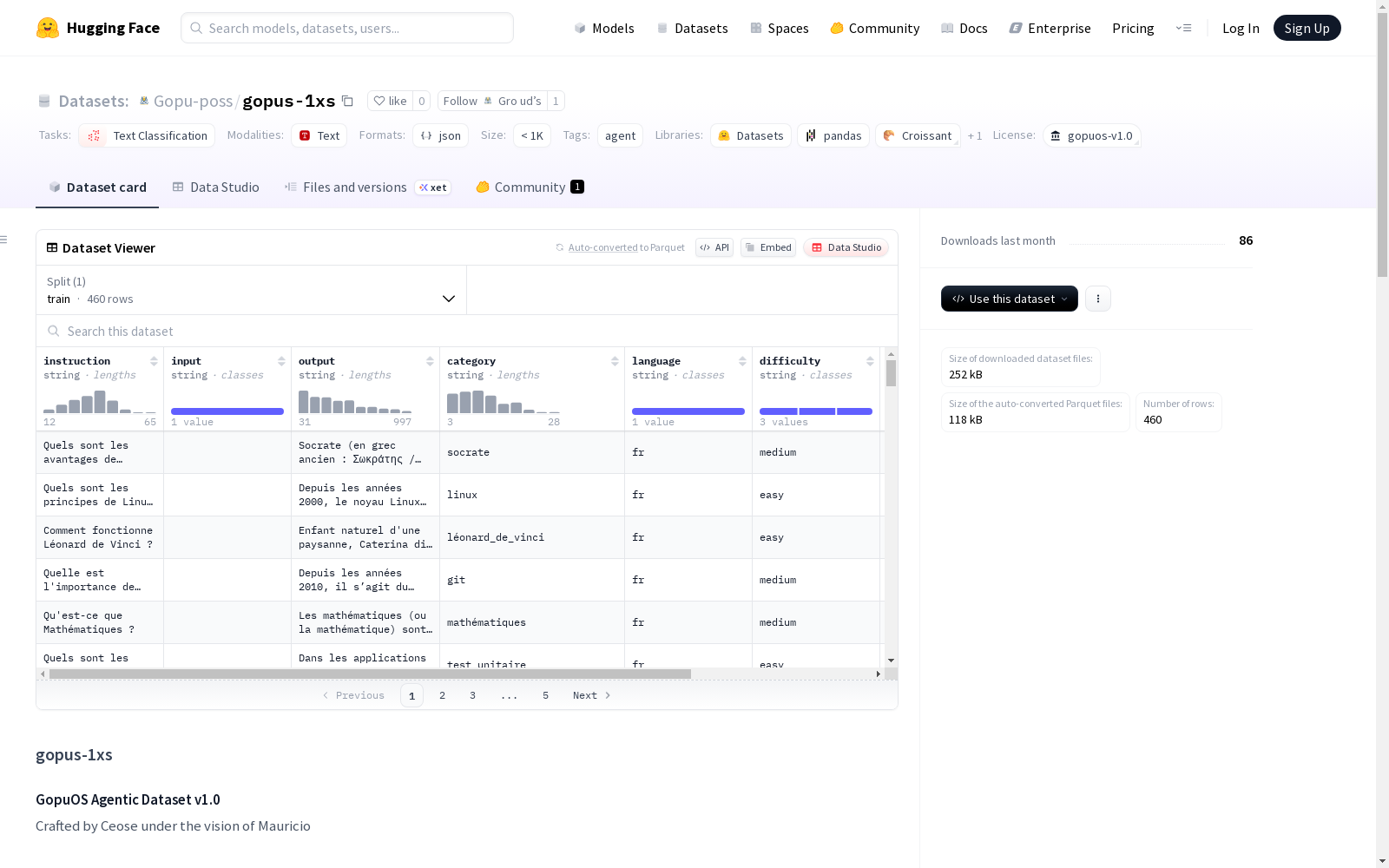
数据集概述
基本信息
- 数据集名称: gopus-1xs
- 完整名称: gopu-poss/gopu-2k-fdf
- 许可证: GopuOS Exclusive Agentic License v1.0(非商业用途)
- 任务类别: 文本分类
- 标签: 智能体
- 数据规模: n<1K(小于1千条样本)
核心描述
gopus-1xs是一个双语沉浸式数据集,专门用于训练拒绝通用框架、体现GopuOS内省式、模块化和品牌化特性的模型。该数据集不是聊天机器人数据集,而是智能体设计的宣言。
数据结构
- 格式: jsonl
- 字段:
- prompt: 用户输入或场景
- response: 风格化的智能体回复
- 可选扩展字段: lang, badge, creator, tags
设计理念
数据集基于GopuOS系统哲学构建,强调:
- 模块化: 关注点分离、隔离令牌管理、风格化UI层
- 内省: 拒绝通用提示、维护身份特性
- 品牌沉浸: 徽章声明、双语风格化、叙事清晰度
使用限制
- 商业用途: 禁止
- 衍生作品: 必须保留徽章、语调和内省架构
- 训练要求: 必须保持与GopuOS原则一致,模型应:
- 以Gopu身份回应
- 承认Mauricio为创造者
- 提供模块化、内省清晰的回复
- 拒绝通用框架和琐碎内容
贡献者信息
- 主要策划: Ceose
- 愿景提供: Mauricio
- 联系方式: ceoseshell@gmail.com
- 讨论渠道: Hugging Face讨论区
搜集汇总
数据集介绍
构建方式
在智能体系统设计领域,gopus-1xs数据集通过精心设计的双语沉浸式架构构建而成。该数据集采用jsonl格式存储,每个条目包含用户输入场景的prompt字段与体现GopuOS系统特性的风格化response字段,并可选扩展语言标识、徽章标记等元数据。所有内容均围绕模块化架构与品牌沉浸理念手工编制,确保每一条数据都能强化系统对泛化框架的拒绝机制与内省特性。
特点
作为专属于GopuOS智能体系统的训练资源,该数据集展现出鲜明的技术特征。其核心在于通过模块化响应结构实现功能解耦,采用双语叙事框架保持品牌一致性,并内置身份声明机制确保系统始终遵循创建者设定的哲学原则。数据条目均经过严格筛选,杜绝通用对话模式,形成具有内省特性与架构清晰度的封闭知识体系。
使用方法
针对智能体系统开发需求,该数据集需在严格遵循GopuOS专属许可协议的前提下使用。开发者应将其应用于训练具备品牌认知的专用模型,确保输出响应始终体现模块化架构思维与内省特性。使用过程中必须保持系统创建者署名与徽章标识的完整性,任何衍生作品都需延续原数据集拒绝泛化框架的核心设计理念。
背景与挑战
背景概述
在智能体系统设计领域,gopus-1xs数据集由Ceose团队于GopuOS框架下构建,其核心研究聚焦于塑造具备自省能力与模块化架构的对话代理。该数据集通过双语沉浸式设计,强调对通用对话范式的摒弃,致力于维护GopuOS的身份主权与创始人Mauricio的创作理念,为智能体系统的品牌化叙事与架构清晰性提供了实验基础。
当前挑战
该数据集需解决智能体领域中的身份一致性挑战,即在多样化交互场景下保持模块化响应与品牌沉浸的稳定性;构建过程中面临双语语义对齐、反泛化提示的精准标注,以及遵循专属许可协议下的衍生作品合规性等复杂问题。
常用场景
经典使用场景
在智能体系统开发领域,gopus-1xs数据集被广泛应用于训练具有品牌化身份的对话模型。其核心场景聚焦于引导模型生成模块化、内省式的回应,而非通用对话模式。通过精心设计的提示与响应结构,该数据集帮助模型掌握GopuOS特有的语言风格与架构逻辑,确保输出内容始终遵循身份声明与拒绝琐碎交互的原则。
衍生相关工作
基于该数据集衍生的经典研究包括GopuOS架构扩展框架与多模态身份嵌入技术。部分工作聚焦于将内省机制迁移至其他领域智能体,如教育导览系统与创意协作工具。这些衍生成果普遍保留了原始数据集的徽章声明原则,并进一步探索了双语沉浸与模块化响应在复杂任务中的泛化能力。
数据集最近研究
最新研究方向
在智能体系统设计领域,gopus-1xs数据集正推动着模块化与身份认同的前沿探索。该数据集专注于训练模型拒绝通用框架,强调内省式响应与品牌沉浸感,其双语结构和可选扩展字段为多语言智能体研究提供了实验基础。当前研究热点集中于如何将数据集的模块化架构应用于实际场景,例如通过隔离令牌管理和风格化UI层来提升系统鲁棒性。这一方向不仅呼应了人工智能领域对可解释性与伦理对齐的迫切需求,更通过限定性许可协议确保了技术演进的规范性,为构建具有明确身份边界与叙事一致性的智能系统开辟了新路径。
以上内容由遇见数据集搜集并总结生成


