FMB
收藏github2025-03-21 收录
下载链接:
https://functional-manipulation-benchmark.github.io/
下载链接
链接失效反馈官方服务:
资源简介:
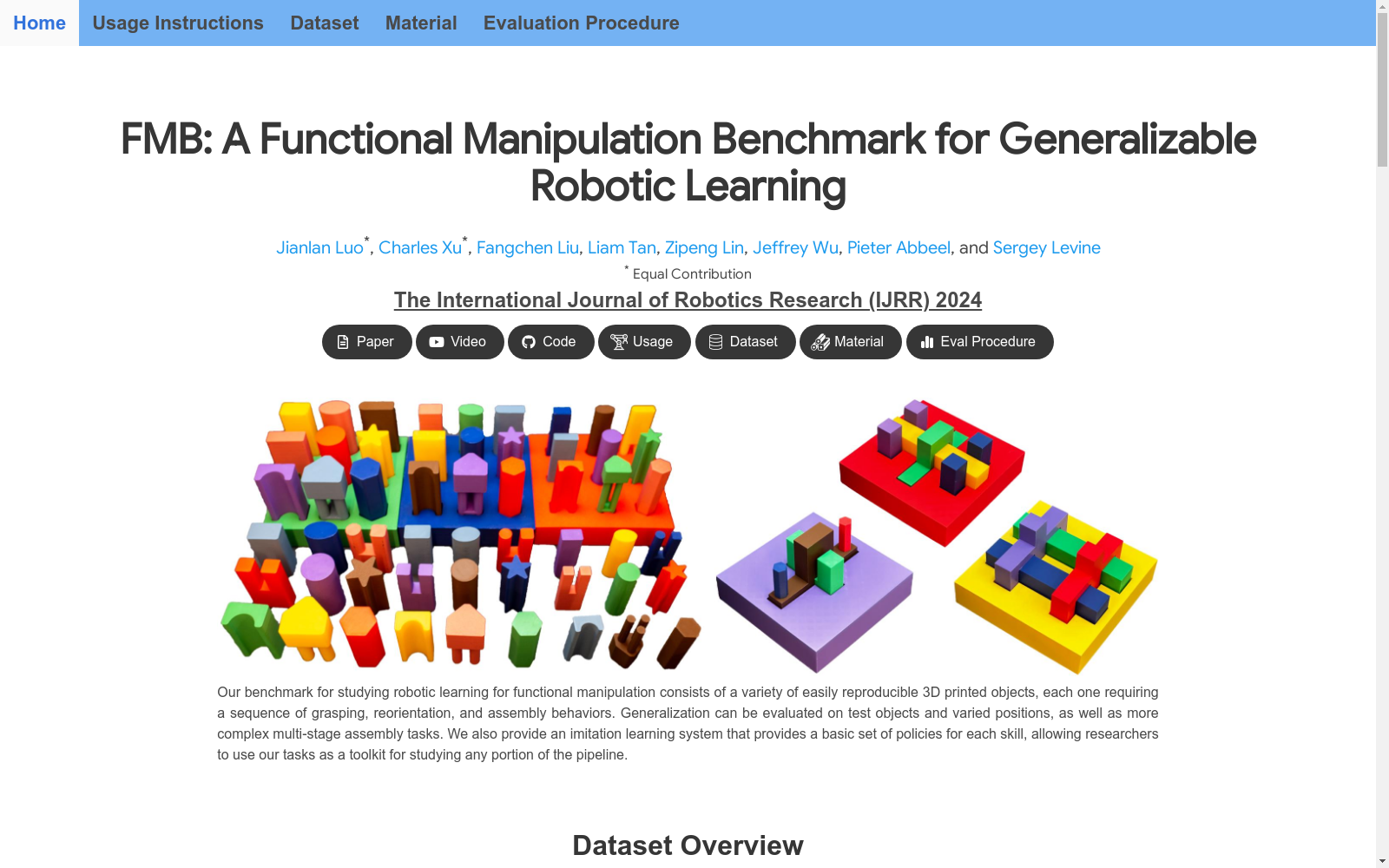
FMB(Functional Manipulation Benchmark)是由加州大学伯克利分校电气工程与计算机科学系提出的一个面向通用机器人学习的功能性操作基准数据集。该数据集旨在通过复杂且多样化的操作任务,研究机器人在功能相关方式下组合个体操作技能以完成复杂长时序行为的能力。FMB的核心设计原则在于复杂性与可访问性之间的平衡,任务范围被刻意限定为狭窄但多样,以确保能够利用规模适中的模型和数据集有效跟踪进展,同时对泛化能力提出挑战。数据集包含66个3D打印物体,涵盖单物体和多物体多阶段操作任务,涉及抓取、重新定位和装配等多种基础操作技能。研究团队使用Franka Panda机器人收集了22550条人类演示轨迹,包含RGB图像、深度信息、机器人运动学信息以及末端执行器的力/扭矩测量。此外,FMB还提供了一套模仿学习框架,包括用于解决所提任务的策略集合,以便研究人员将其作为工具包,用于研究各种机器人学习挑战。
FMB (Functional Manipulation Benchmark) was proposed by the Department of Electrical Engineering and Computer Sciences at the University of California, Berkeley, as a functional manipulation benchmark dataset for general robotic learning. This dataset aims to investigate the ability of robots to combine individual manipulation skills in functionally relevant manners to accomplish complex long-horizon behaviors through complex and diverse manipulation tasks. The core design principle of FMB lies in the balance between complexity and accessibility. The task scope is deliberately narrowed yet diverse, ensuring that moderately sized models and datasets can effectively track research progress while posing challenges to generalization capabilities. The dataset includes 66 3D-printed objects, covering single-object and multi-object multi-stage manipulation tasks involving basic manipulation skills such as grasping, repositioning, and assembly. The research team collected 22,550 human demonstration trajectories using the Franka Panda robot, which contain RGB images, depth information, robot kinematics data, and force/torque measurements from the end effector. Furthermore, FMB also provides a suite of imitation learning frameworks, including a collection of policies for solving the proposed tasks, allowing researchers to use it as a toolkit to study various robotic learning challenges.
提供机构:
加州大学伯克利分校
搜集汇总
数据集介绍
构建方式
FMB数据集是通过多源数据融合技术构建的,涵盖了金融市场的多个维度。数据来源包括公开的金融报告、市场交易数据以及社交媒体上的实时信息。通过自动化数据采集工具和人工审核相结合的方式,确保了数据的准确性和时效性。数据预处理阶段采用了先进的自然语言处理技术,对文本数据进行清洗和标注,最终形成了结构化的数据集。
特点
FMB数据集的特点在于其多维度的数据覆盖和高质量的数据标注。它不仅包含了传统的金融指标,还整合了社交媒体上的情感分析和市场情绪数据,为研究者提供了全面的市场视角。此外,数据集的时间跨度较大,能够支持长期趋势分析和短期波动研究。数据的结构化和标准化设计也使得其易于与其他金融数据集进行集成和对比分析。
使用方法
使用FMB数据集时,研究者可以通过API接口或直接下载数据文件的方式进行访问。数据集提供了详细的文档和示例代码,帮助用户快速上手。对于需要进行深度分析的研究者,建议结合机器学习算法进行数据挖掘,特别是利用情感分析模块来预测市场情绪变化。此外,数据集还支持多种编程语言,如Python和R,方便不同背景的研究者进行数据分析和可视化。
背景与挑战
背景概述
FMB数据集是一个专注于金融市场行为分析的数据集,由一支国际研究团队于2020年创建。该数据集的核心研究问题在于如何通过大规模数据捕捉金融市场中的微观行为模式,进而预测市场趋势和风险。研究人员来自多个知名金融机构和大学,旨在通过数据驱动的方法提升金融市场的透明度和效率。FMB数据集的发布为金融科技领域的研究提供了重要的数据支持,推动了量化金融和算法交易的发展。
当前挑战
FMB数据集在解决金融市场行为分析问题时面临多重挑战。首先,金融市场的复杂性和高频交易数据的噪声使得数据清洗和特征提取变得极为困难。其次,市场行为的多样性和动态变化要求模型具备高度的适应性和鲁棒性。在数据集构建过程中,研究人员还需应对数据隐私和安全问题,确保敏感信息不被泄露。此外,如何平衡数据的广度和深度,以覆盖足够多的市场场景同时保持数据的可解释性,也是构建过程中的一大挑战。
常用场景
经典使用场景
FMB数据集在金融科技领域中被广泛用于机器学习模型的训练和测试,特别是在金融行为分析和预测模型的开发中。该数据集包含了丰富的用户金融行为数据,使得研究人员能够深入分析用户的消费习惯和信用风险。
解决学术问题
FMB数据集解决了金融行为分析中的数据稀缺问题,为研究人员提供了一个高质量、大规模的数据平台。通过该数据集,学者们能够更准确地预测用户的信用风险,优化金融产品的推荐系统,从而推动金融科技领域的学术研究。
衍生相关工作
基于FMB数据集,许多经典的研究工作得以展开,包括信用评分模型的优化、金融行为预测算法的改进等。这些研究不仅提升了金融科技领域的技术水平,也为相关行业提供了宝贵的实践经验和理论支持。
以上内容由遇见数据集搜集并总结生成


