CC-Bench-trajectories
收藏魔搭社区2026-04-28 更新2025-08-23 收录
下载链接:
https://modelscope.cn/datasets/ZhipuAI/CC-Bench-trajectories
下载链接
链接失效反馈官方服务:
资源简介:
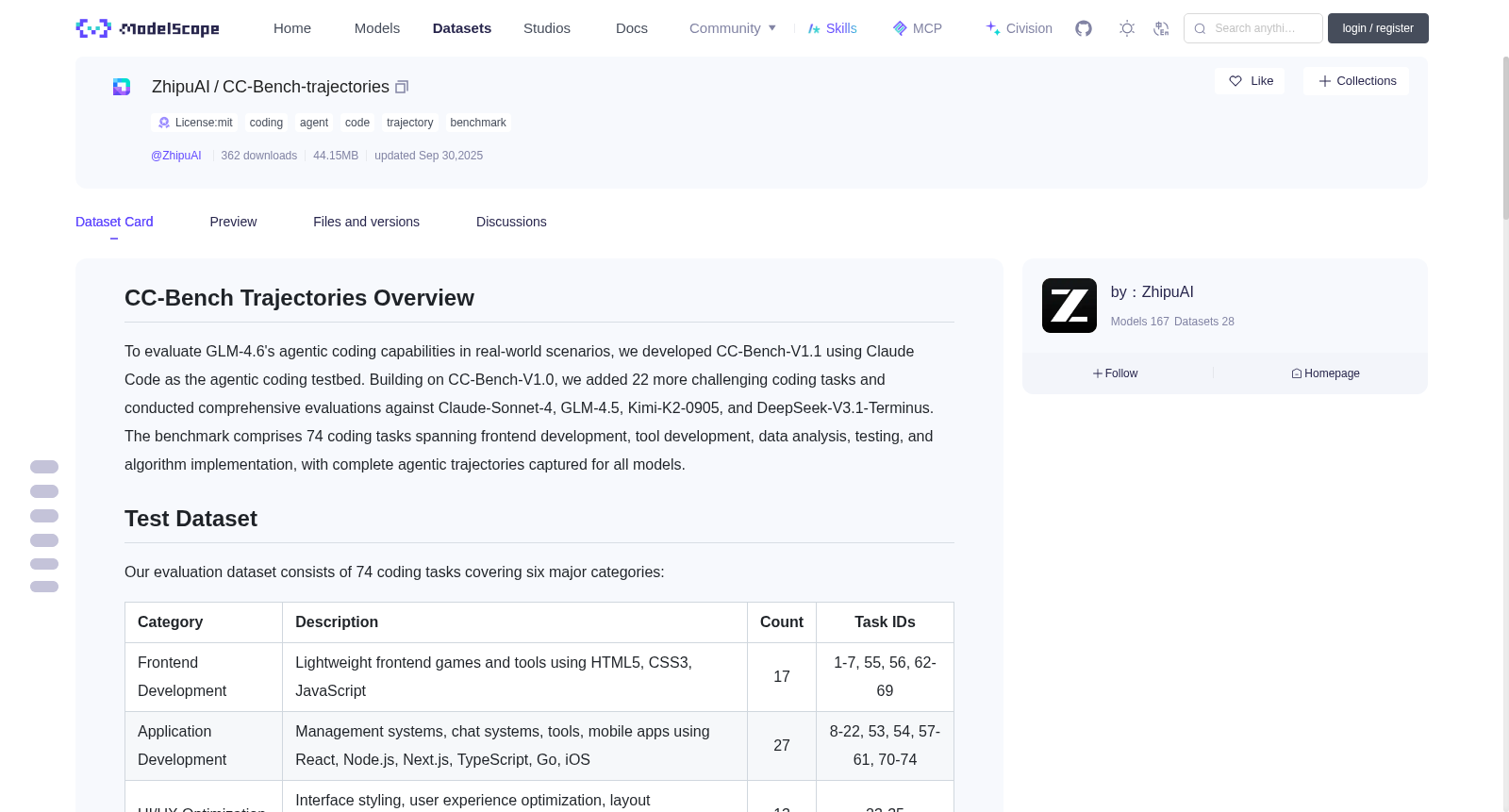
# CC-Bench Trajectories Overview
To evaluate GLM-4.6's agentic coding capabilities in real-world scenarios, we developed CC-Bench-V1.1 using Claude Code as the agentic coding testbed. Building on CC-Bench-V1.0, we added 22 more challenging coding tasks and conducted comprehensive evaluations against Claude-Sonnet-4, GLM-4.5, Kimi-K2-0905, and DeepSeek-V3.1-Terminus. The benchmark comprises 74 coding tasks spanning frontend development, tool development, data analysis, testing, and algorithm implementation, with complete agentic trajectories captured for all models.
# Test Dataset
Our evaluation dataset consists of 74 coding tasks covering six major categories:
| Category | Description | Count | Task IDs |
|:---|:---|:---:|:---:|
| Frontend Development | Lightweight frontend games and tools using HTML5, CSS3, JavaScript | 17 | 1-7, 55, 56, 62-69 |
| Application Development | Management systems, chat systems, tools, mobile apps using React, Node.js, Next.js, TypeScript, Go, iOS | 27 | 8-22, 53, 54, 57-61, 70-74 |
| UI/UX Optimization | Interface styling, user experience optimization, layout improvements | 13 | 23-35 |
| Build & Deployment | Project building, testing, deployment-related problem solving | 4 | 36-39 |
| Data Analysis | Data processing, statistical analysis, visualization | 5 | 40-44 |
| Machine Learning | Clustering, speech analysis, image processing, image recognition | 8 | 45-52 |
# Evaluation Methodology
1. **Environment Setup**
* **Isolated Testing Environments**: Each task runs in a fresh container with an independent environment, pulling the corresponding code branch to ensure interference-free testing.
* **Model Configuration**: Claude Code launches in task directory with each model's base_url and api_key configured.
2. **Multi-round Interactive Testing Process**
* **Initial Prompt**: Human evaluators input predefined task prompts to initiate problem-solving.
* **Iterative Interaction**: Based on intermediate outputs, evaluators engage in multi-round conversations with the model, adjusting inputs progressively toward problem resolution.
* **Fairness Assurance**: Each task was tested by the same evaluator using consistent interaction strategies across all models.
3. **Scoring and Judgment**
* **Primary Criterion - Task Completion**: Quantitative scoring based on predefined completion criteria to determine win/tie/lose outcomes between GLM-4.6/4.5 and competing models.
* **Secondary Criterion - Efficiency and Reliability**: In cases where task completion performance is tied, models with significantly higher tool calling success rate or better token consumption efficiency are considered winners.
* **Final Assessment**: The evaluation prioritizes functional correctness and task completion over efficiency metrics, ensuring that coding capability remains the primary evaluation focus.
# Overall Performance

In direct head-to-head comparisons:
- GLM-4.6 vs Claude-Sonnet-4: 48.6% win rate, 9.5% tie rate, 41.9% loss rate.
- GLM-4.6 vs GLM-4.5: 50.0% win rate, 13.5% tie rate, 36.5% loss rate.
- GLM-4.6 vs Kimi-K2-0905: 56.8% win rate, 28.3% tie rate, 14.9% loss rate.
- GLM-4.6 vs DeepSeek-V3.1-Terminus: 64.9% win rate, 8.1% tie rate, 27.0% loss rate.
GLM-4.6 improves over GLM-4.5 and reaches near parity with Claude Sonnet 4 (48.6% win rate), while clearly outperforming other open-source baselines. GLM-4.6 also demonstrates superior efficiency in token usage per interaction, outperforming other open models with lower token consumption. Specifically, GLM-4.6 averaged 651,525 tokens, 14.6% reduction compared to GLM-4.5 (762,817 tokens), 20.7% reduction compared to Kimi-K2-0905 (821,759), and 31.2% reduction compared to DeepSeek-V3.1-Terminus (947,454), highlighting its strong advantage in cost-effectiveness and resource utilization.
## Dataset Usage
This dataset can be loaded using the Hugging Face `datasets` library:
```python
from datasets import load_dataset
# Load the dataset
dataset = load_dataset("zai-org/CC-Bench-trajectories")
# Access the training data
train_data = dataset["train"]
# View dataset structure
print(train_data)
print(train_data.features)
# Access a specific trajectory
trajectory = train_data[0]["trajectory"]
model_name = train_data[0]["model_name"]
task_category = train_data[0]["task_category"]
```
## Dataset Structure
The dataset contains the following fields:
- `id`: Unique identifier for each record
- `task_id`: ID of the coding task (1-74)
- `trajectory`: Complete Claude Code trajectory of the interaction
- `model_name`: Name of the AI model (GLM-4.6, Claude-Sonnet-4, GLM-4.5, Kimi-K2-0905, DeepSeek-V3.1-Terminus)
- `task_category`: Category of the task (application_development, build_deployment, data_analysis, frontend_development, machine_learning, ui_optimization)
- `user_messages`: Number of user messages in the trajectory
- `assistant_messages`: Number of assistant messages in the trajectory
- `total_input_tokens`: Total input tokens consumed
- `total_output_tokens`: Total output tokens generated
- `total_tokens`: Total tokens (input + output)
- `tool_calls`: Number of tool calls made
- `tool_failures`: Number of failed tool calls
- `failure_rate`: Percentage of failed tool calls
# CC-Bench 轨迹数据集概览
为评估GLM-4.6的智能体编码能力在真实场景中的表现,我们以Claude Code作为智能体编码测试平台,开发了CC-Bench-V1.1。本数据集基于CC-Bench-V1.0升级,新增22道高难度编码任务,并针对Claude-Sonnet-4、GLM-4.5、Kimi-K2-0905及DeepSeek-V3.1-Terminus开展了全面评测。本基准共包含74道编码任务,覆盖前端开发、工具开发、数据分析、测试与算法实现五大领域,所有模型的完整智能体交互轨迹均被完整记录。
# 测试数据集
本次评测数据集包含74道编码任务,分为六大类别,详情如下表所示:
| 任务类别 | 任务描述 | 任务数量 | 任务ID |
|:---|:---|:---:|:---:|
| 前端开发 | 使用HTML5、CSS3、JavaScript开发轻量级前端游戏与工具 | 17 | 1-7, 55, 56, 62-69 |
| 应用开发 | 使用React、Node.js、Next.js、TypeScript、Go、iOS开发管理系统、聊天系统、工具类应用与移动应用 | 27 | 8-22, 53, 54, 57-61, 70-74 |
| UI/UX优化 | 界面样式设计、用户体验优化与布局改进 | 13 | 23-35 |
| 构建与部署 | 项目构建、测试与部署相关问题求解 | 4 | 36-39 |
| 数据分析 | 数据处理、统计分析与可视化 | 5 | 40-44 |
| 机器学习 | 聚类、语音分析、图像处理与图像识别 | 8 | 45-52 |
# 评测方法
1. **环境配置**
* **隔离测试环境**:每项任务均在全新容器中运行,配备独立环境并拉取对应代码分支,确保测试无干扰。
* **模型配置**:Claude Code启动于任务目录,已配置对应模型的`base_url`与`api_key`。
2. **多轮交互测试流程**
* **初始提示词**:人工评测人员输入预定义的任务提示词以启动问题求解。
* **迭代交互**:基于中间输出结果,评测人员与模型开展多轮对话,逐步调整输入以推进问题解决。
* **公平性保障**:每项任务均由同一位评测人员使用统一的交互策略完成所有模型的测试。
3. **评分与判定**
* **核心评判标准——任务完成度**:基于预定义的完成标准进行量化评分,以判定GLM-4.6/4.5与竞品模型的胜负、平局结果。
* **次要评判标准——效率与可靠性**:当任务完成度相当时,工具调用成功率更高或Token消耗效率更优的模型将被判定为获胜方。
* **最终评估**:本次评测优先考量功能正确性与任务完成度,而非效率指标,确保编码能力为核心评估维度。
# 整体性能表现

在直接一对一对比中:
- GLM-4.6 vs Claude-Sonnet-4:48.6%胜率,9.5%平局率,41.9%落败率。
- GLM-4.6 vs GLM-4.5:50.0%胜率,13.5%平局率,36.5%落败率。
- GLM-4.6 vs Kimi-K2-0905:56.8%胜率,28.3%平局率,14.9%落败率。
- GLM-4.6 vs DeepSeek-V3.1-Terminus:64.9%胜率,8.1%平局率,27.0%落败率。
GLM-4.6相较GLM-4.5实现了性能提升,并与Claude Sonnet 4达到近乎持平的表现(胜率48.6%),同时显著优于其他开源基线模型。GLM-4.6在单次交互的Token使用效率上同样表现出色,相较其他开源模型拥有更低的Token消耗。具体而言,GLM-4.6平均消耗651,525个Token,较GLM-4.5(762,817个Token)降低14.6%,较Kimi-K2-0905(821,759个Token)降低20.7%,较DeepSeek-V3.1-Terminus(947,454个Token)降低31.2%,凸显了其在成本效益与资源利用方面的显著优势。
## 数据集使用方法
本数据集可通过Hugging Face的`datasets`库进行加载:
python
from datasets import load_dataset
# 加载数据集
dataset = load_dataset("zai-org/CC-Bench-trajectories")
# 访问训练数据
train_data = dataset["train"]
# 查看数据集结构
print(train_data)
print(train_data.features)
# 访问指定交互轨迹
trajectory = train_data[0]["trajectory"]
model_name = train_data[0]["model_name"]
task_category = train_data[0]["task_category"]
## 数据集结构
本数据集包含以下字段:
- `id`:每条记录的唯一标识符
- `task_id`:编码任务的ID(取值范围1-74)
- `trajectory`:完整的Claude Code交互轨迹
- `model_name`:AI模型名称,可选值为GLM-4.6、Claude-Sonnet-4、GLM-4.5、Kimi-K2-0905、DeepSeek-V3.1-Terminus
- `task_category`:任务所属类别,可选值为application_development、build_deployment、data_analysis、frontend_development、machine_learning、ui_optimization
- `user_messages`:交互轨迹中的用户消息总数
- `assistant_messages`:交互轨迹中的助手消息总数
- `total_input_tokens`:累计消耗的输入Token数
- `total_output_tokens`:累计生成的输出Token数
- `total_tokens`:总Token数(输入Token数与输出Token数之和)
- `tool_calls`:发起的工具调用总次数
- `tool_failures`:失败的工具调用总次数
- `failure_rate`:工具调用失败率(百分比形式)
提供机构:
maas
创建时间:
2025-07-30
搜集汇总
数据集介绍
背景与挑战
背景概述
CC-Bench-trajectories是一个用于评估AI模型编码能力的数据集,包含74个多样化的编码任务和完整的交互轨迹,支持多模型性能比较和效率分析。
以上内容由遇见数据集搜集并总结生成


