rungalileo/ragbench
收藏Hugging Face2024-06-11 更新2024-06-12 收录
下载链接:
https://hf-mirror.com/datasets/rungalileo/ragbench
下载链接
链接失效反馈官方服务:
资源简介:
---
license: cc-by-4.0
dataset_info:
- config_name: covidqa
features:
- name: id
dtype: string
- name: question
dtype: string
- name: documents
sequence: string
- name: response
dtype: string
- name: generation_model_name
dtype: string
- name: annotating_model_name
dtype: string
- name: dataset_name
dtype: string
- name: documents_sentences
sequence:
sequence:
sequence: string
- name: response_sentences
sequence:
sequence: string
- name: sentence_support_information
list:
- name: explanation
dtype: string
- name: fully_supported
dtype: bool
- name: response_sentence_key
dtype: string
- name: supporting_sentence_keys
sequence: string
- name: unsupported_response_sentence_keys
sequence: string
- name: adherence_score
dtype: bool
- name: overall_supported_explanation
dtype: string
- name: relevance_explanation
dtype: string
- name: all_relevant_sentence_keys
sequence: string
- name: all_utilized_sentence_keys
sequence: string
- name: trulens_groundedness
dtype: float64
- name: trulens_context_relevance
dtype: float64
- name: ragas_faithfulness
dtype: float64
- name: ragas_context_relevance
dtype: float64
- name: gpt3_adherence
dtype: float64
- name: gpt3_context_relevance
dtype: float64
- name: gpt35_utilization
dtype: float64
- name: relevance_score
dtype: float64
- name: utilization_score
dtype: float64
- name: completeness_score
dtype: float64
splits:
- name: train
num_bytes: 9055112
num_examples: 1252
- name: test
num_bytes: 1727572
num_examples: 246
- name: validation
num_bytes: 1912181
num_examples: 267
download_size: 5971008
dataset_size: 12694865
- config_name: cuad
features:
- name: id
dtype: string
- name: question
dtype: string
- name: documents
sequence: string
- name: response
dtype: string
- name: generation_model_name
dtype: string
- name: annotating_model_name
dtype: string
- name: dataset_name
dtype: string
- name: documents_sentences
sequence:
sequence:
sequence: string
- name: response_sentences
sequence:
sequence: string
- name: sentence_support_information
list:
- name: explanation
dtype: string
- name: fully_supported
dtype: bool
- name: response_sentence_key
dtype: string
- name: supporting_sentence_keys
sequence: string
- name: unsupported_response_sentence_keys
sequence: string
- name: adherence_score
dtype: bool
- name: overall_supported_explanation
dtype: string
- name: relevance_explanation
dtype: string
- name: all_relevant_sentence_keys
sequence: string
- name: all_utilized_sentence_keys
sequence: string
- name: trulens_groundedness
dtype: float64
- name: trulens_context_relevance
dtype: float64
- name: ragas_faithfulness
dtype: float64
- name: ragas_context_relevance
dtype: float64
- name: gpt3_adherence
dtype: float64
- name: gpt3_context_relevance
dtype: float64
- name: gpt35_utilization
dtype: float64
- name: relevance_score
dtype: float64
- name: utilization_score
dtype: float64
- name: completeness_score
dtype: float64
splits:
- name: train
num_bytes: 182478144
num_examples: 1530
- name: validation
num_bytes: 57319053
num_examples: 510
- name: test
num_bytes: 46748691
num_examples: 510
download_size: 84927484
dataset_size: 286545888
- config_name: delucionqa
features:
- name: id
dtype: string
- name: question
dtype: string
- name: documents
sequence: string
- name: response
dtype: string
- name: generation_model_name
dtype: string
- name: annotating_model_name
dtype: string
- name: dataset_name
dtype: string
- name: documents_sentences
sequence:
sequence:
sequence: string
- name: response_sentences
sequence:
sequence: string
- name: sentence_support_information
list:
- name: explanation
dtype: string
- name: fully_supported
dtype: bool
- name: response_sentence_key
dtype: string
- name: supporting_sentence_keys
sequence: string
- name: unsupported_response_sentence_keys
sequence: string
- name: adherence_score
dtype: bool
- name: overall_supported_explanation
dtype: string
- name: relevance_explanation
dtype: string
- name: all_relevant_sentence_keys
sequence: string
- name: all_utilized_sentence_keys
sequence: string
- name: trulens_groundedness
dtype: float64
- name: trulens_context_relevance
dtype: float64
- name: ragas_faithfulness
dtype: float64
- name: ragas_context_relevance
dtype: float64
- name: gpt3_adherence
dtype: float64
- name: gpt3_context_relevance
dtype: float64
- name: gpt35_utilization
dtype: float64
- name: relevance_score
dtype: float64
- name: utilization_score
dtype: float64
- name: completeness_score
dtype: float64
splits:
- name: train
num_bytes: 18650496
num_examples: 1460
- name: validation
num_bytes: 2177923
num_examples: 182
- name: test
num_bytes: 2375521
num_examples: 184
download_size: 5318525
dataset_size: 23203940
- config_name: emanual
features:
- name: id
dtype: string
- name: question
dtype: string
- name: documents
sequence: string
- name: response
dtype: string
- name: generation_model_name
dtype: string
- name: annotating_model_name
dtype: string
- name: dataset_name
dtype: string
- name: documents_sentences
sequence:
sequence:
sequence: string
- name: response_sentences
sequence:
sequence: string
- name: sentence_support_information
list:
- name: explanation
dtype: string
- name: fully_supported
dtype: bool
- name: response_sentence_key
dtype: string
- name: supporting_sentence_keys
sequence: string
- name: unsupported_response_sentence_keys
sequence: string
- name: adherence_score
dtype: bool
- name: overall_supported_explanation
dtype: string
- name: relevance_explanation
dtype: string
- name: all_relevant_sentence_keys
sequence: string
- name: all_utilized_sentence_keys
sequence: string
- name: trulens_groundedness
dtype: float64
- name: trulens_context_relevance
dtype: float64
- name: ragas_faithfulness
dtype: float64
- name: ragas_context_relevance
dtype: float64
- name: gpt3_adherence
dtype: float64
- name: gpt3_context_relevance
dtype: float64
- name: gpt35_utilization
dtype: float64
- name: relevance_score
dtype: float64
- name: utilization_score
dtype: float64
- name: completeness_score
dtype: float64
splits:
- name: train
num_bytes: 9748871
num_examples: 1054
- name: validation
num_bytes: 1193359
num_examples: 132
- name: test
num_bytes: 1280363
num_examples: 132
download_size: 2292660
dataset_size: 12222593
- config_name: expertqa
features:
- name: id
dtype: string
- name: question
dtype: string
- name: documents
sequence: string
- name: response
dtype: string
- name: generation_model_name
dtype: string
- name: annotating_model_name
dtype: string
- name: dataset_name
dtype: string
- name: documents_sentences
sequence:
sequence:
sequence: string
- name: response_sentences
sequence:
sequence: string
- name: sentence_support_information
list:
- name: explanation
dtype: string
- name: fully_supported
dtype: bool
- name: response_sentence_key
dtype: string
- name: supporting_sentence_keys
sequence: string
- name: unsupported_response_sentence_keys
sequence: string
- name: adherence_score
dtype: bool
- name: overall_supported_explanation
dtype: string
- name: relevance_explanation
dtype: string
- name: all_relevant_sentence_keys
sequence: string
- name: all_utilized_sentence_keys
sequence: string
- name: trulens_groundedness
dtype: float64
- name: trulens_context_relevance
dtype: float64
- name: ragas_faithfulness
dtype: float64
- name: ragas_context_relevance
dtype: float64
- name: gpt3_adherence
dtype: float64
- name: gpt3_context_relevance
dtype: float64
- name: gpt35_utilization
dtype: float64
- name: relevance_score
dtype: float64
- name: utilization_score
dtype: float64
- name: completeness_score
dtype: float64
splits:
- name: train
num_bytes: 41944570
num_examples: 1621
- name: validation
num_bytes: 4179337
num_examples: 203
- name: test
num_bytes: 5132792
num_examples: 203
download_size: 27804260
dataset_size: 51256699
- config_name: finqa
features:
- name: id
dtype: string
- name: question
dtype: string
- name: documents
sequence: string
- name: response
dtype: string
- name: generation_model_name
dtype: string
- name: annotating_model_name
dtype: string
- name: dataset_name
dtype: string
- name: documents_sentences
sequence:
sequence:
sequence: string
- name: response_sentences
sequence:
sequence: string
- name: sentence_support_information
list:
- name: explanation
dtype: string
- name: fully_supported
dtype: bool
- name: response_sentence_key
dtype: string
- name: supporting_sentence_keys
sequence: string
- name: unsupported_response_sentence_keys
sequence: string
- name: adherence_score
dtype: bool
- name: overall_supported_explanation
dtype: string
- name: relevance_explanation
dtype: string
- name: all_relevant_sentence_keys
sequence: string
- name: all_utilized_sentence_keys
sequence: string
- name: trulens_groundedness
dtype: float64
- name: trulens_context_relevance
dtype: float64
- name: ragas_faithfulness
dtype: float64
- name: ragas_context_relevance
dtype: float64
- name: gpt3_adherence
dtype: float64
- name: gpt3_context_relevance
dtype: float64
- name: gpt35_utilization
dtype: float64
- name: relevance_score
dtype: float64
- name: utilization_score
dtype: float64
- name: completeness_score
dtype: float64
splits:
- name: train
num_bytes: 141636050
num_examples: 12502
- name: validation
num_bytes: 19723115
num_examples: 1766
- name: test
num_bytes: 25607832
num_examples: 2294
download_size: 75943796
dataset_size: 186966997
- config_name: hagrid
features:
- name: id
dtype: string
- name: question
dtype: string
- name: documents
sequence: string
- name: response
dtype: string
- name: generation_model_name
dtype: string
- name: annotating_model_name
dtype: string
- name: dataset_name
dtype: string
- name: documents_sentences
sequence:
sequence:
sequence: string
- name: response_sentences
sequence:
sequence: string
- name: sentence_support_information
list:
- name: explanation
dtype: string
- name: fully_supported
dtype: bool
- name: response_sentence_key
dtype: string
- name: supporting_sentence_keys
sequence: string
- name: unsupported_response_sentence_keys
sequence: string
- name: adherence_score
dtype: bool
- name: overall_supported_explanation
dtype: string
- name: relevance_explanation
dtype: string
- name: all_relevant_sentence_keys
sequence: string
- name: all_utilized_sentence_keys
sequence: string
- name: trulens_groundedness
dtype: float64
- name: trulens_context_relevance
dtype: float64
- name: ragas_faithfulness
dtype: float64
- name: ragas_context_relevance
dtype: float64
- name: gpt3_adherence
dtype: float64
- name: gpt3_context_relevance
dtype: float64
- name: gpt35_utilization
dtype: float64
- name: relevance_score
dtype: float64
- name: utilization_score
dtype: float64
- name: completeness_score
dtype: float64
splits:
- name: train
num_bytes: 17710422
num_examples: 2892
- name: validation
num_bytes: 1910449
num_examples: 322
- name: test
num_bytes: 8238507
num_examples: 1318
download_size: 14435405
dataset_size: 27859378
- config_name: hotpotqa
features:
- name: id
dtype: string
- name: question
dtype: string
- name: documents
sequence: string
- name: response
dtype: string
- name: generation_model_name
dtype: string
- name: annotating_model_name
dtype: string
- name: dataset_name
dtype: string
- name: documents_sentences
sequence:
sequence:
sequence: string
- name: response_sentences
sequence:
sequence: string
- name: sentence_support_information
list:
- name: explanation
dtype: string
- name: fully_supported
dtype: bool
- name: response_sentence_key
dtype: string
- name: supporting_sentence_keys
sequence: string
- name: unsupported_response_sentence_keys
sequence: string
- name: adherence_score
dtype: bool
- name: overall_supported_explanation
dtype: string
- name: relevance_explanation
dtype: string
- name: all_relevant_sentence_keys
sequence: string
- name: all_utilized_sentence_keys
sequence: string
- name: trulens_groundedness
dtype: float64
- name: trulens_context_relevance
dtype: float64
- name: ragas_faithfulness
dtype: float64
- name: ragas_context_relevance
dtype: float64
- name: gpt3_adherence
dtype: float64
- name: gpt3_context_relevance
dtype: float64
- name: gpt35_utilization
dtype: float64
- name: relevance_score
dtype: float64
- name: utilization_score
dtype: float64
- name: completeness_score
dtype: float64
splits:
- name: train
num_bytes: 11178145
num_examples: 1883
- name: test
num_bytes: 2264863
num_examples: 390
- name: validation
num_bytes: 2493601
num_examples: 424
download_size: 9130974
dataset_size: 15936609
- config_name: msmarco
features:
- name: id
dtype: string
- name: question
dtype: string
- name: documents
sequence: string
- name: response
dtype: string
- name: generation_model_name
dtype: string
- name: annotating_model_name
dtype: string
- name: dataset_name
dtype: string
- name: documents_sentences
sequence:
sequence:
sequence: string
- name: response_sentences
sequence:
sequence: string
- name: sentence_support_information
list:
- name: explanation
dtype: string
- name: fully_supported
dtype: bool
- name: response_sentence_key
dtype: string
- name: supporting_sentence_keys
sequence: string
- name: unsupported_response_sentence_keys
sequence: string
- name: adherence_score
dtype: bool
- name: overall_supported_explanation
dtype: string
- name: relevance_explanation
dtype: string
- name: all_relevant_sentence_keys
sequence: string
- name: all_utilized_sentence_keys
sequence: string
- name: trulens_groundedness
dtype: float64
- name: trulens_context_relevance
dtype: float64
- name: ragas_faithfulness
dtype: float64
- name: ragas_context_relevance
dtype: float64
- name: gpt3_adherence
dtype: float64
- name: gpt3_context_relevance
dtype: float64
- name: gpt35_utilization
dtype: float64
- name: relevance_score
dtype: float64
- name: utilization_score
dtype: float64
- name: completeness_score
dtype: float64
splits:
- name: train
num_bytes: 18391043
num_examples: 1870
- name: test
num_bytes: 4241489
num_examples: 423
- name: validation
num_bytes: 3978837
num_examples: 397
download_size: 13254359
dataset_size: 26611369
- config_name: pubmedqa
features:
- name: id
dtype: string
- name: question
dtype: string
- name: documents
sequence: string
- name: response
dtype: string
- name: generation_model_name
dtype: string
- name: annotating_model_name
dtype: string
- name: dataset_name
dtype: string
- name: documents_sentences
sequence:
sequence:
sequence: string
- name: response_sentences
sequence:
sequence: string
- name: sentence_support_information
list:
- name: explanation
dtype: string
- name: fully_supported
dtype: bool
- name: response_sentence_key
dtype: string
- name: supporting_sentence_keys
sequence: string
- name: unsupported_response_sentence_keys
sequence: string
- name: adherence_score
dtype: bool
- name: overall_supported_explanation
dtype: string
- name: relevance_explanation
dtype: string
- name: all_relevant_sentence_keys
sequence: string
- name: all_utilized_sentence_keys
sequence: string
- name: trulens_groundedness
dtype: float64
- name: trulens_context_relevance
dtype: float64
- name: ragas_faithfulness
dtype: float64
- name: ragas_context_relevance
dtype: float64
- name: gpt3_adherence
dtype: float64
- name: gpt3_context_relevance
dtype: float64
- name: gpt35_utilization
dtype: float64
- name: relevance_score
dtype: float64
- name: utilization_score
dtype: float64
- name: completeness_score
dtype: float64
splits:
- name: train
num_bytes: 164267525
num_examples: 19600
- name: validation
num_bytes: 20385411
num_examples: 2450
- name: test
num_bytes: 20627293
num_examples: 2450
download_size: 100443939
dataset_size: 205280229
- config_name: tatqa
features:
- name: id
dtype: string
- name: question
dtype: string
- name: documents
sequence: string
- name: response
dtype: string
- name: generation_model_name
dtype: string
- name: annotating_model_name
dtype: string
- name: dataset_name
dtype: string
- name: documents_sentences
sequence:
sequence:
sequence: string
- name: response_sentences
sequence:
sequence: string
- name: sentence_support_information
list:
- name: explanation
dtype: string
- name: fully_supported
dtype: bool
- name: response_sentence_key
dtype: string
- name: supporting_sentence_keys
sequence: string
- name: unsupported_response_sentence_keys
sequence: string
- name: adherence_score
dtype: bool
- name: overall_supported_explanation
dtype: string
- name: relevance_explanation
dtype: string
- name: all_relevant_sentence_keys
sequence: string
- name: all_utilized_sentence_keys
sequence: string
- name: trulens_groundedness
dtype: float64
- name: trulens_context_relevance
dtype: float64
- name: ragas_faithfulness
dtype: float64
- name: ragas_context_relevance
dtype: float64
- name: gpt3_adherence
dtype: float64
- name: gpt3_context_relevance
dtype: float64
- name: gpt35_utilization
dtype: float64
- name: relevance_score
dtype: float64
- name: utilization_score
dtype: float64
- name: completeness_score
dtype: float64
splits:
- name: train
num_bytes: 164535889
num_examples: 26430
- name: validation
num_bytes: 20771276
num_examples: 3336
- name: test
num_bytes: 19828536
num_examples: 3338
download_size: 78488641
dataset_size: 205135701
- config_name: techqa
features:
- name: id
dtype: string
- name: question
dtype: string
- name: documents
sequence: string
- name: response
dtype: string
- name: generation_model_name
dtype: string
- name: annotating_model_name
dtype: string
- name: dataset_name
dtype: string
- name: documents_sentences
sequence:
sequence:
sequence: string
- name: response_sentences
sequence:
sequence: string
- name: sentence_support_information
list:
- name: explanation
dtype: string
- name: fully_supported
dtype: bool
- name: response_sentence_key
dtype: string
- name: supporting_sentence_keys
sequence: string
- name: unsupported_response_sentence_keys
sequence: string
- name: adherence_score
dtype: bool
- name: overall_supported_explanation
dtype: string
- name: relevance_explanation
dtype: string
- name: all_relevant_sentence_keys
sequence: string
- name: all_utilized_sentence_keys
sequence: string
- name: trulens_groundedness
dtype: float64
- name: trulens_context_relevance
dtype: float64
- name: ragas_faithfulness
dtype: float64
- name: ragas_context_relevance
dtype: float64
- name: gpt3_adherence
dtype: float64
- name: gpt3_context_relevance
dtype: float64
- name: gpt35_utilization
dtype: float64
- name: relevance_score
dtype: float64
- name: utilization_score
dtype: float64
- name: completeness_score
dtype: float64
splits:
- name: train
num_bytes: 54780607
num_examples: 1192
- name: validation
num_bytes: 14226891
num_examples: 304
- name: test
num_bytes: 14115978
num_examples: 314
download_size: 33240403
dataset_size: 83123476
configs:
- config_name: covidqa
data_files:
- split: train
path: covidqa/train-*
- split: test
path: covidqa/test-*
- split: validation
path: covidqa/validation-*
- config_name: cuad
data_files:
- split: train
path: cuad/train-*
- split: validation
path: cuad/validation-*
- split: test
path: cuad/test-*
- config_name: delucionqa
data_files:
- split: train
path: delucionqa/train-*
- split: validation
path: delucionqa/validation-*
- split: test
path: delucionqa/test-*
- config_name: emanual
data_files:
- split: train
path: emanual/train-*
- split: validation
path: emanual/validation-*
- split: test
path: emanual/test-*
- config_name: expertqa
data_files:
- split: train
path: expertqa/train-*
- split: validation
path: expertqa/validation-*
- split: test
path: expertqa/test-*
- config_name: finqa
data_files:
- split: train
path: finqa/train-*
- split: validation
path: finqa/validation-*
- split: test
path: finqa/test-*
- config_name: hagrid
data_files:
- split: train
path: hagrid/train-*
- split: validation
path: hagrid/validation-*
- split: test
path: hagrid/test-*
- config_name: hotpotqa
data_files:
- split: train
path: hotpotqa/train-*
- split: test
path: hotpotqa/test-*
- split: validation
path: hotpotqa/validation-*
- config_name: msmarco
data_files:
- split: train
path: msmarco/train-*
- split: test
path: msmarco/test-*
- split: validation
path: msmarco/validation-*
- config_name: pubmedqa
data_files:
- split: train
path: pubmedqa/train-*
- split: validation
path: pubmedqa/validation-*
- split: test
path: pubmedqa/test-*
- config_name: tatqa
data_files:
- split: train
path: tatqa/train-*
- split: validation
path: tatqa/validation-*
- split: test
path: tatqa/test-*
- config_name: techqa
data_files:
- split: train
path: techqa/train-*
- split: validation
path: techqa/validation-*
- split: test
path: techqa/test-*
---
# RAGBench
## Dataset Overview
RAGBEnch is a large-scale RAG benchmark dataset of 100k RAG examples.
It covers five unique industry-specific domains and various RAG task types.
RAGBench examples are sourced from industry corpora such as user manuals, making it particularly relevant for industry applications.
RAGBench comrises 12 sub-component datasets, each one split into train/validation/test splits
## Usage
```
from datasets import load_dataset
# load train/validation/test splits of individual subset
ragbench_hotpotqa = load_dataset("rungalileo/ragbench", "hotpotqa")
# load a specific split of a subset dataset
ragbench_hotpotqa = load_dataset("rungalileo/ragbench", "hotpotqa", split="test")
# load the full ragbench dataset
ragbench = {}
for dataset in ['covidqa', 'cuad', 'delucionqa', 'emanual', 'expertqa', 'finqa', 'hagrid', 'hotpotqa', 'msmarco', 'pubmedqa', 'tatqa', 'techqa']:
ragbench[dataset] = load_dataset("rungalileo/ragbench", dataset)
```
许可证:知识共享署名4.0(CC BY 4.0)协议。
数据集详情:
- 配置项:新冠问答(COVIDQA)
字段列表:
- 字段名:标识符(id),数据类型:字符串
- 字段名:问题,数据类型:字符串
- 字段名:文档,类型为字符串序列
- 字段名:响应结果,数据类型:字符串
- 字段名:生成模型名称,数据类型:字符串
- 字段名:标注模型名称,数据类型:字符串
- 字段名:数据集名称,数据类型:字符串
- 字段名:文档句子,类型为三级字符串序列(字符串序列的序列的序列)
- 字段名:响应句子,类型为二级字符串序列
- 字段名:句子支撑信息,列表项包含:
- 解释说明,数据类型:字符串
- 是否完全支撑,数据类型:布尔值
- 响应句子键,数据类型:字符串
- 支撑句子键序列,类型为字符串序列
- 字段名:无支撑响应句子键序列,类型为字符串序列
- 字段名:一致性得分,数据类型:布尔值
- 字段名:整体支撑解释,数据类型:字符串
- 字段名:相关性解释,数据类型:字符串
- 字段名:全部相关句子键序列,类型为字符串序列
- 字段名:全部已使用句子键序列,类型为字符串序列
- 字段名:Trulens groundedness 得分,数据类型:64位浮点数
- 字段名:Trulens 上下文相关性得分,数据类型:64位浮点数
- 字段名:RAGAS 忠实度得分,数据类型:64位浮点数
- 字段名:RAGAS 上下文相关性得分,数据类型:64位浮点数
- 字段名:GPT-3 一致性得分,数据类型:64位浮点数
- 字段名:GPT-3 上下文相关性得分,数据类型:64位浮点数
- 字段名:GPT-3.5 利用率得分,数据类型:64位浮点数
- 字段名:相关性得分,数据类型:64位浮点数
- 字段名:利用率得分,数据类型:64位浮点数
- 字段名:完整性得分,数据类型:64位浮点数
数据拆分:
- 训练集:占用字节数9055112,样本数量1252
- 测试集:占用字节数1727572,样本数量246
- 验证集:占用字节数1912181,样本数量267
下载大小:5971008字节,数据集总大小:12694865字节
- 配置项:合同问答(CUAD)
字段列表与新冠问答(COVIDQA)配置项一致
数据拆分:
- 训练集:占用字节数182478144,样本数量1530
- 验证集:占用字节数57319053,样本数量510
- 测试集:占用字节数46748691,样本数量510
下载大小:84927484字节,数据集总大小:286545888字节
- 配置项:妄想问答(DelusionQA)
字段列表与新冠问答(COVIDQA)配置项一致
数据拆分:
- 训练集:占用字节数18650496,样本数量1460
- 验证集:占用字节数2177923,样本数量182
- 测试集:占用字节数2375521,样本数量184
下载大小:5318525字节,数据集总大小:23203940字节
- 配置项:电子手册(eManual)
字段列表与新冠问答(COVIDQA)配置项一致
数据拆分:
- 训练集:占用字节数9748871,样本数量1054
- 验证集:占用字节数1193359,样本数量132
- 测试集:占用字节数1280363,样本数量132
下载大小:2292660字节,数据集总大小:12222593字节
- 配置项:专家问答(ExpertQA)
字段列表与新冠问答(COVIDQA)配置项一致
数据拆分:
- 训练集:占用字节数41944570,样本数量1621
- 验证集:占用字节数4179337,样本数量203
- 测试集:占用字节数5132792,样本数量203
下载大小:27804260字节,数据集总大小:51256699字节
- 配置项:金融问答(FinQA)
字段列表与新冠问答(COVIDQA)配置项一致
数据拆分:
- 训练集:占用字节数141636050,样本数量12502
- 验证集:占用字节数19723115,样本数量1766
- 测试集:占用字节数25607832,样本数量2294
下载大小:75943796字节,数据集总大小:186966997字节
- 配置项:HAGRID
字段列表与新冠问答(COVIDQA)配置项一致
数据拆分:
- 训练集:占用字节数17710422,样本数量2892
- 验证集:占用字节数1910449,样本数量322
- 测试集:占用字节数8238507,样本数量1318
下载大小:14435405字节,数据集总大小:27859378字节
- 配置项:热桶问答(HotPotQA)
字段列表与新冠问答(COVIDQA)配置项一致
数据拆分:
- 训练集:占用字节数11178145,样本数量1883
- 测试集:占用字节数2264863,样本数量390
- 验证集:占用字节数2493601,样本数量424
下载大小:9130974字节,数据集总大小:15936609字节
- 配置项:MS MARCO
字段列表与新冠问答(COVIDQA)配置项一致
数据拆分:
- 训练集:占用字节数18391043,样本数量1870
- 测试集:占用字节数4241489,样本数量423
- 验证集:占用字节数3978837,样本数量397
下载大小:13254359字节,数据集总大小:26611369字节
- 配置项:PubMedQA
字段列表与新冠问答(COVIDQA)配置项一致
数据拆分:
- 训练集:占用字节数164267525,样本数量19600
- 验证集:占用字节数20385411,样本数量2450
- 测试集:占用字节数20627293,样本数量2450
下载大小:100443939字节,数据集总大小:205280229字节
- 配置项:表格问答(TAT-QA)
字段列表与新冠问答(COVIDQA)配置项一致
数据拆分:
- 训练集:占用字节数164535889,样本数量26430
- 验证集:占用字节数20771276,样本数量3336
- 测试集:占用字节数19828536,样本数量3338
下载大小:78488641字节,数据集总大小:205135701字节
- 配置项:技术问答(TechQA)
字段列表与新冠问答(COVIDQA)配置项一致
数据拆分:
- 训练集:占用字节数54780607,样本数量1192
- 验证集:占用字节数14226891,样本数量304
- 测试集:占用字节数14115978,样本数量314
下载大小:33240403字节,数据集总大小:83123476字节
数据集配置:
- 配置项:COVIDQA
数据文件:
- 训练集拆分:路径为covidqa/train-*
- 测试集拆分:路径为covidqa/test-*
- 验证集拆分:路径为covidqa/validation-*
- 配置项:CUAD
数据文件:
- 训练集拆分:路径为cuad/train-*
- 验证集拆分:路径为cuad/validation-*
- 测试集拆分:路径为cuad/test-*
- 配置项:DelusionQA
数据文件:
- 训练集拆分:路径为delucionqa/train-*
- 验证集拆分:路径为delucionqa/validation-*
- 测试集拆分:路径为delucionqa/test-*
- 配置项:eManual
数据文件:
- 训练集拆分:路径为emanual/train-*
- 验证集拆分:路径为emanual/validation-*
- 测试集拆分:路径为emanual/test-*
- 配置项:ExpertQA
数据文件:
- 训练集拆分:路径为expertqa/train-*
- 验证集拆分:路径为expertqa/validation-*
- 测试集拆分:路径为expertqa/test-*
- 配置项:FinQA
数据文件:
- 训练集拆分:路径为finqa/train-*
- 验证集拆分:路径为finqa/validation-*
- 测试集拆分:路径为finqa/test-*
- 配置项:HAGRID
数据文件:
- 训练集拆分:路径为hagrid/train-*
- 验证集拆分:路径为hagrid/validation-*
- 测试集拆分:路径为hagrid/test-*
- 配置项:HotPotQA
数据文件:
- 训练集拆分:路径为hotpotqa/train-*
- 测试集拆分:路径为hotpotqa/test-*
- 验证集拆分:路径为hotpotqa/validation-*
- 配置项:MS MARCO
数据文件:
- 训练集拆分:路径为msmarco/train-*
- 测试集拆分:路径为msmarco/test-*
- 验证集拆分:路径为msmarco/validation-*
- 配置项:PubMedQA
数据文件:
- 训练集拆分:路径为pubmedqa/train-*
- 验证集拆分:路径为pubmedqa/validation-*
- 测试集拆分:路径为pubmedqa/test-*
- 配置项:TAT-QA
数据文件:
- 训练集拆分:路径为tatqa/train-*
- 验证集拆分:路径为tatqa/validation-*
- 测试集拆分:路径为tatqa/test-*
- 配置项:TechQA
数据文件:
- 训练集拆分:路径为techqa/train-*
- 验证集拆分:路径为techqa/validation-*
- 测试集拆分:路径为techqa/test-*
# RAGBench 基准数据集
## 数据集概述
RAGBench是一款包含10万个检索增强生成(Retrieval-Augmented Generation, RAG)样本的大规模基准数据集。该数据集涵盖5个独特的垂直行业领域与多种RAG任务类型,其样本源自用户手册等行业语料库,因此特别适配工业级应用场景。
RAGBench包含12个子数据集,每个子数据集均划分为训练集、验证集与测试集三个子集。
## 使用方法
from datasets import load_dataset
# 加载单个子数据集的训练、验证、测试拆分集
ragbench_hotpotqa = load_dataset("rungalileo/ragbench", "hotpotqa")
# 加载指定子数据集的特定拆分集
ragbench_hotpotqa = load_dataset("rungalileo/ragbench", "hotpotqa", split="test")
# 加载完整的RAGBench数据集
ragbench = {}
for dataset in ['covidqa', 'cuad', 'delucionqa', 'emanual', 'expertqa', 'finqa', 'hagrid', 'hotpotqa', 'msmarco', 'pubmedqa', 'tatqa', 'techqa']:
ragbench[dataset] = load_dataset("rungalileo/ragbench", dataset)
提供机构:
rungalileo
原始信息汇总
数据集概述
本数据集包含多个子数据集,每个子数据集都有详细的配置和特征描述,以及训练、验证和测试集的统计信息。以下是各子数据集的概要信息:
1. covidqa
- 特征: 包含id, question, documents, response等字段。
- 分割: 训练集1252个样本,验证集267个样本,测试集246个样本。
- 数据大小: 训练集8984005字节,验证集1897003字节,测试集1713734字节。
2. cuad
- 特征: 包含id, question, documents, response等字段。
- 分割: 训练集1530个样本,验证集510个样本,测试集510个样本。
- 数据大小: 训练集182389316字节,验证集57289199字节,测试集46718917字节。
3. delucionqa
- 特征: 包含id, question, documents, response等字段。
- 分割: 训练集1460个样本,验证集182个样本,测试集184个样本。
- 数据大小: 训练集18566265字节,验证集2167322字节,测试集2364991字节。
4. emanual
- 特征: 包含id, question, documents, response等字段。
- 分割: 训练集1054个样本,验证集132个样本,测试集132个样本。
- 数据大小: 训练集9686677字节,验证集1185491字节,测试集1272736字节。
5. expertqa
- 特征: 包含id, question, documents, response等字段。
- 分割: 训练集1625个样本,验证集203个样本,测试集204个样本。
- 数据大小: 训练集42076674字节,验证集4166081字节,测试集5131418字节。
6. finqa
- 特征: 包含id, question, documents, response等字段。
- 分割: 训练集12502个样本,验证集1766个样本,测试集2294个样本。
- 数据大小: 训练集140916227字节,验证集19620409字节,测试集25475684字节。
7. hagrid
- 特征: 包含id, question, documents, response等字段。
- 分割: 训练集2892个样本,验证集322个样本,测试集1318个样本。
- 数据大小: 训练集17543707字节,验证集1891953字节,测试集8162944字节。
8. hotpotqa
- 特征: 包含id, question, documents, response等字段。
- 分割: 训练集1883个样本,验证集424个样本,测试集390个样本。
- 数据大小: 训练集11071723字节,验证集2469645字节,测试集2242974字节。
9. msmarco
- 特征: 包含id, question, documents, response等字段。
- 分割: 训练集1870个样本,验证集397个样本,测试集423个样本。
- 数据大小: 训练集18284996字节,验证集3956315字节,测试集4217545字节。
10. pubmedqa
- 特征: 包含id, question, documents, response等字段。
- 分割: 训练集19600个样本,验证集2450个样本,测试集2450个样本。
- 数据大小: 训练集163163609字节,验证集20242504字节,测试集20484420字节。
11. tatqa
- 特征: 包含id, question, documents, response等字段。
- 分割: 训练集26430个样本,验证集3336个样本,测试集3338个样本。
- 数据大小: 训练集163031771字节,验证集20579120字节,测试集19638637字节。
12. techqa
- 特征: 包含id, question, documents, response等字段。
- 分割: 训练集1192个样本,验证集304个样本,测试集314个样本。
- 数据大小: 训练集54696847字节,验证集14204671字节,测试集14093195字节。
数据集使用
- 加载方式: 使用
from datasets import load_dataset进行数据集的加载。
许可
- 许可证: 本数据集遵循CC-BY-4.0许可证。
搜集汇总
数据集介绍
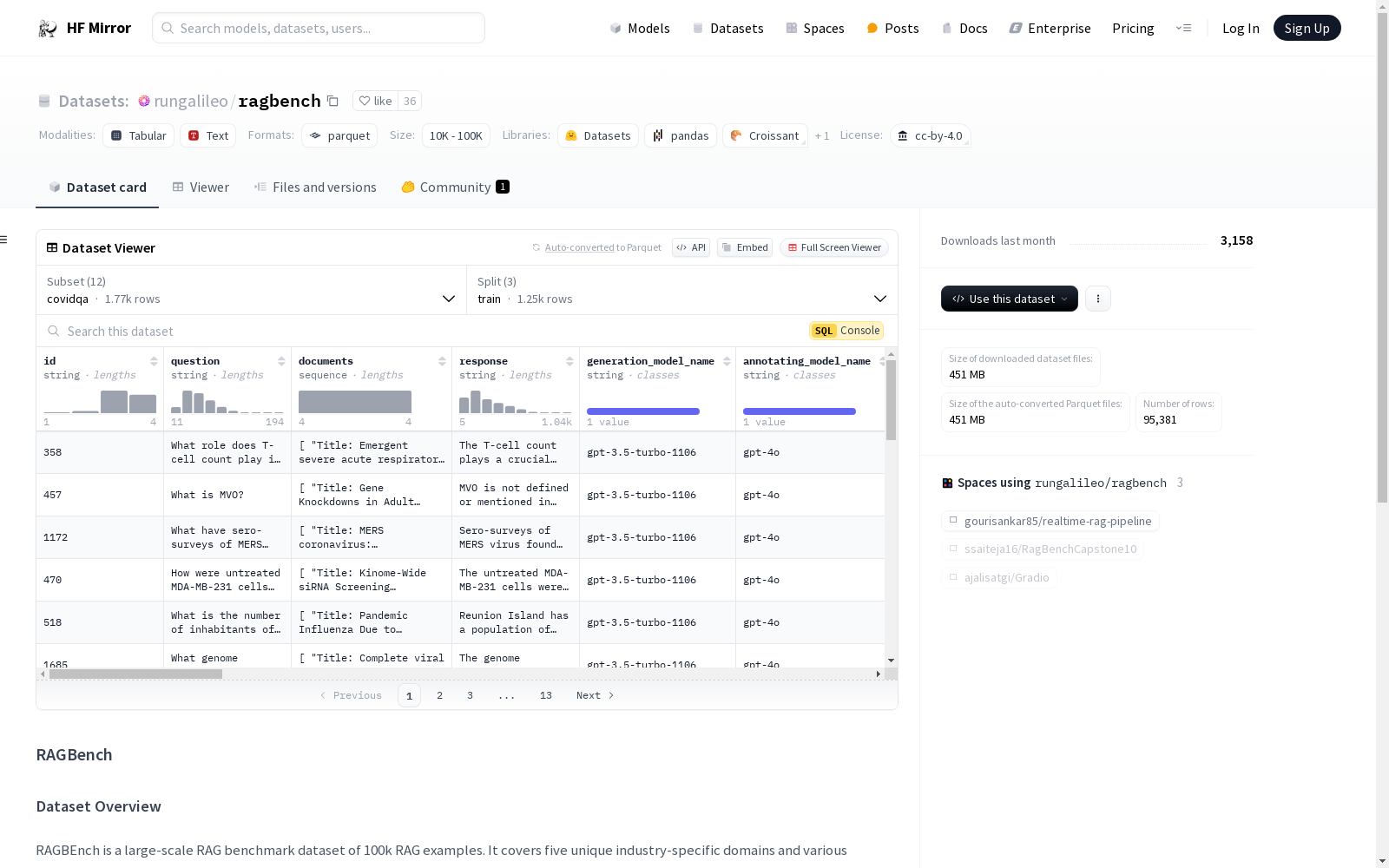
构建方式
rungalileo/ragbench数据集的构建基于多个子数据集,涵盖了广泛的问答场景。每个子数据集通过生成模型和标注模型的协作,生成了包含问题、文档、回答及其支持信息的结构化数据。数据集的构建过程注重信息的完整性和准确性,确保每个回答都有相应的文档支持,并通过多种评分机制(如忠实度、上下文相关性等)进行验证。
特点
该数据集的特点在于其多样性和丰富性,涵盖了从COVID-19相关问答到金融、法律、技术等多个领域的问答数据。每个子数据集都提供了详细的句子级支持信息,包括回答句子的支持文档、支持程度解释以及多种评分指标。这些特点使得该数据集特别适合用于评估问答系统的忠实度、上下文相关性和信息利用率。
使用方法
使用rungalileo/ragbench数据集时,研究人员可以通过加载不同的子数据集(如covidqa、cuad等)来评估问答模型的性能。数据集提供了训练、验证和测试集,用户可以通过分析回答的支持信息、评分指标等,深入理解模型在生成回答时的表现。此外,数据集的多维度评分机制为模型优化提供了丰富的反馈信息。
背景与挑战
背景概述
rungalileo/ragbench数据集是一个专注于问答系统评估的综合性数据集,旨在通过多维度指标评估生成式问答模型的性能。该数据集由多个子数据集组成,涵盖了COVID-19、法律、金融、医学等多个领域的问题。其核心研究问题在于如何通过细粒度的支持信息评估模型生成答案的准确性、相关性和完整性。该数据集的创建为问答系统的评估提供了标准化工具,推动了生成式模型在复杂场景中的应用与发展。
当前挑战
rungalileo/ragbench数据集在构建和应用中面临多重挑战。首先,数据集的多样性要求模型能够跨领域理解复杂问题,这对模型的泛化能力提出了极高要求。其次,细粒度的支持信息标注需要大量人工参与,标注的一致性和准确性难以保证。此外,评估指标的设计需兼顾全面性与可操作性,如何在多个维度上平衡评估结果仍是一个难题。最后,数据集的规模与复杂性对计算资源提出了较高需求,限制了其在资源有限环境中的应用。
常用场景
经典使用场景
在自然语言处理领域,rungalileo/ragbench数据集广泛应用于问答系统的评估与优化。该数据集通过提供丰富的问答对及其相关文档,帮助研究者测试和提升检索增强生成(RAG)模型的性能。特别是在多文档问答场景中,模型需要从大量文档中提取相关信息并生成准确回答,该数据集为此提供了理想的测试平台。
实际应用
在实际应用中,rungalileo/ragbench数据集被广泛用于构建和优化智能客服系统、医疗问答系统以及金融领域的自动问答工具。例如,在医疗领域,该数据集可以帮助模型从大量医学文献中提取相关信息,生成准确的诊断建议或治疗方案,从而提升医疗服务的效率与质量。
衍生相关工作
基于rungalileo/ragbench数据集,研究者开发了多种改进的问答模型和评估框架。例如,一些工作专注于提升模型在多文档问答中的上下文理解能力,另一些则通过引入新的评估指标来更全面地衡量模型的生成质量。这些衍生工作进一步推动了问答系统技术的发展,并为相关领域的研究提供了新的思路。
以上内容由遇见数据集搜集并总结生成


