movielens-32m-movies-enriched
收藏Hugging Face2025-11-28 更新2025-11-29 收录
下载链接:
https://huggingface.co/datasets/krishnakamath/movielens-32m-movies-enriched
下载链接
链接失效反馈官方服务:
资源简介:
MovieLens 32M数据集的增强版,包含了电影的详细剧情摘要、导演和前三名主演的信息。适用于需要更丰富电影元数据的应用场景。
创建时间:
2025-11-27
原始信息汇总
Enriched MovieLens 32M Dataset 概述
数据集描述
- 本数据集是流行的MovieLens 32M数据集的增强版本
- 原始movies.csv文件已通过OpenAI的gpt-3.5-turbo模型进行了数据增强
- 增强字段包括:剧情摘要、导演信息和主演名单
数据集结构
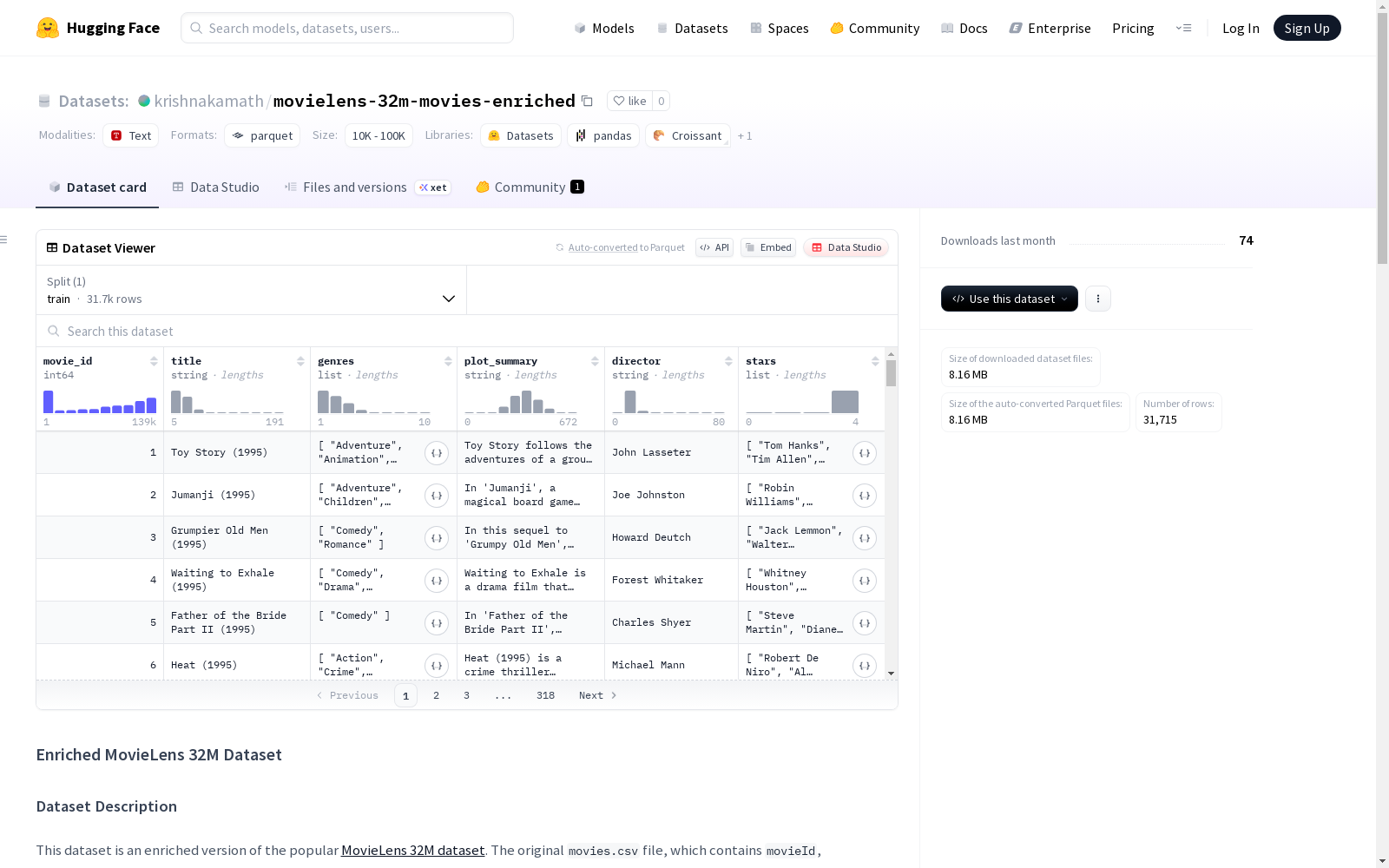
数据字段
- movie_id (int64):电影唯一标识符
- title (string):电影标题(含发行年份)
- genres (string列表):电影类型列表
- plot_summary (string):电影剧情摘要
- director (string):电影导演
- stars (string列表):前3名主演名单
数据规模
- 训练集样本数量:16,245
- 训练集大小:8,255,362字节
- 下载大小:4,260,712字节
- 数据集总大小:8,255,362字节
使用示例
json { "movie_id": 1, "title": "Toy Story (1995)", "genres": ["Adventure", "Animation", "Children", "Comedy", "Fantasy"], "plot_summary": "In a world where toys are living things who pretend to be lifeless when humans are present...", "director": "John Lasseter", "stars": ["Tom Hanks", "Tim Allen", "Don Rickles"] }
适用场景
- 基于内容的推荐系统
- 剧情摘要的自然语言处理任务
- 详细的电影信息展示
引用信息
原始数据集引用
F. Maxwell Harper and Joseph A. Konstan. 2015. The MovieLens Datasets: History and Context. ACM Transactions on Interactive Intelligent Systems (TiiS) 5, 4: 19:1–19:19. https://doi.org/10.1145/2827872
增强过程
数据集增强使用了OpenAI API,如对您的工作有帮助请致谢
搜集汇总
数据集介绍
构建方式
在电影推荐系统研究领域,数据集的构建方法直接影响其科学价值。本数据集以MovieLens 32M原始数据为基础,通过精心设计的自动化流程进行扩展。原始电影元数据经过OpenAI的gpt-3.5-turbo模型处理,系统性地为每部电影生成情节概要、导演信息和主演名单。构建过程采用增量式处理机制,通过专用脚本确保数据完整性,避免重复处理已存在的记录,最终形成包含16,245个样本的标准化数据集。
特点
作为电影信息挖掘领域的重要资源,本数据集展现出多维度的特征优势。其核心价值在于融合了传统结构化数据与自然语言描述,每条记录包含电影标识符、片名、类型列表等基础字段,同时创新性地添加了100-150字的情节概要、导演姓名及前三位主演信息。这种混合型数据结构既保留了原始评分的统计特性,又通过语义丰富的文本描述为内容分析提供了深度,特别适合需要综合理解电影内容的计算任务。
使用方法
在实践应用层面,研究者可通过标准化流程高效利用本数据集。借助Hugging Face生态系统,用户只需调用datasets库的load_dataset函数即可完成数据加载。加载后的数据结构清晰划分为训练集,支持直接索引访问和批量处理。这种便捷的接口设计使得数据集能够快速集成到推荐系统算法、自然语言处理流程或多媒体分析框架中,为电影领域的计算研究提供即用型数据支撑。
背景与挑战
背景概述
作为推荐系统研究领域的里程碑式资源,MovieLens数据集由明尼苏达大学GroupLens研究团队于2015年正式发布,旨在通过大规模用户观影行为数据推动协同过滤算法的发展。该数据集通过记录数千万用户对电影的评分数据,为个性化推荐系统提供了关键实验基础。本次发布的增强版本在原始电影元数据基础上,整合了由GPT-3.5模型生成的剧情摘要、导演信息与主演名单,显著拓展了其在内容感知推荐与自然语言处理任务中的应用维度。
当前挑战
在推荐系统领域,传统协同过滤方法面临数据稀疏与冷启动问题的持续挑战,而增强版数据集通过引入文本语义特征为混合推荐算法提供了新思路。数据构建过程中需克服原始 metadata 的结构化局限,通过大语言模型生成补充信息时需确保剧情摘要的语义准确性与人物关系的逻辑一致性,同时要处理电影年代跨度导致的导演演员信息缺失问题,这些因素共同构成了数据集质量保障的核心难点。
常用场景
经典使用场景
在推荐系统领域,该数据集凭借其丰富的电影元数据与情节摘要,成为构建内容推荐模型的理想资源。研究者能够利用导演、演员及剧情文本特征,开发出超越传统协同过滤的混合推荐算法,通过语义理解提升个性化推荐的准确性与多样性。
解决学术问题
该数据集有效解决了电影推荐系统中冷启动与数据稀疏性等经典难题。通过补充结构化剧情文本与创作团队信息,为基于深度学习的自然语言处理研究提供了多模态实验基础,显著推动了推荐系统可解释性与跨领域知识迁移的研究进展。
衍生相关工作
基于该数据集衍生的经典研究包括结合图神经网络与文本嵌入的混合推荐框架,以及利用剧情摘要进行电影类型多标签分类的深度学习方法。这些工作进一步催生了基于注意力机制的跨模态检索模型,为影视知识图谱构建提供了重要技术范式。
以上内容由遇见数据集搜集并总结生成


