iris
收藏Hugging Face2025-04-09 更新2025-04-10 收录
下载链接:
https://huggingface.co/datasets/ViictorCM/iris
下载链接
链接失效反馈官方服务:
资源简介:
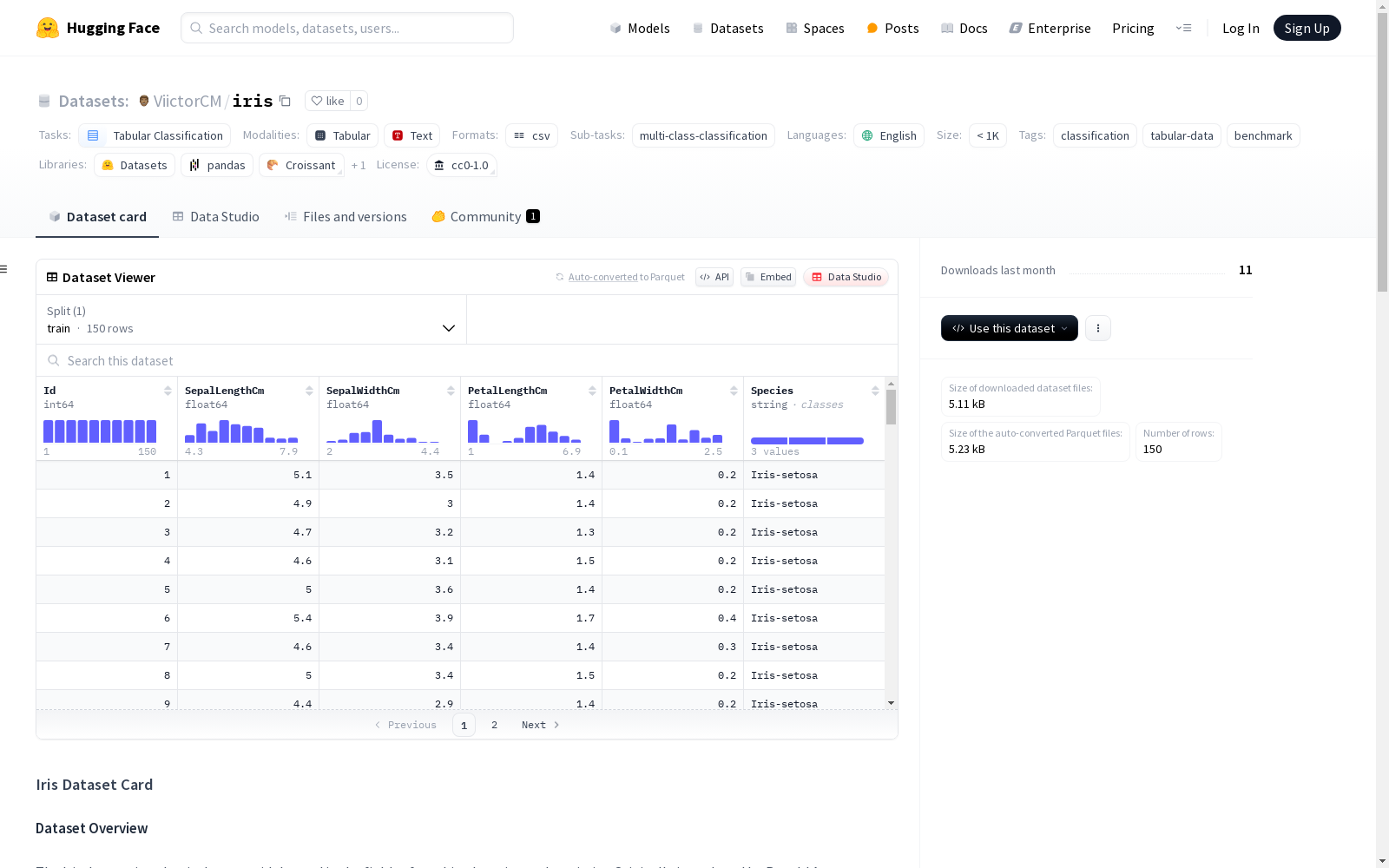
鸢尾花数据集是一个在机器学习和统计领域广泛使用的经典数据集,最初由Ronald A. Fisher于1936年提出,作为分类算法的基准。该数据集包含三种不同鸢尾花的测量数据:**Iris setosa**、**Iris versicolor**和**Iris virginica**。数据集包含150个实例,4个特征,分为3个类别,每个类别50个实例。特征类型为连续型,没有缺失值。目标变量是分类变量,代表鸢尾花的种类。
The Iris flower dataset is a classic benchmark widely utilized in the fields of machine learning and statistics. It was first proposed by Ronald A. Fisher in 1936 as a validation standard for classification algorithms. This dataset contains measurement data for three distinct iris species: **Iris setosa**, **Iris versicolor**, and **Iris virginica**. It consists of 150 total instances, with 4 features, and is divided into 3 categories, each containing 50 instances. All features are continuous variables with no missing values, and the target variable is a categorical variable representing the specific iris species.
创建时间:
2025-04-05
搜集汇总
数据集介绍
构建方式
作为模式识别领域的经典基准数据集,Iris数据集由统计学家Ronald A. Fisher于1936年系统整理并引入学术界。该数据集源自植物学家Edgar Anderson对三种鸢尾属植物(山鸢尾、变色鸢尾和维吉尼亚鸢尾)的形态学测量,每条记录包含四个连续型特征变量(萼片长度、萼片宽度、花瓣长度和花瓣宽度)以及对应的物种分类标签。数据采集过程严格遵循植物学测量规范,确保了150个样本在三个类别上的均衡分布,且不存在缺失值问题。
特点
Iris数据集以其结构简洁而内涵丰富著称,其核心价值体现在多维特征的完美平衡性上。四个形态特征均采用厘米级精确测量,呈现典型的连续数值分布特性,为研究特征空间划分提供了理想条件。三类物种在特征空间中呈现清晰的线性可分到非线性可分的渐进分布模式,这种特性使其成为验证分类算法泛化能力的黄金标准。数据集的轻量级特性(仅150个样本)特别适合教学演示和算法原型开发,而其蕴含的模式复杂性又能有效检验模型性能。
使用方法
在实践应用中,Iris数据集可通过Python生态中的scikit-learn库直接加载,其结构化数据格式完美适配主流机器学习框架。研究人员通常将80%样本用于训练各类分类器(如支持向量机、决策树等),剩余20%作为测试集验证模型性能。数据可视化环节常采用散点矩阵展示特征间相关性,或通过PCA降维观察类别可分性。作为机器学习入门教学的标准教具,该数据集能清晰演示从数据探索、特征工程到模型评估的完整工作流程。
背景与挑战
背景概述
Iris数据集作为机器学习领域的经典基准数据集,由统计学家Ronald A. Fisher于1936年首次引入,其原始数据来源于植物学家Edgar Anderson对鸢尾花卉的形态学测量。该数据集系统记录了三种鸢尾属植物(山鸢尾、变色鸢尾和维吉尼亚鸢尾)的萼片与花瓣形态特征,包含150个样本的4个连续型特征变量。作为模式识别领域的里程碑式数据资源,它不仅开创了线性判别分析的经典案例,更成为评估分类算法性能的黄金标准,在统计学与机器学习教育研究中持续发挥着不可替代的作用。
当前挑战
尽管Iris数据集具有结构简洁的优势,但其固有特性也带来显著的研究挑战。在领域问题层面,仅4个特征维度限制了复杂模型的表达能力,而样本量过小导致统计显著性检验效力不足,三类样本的完全平衡分布亦与现实场景中的类别不均衡问题存在差距。就构建过程而言,上世纪30年代的数据采集技术制约了特征多样性,缺乏花器颜色纹理等潜在判别特征,且单一地理来源的数据限制了模型的泛化能力验证。这些特性使得该数据集更适用于教学演示,而在应对现代复杂分类任务时显现出明显的时代局限性。
常用场景
经典使用场景
在机器学习领域,Iris数据集作为经典的分类任务基准,常被用于验证监督学习算法的有效性。研究者通过该数据集探索不同分类器在特征空间中的表现,例如决策树、支持向量机和神经网络等模型。其简洁的四维特征结构和明确的类别划分,使其成为算法比较和模型调试的理想选择。
衍生相关工作
该数据集催生了大量经典研究,如Fisher线性判别分析的原理论证。现代机器学习教程普遍将其作为第一个案例,Scikit-learn等开源库以其为默认测试数据。近年来衍生出基于深度学习的特征提取改进研究,以及多模态数据融合的扩展实验。
数据集最近研究
最新研究方向
在机器学习领域,Iris数据集作为经典基准测试集,近年来被广泛应用于新型分类算法的验证与比较。随着深度学习技术的快速发展,研究者们开始探索如何将传统统计学习方法与深度神经网络相结合,利用Iris数据集验证混合模型的性能。同时,在可解释性机器学习的热潮下,该数据集因其简洁性成为展示特征重要性分析、决策路径可视化等技术的理想案例。在迁移学习研究中,Iris数据集的标准化特性使其成为跨领域知识迁移的基准测试平台。教育领域也持续关注该数据集,开发基于交互式可视化的教学工具,帮助学生直观理解分类算法的核心原理。
以上内容由遇见数据集搜集并总结生成


