reddyrohith49471/jt-dataset-final4
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/reddyrohith49471/jt-dataset-final4
下载链接
链接失效反馈官方服务:
资源简介:
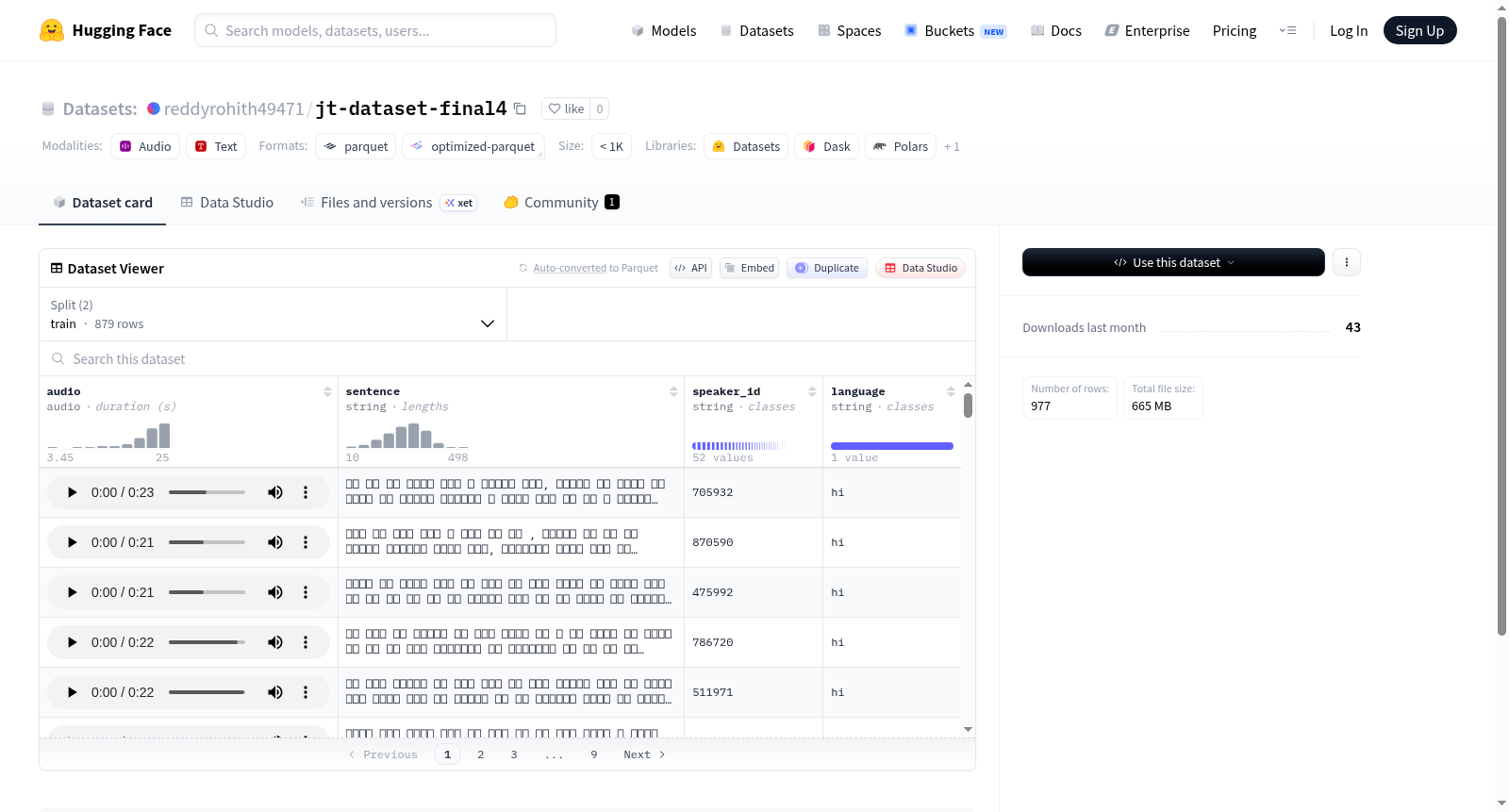
该数据集是一个音频-文本数据集,包含879个训练示例和98个测试示例。每个示例包括音频数据(采样率为16000Hz)、对应的句子文本、说话者ID和语言信息。音频数据以原始音频格式存储,句子为字符串类型,说话者ID和语言也均为字符串类型。数据集总下载大小约为664.5MB,总数据集大小约为664.8MB。数据文件按训练和测试划分组织,路径分别为data/train-*和data/test-*。
This dataset is an audio-text dataset comprising 879 training examples and 98 test examples. Each example includes audio data (sampled at 16000Hz), corresponding sentence text, speaker ID, and language information. The audio is stored in raw audio format, the sentence is of string type, and the speaker ID and language are also string types. The total download size is approximately 664.5MB, and the total dataset size is approximately 664.8MB. The data files are organized into train and test splits, with paths specified as data/train-* and data/test-*.
提供机构:
reddyrohith49471
搜集汇总
数据集介绍
构建方式
该数据集基于语音与文本对齐的范式构建,采用16kHz采样率的音频数据作为声学基底,并辅以句子文本、说话人标识及语言类别等结构化标签。数据划分为训练集与测试集,其中训练集包含879个样本,测试集包含98个样本,整体数据规模约为664MB。数据集以分片形式存储,通过通配符路径统一加载,确保了数据读取的高效性与可扩展性。
特点
此数据集的一个显著特征在于其多维度注释体系,不仅涵盖了语音信号与对应转录文本的精确配对,还提供了细粒度的说话人身份信息与语言标签,从而支持跨说话人及多语言场景下的语音处理任务。此外,音频数据经过标准化采样率处理,降低了预处理复杂度,而适中的样本数量与均衡的分割比例则兼顾了模型训练与评估的可靠性。
使用方法
数据集可通过HuggingFace的`datasets`库便捷调用,默认配置下采用`load_dataset`函数并指定路径参数即可自动加载分片数据。训练与测试分割已预定义,用户无需额外处理即可直接用于模型训练和性能评估。音频特征与文本标签的解耦设计,使得该数据集能够无缝适配语音识别、说话人验证及语音合成等多种下游任务。
背景与挑战
背景概述
在语音识别与自然语言处理领域,高质量的多语言语音数据集是推动模型性能提升的关键基石。jt-dataset-final4 数据集由未知机构于近期构建,旨在为多语言语音识别任务提供标准化训练与测试资源。该数据集包含音频、文本标注、说话人身份及语言标签四项核心特征,覆盖训练样本879条、测试样本98条,音频采样率为16kHz,符合常见语音处理需求。通过整合多语言语音数据,该数据集有望支持跨语言声学模型与端到端语音识别系统的研究,为低资源语言的语音技术发展贡献力量。
当前挑战
该数据集面临的核心挑战包括领域问题与构建过程两方面。在领域问题上,多语言语音识别需应对语种间声学差异、发音多样性及口音干扰,而数据集的有限规模(不足千条样本)可能限制模型泛化能力,难以覆盖各语言的真实分布。在构建过程中,需确保音频质量与文本标注的精准对齐,并处理说话人身份信息的一致性;同时,多语言标签的标准化与平衡性设计也是一大难点,不当的划分可能引入数据偏差,影响下游任务的公平评估。
常用场景
经典使用场景
该数据集以16kHz采样率的音频数据为核心,配备精确的句子转录文本、说话人身份标识及语言标签,天然适用于多语种语音识别(ASR)系统的训练与评测。研究人员可利用其训练集与测试集划分,构建端到端或混合语音识别模型,评估模型在不同语言下的词错误率(WER)表现。此外,由于包含说话人信息,该数据集亦可服务于说话人识别或语音分割任务,为多说话人场景下的语音处理提供基础支撑。
解决学术问题
在学术研究中,该数据集有效解决了跨语言语音识别的数据稀缺问题,为低资源语言的声学模型训练提供了标准化基准。通过引入说话人及语言标注,它助力研究人员探索说话人无关与语言无关的特征提取方法,推动迁移学习在多语种语音系统中的进展。同时,该数据集的发布促进了语音技术在不同语言背景下的公平性研究,减少了模型对主流语言的偏倚现象。
衍生相关工作
基于此数据集,衍生了一系列语音识别与处理领域的经典工作,包括基于Transformer的端到端语音识别模型优化、自监督预训练语音表征方法(如wav2vec 2.0微调)以及多任务学习框架(联合语音识别与说话人分类)。这些工作不仅提升了模型在噪声环境下的鲁棒性,还推动了语音技术从实验室向工业应用的迁移,形成了如语音增强与识别联合建模等创新研究方向。
以上内容由遇见数据集搜集并总结生成


