json-training|模型训练数据集|JSON数据处理数据集
收藏huggingface2024-08-22 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/ChristianAzinn/json-training
下载链接
链接失效反馈资源简介:
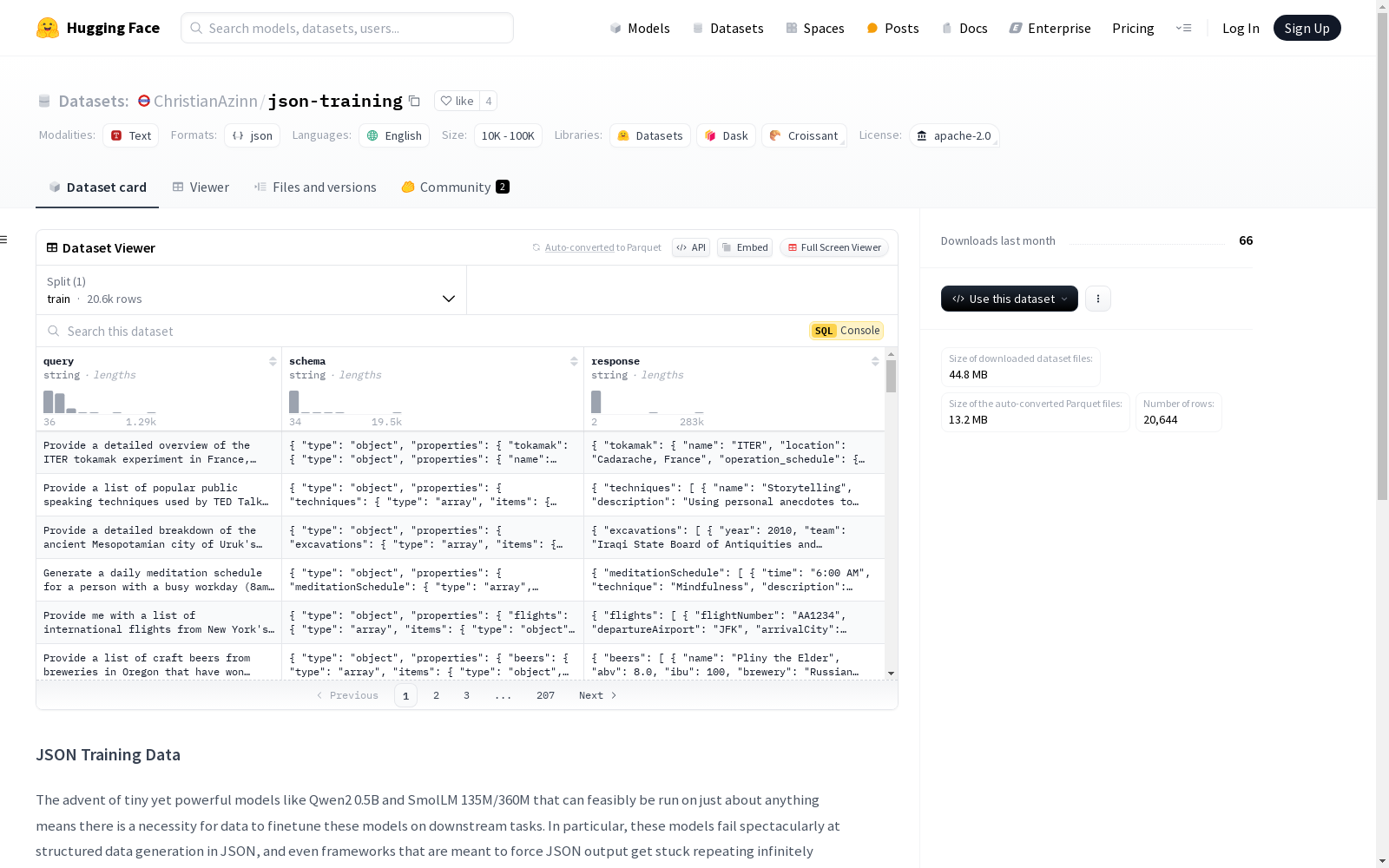
该数据集旨在为微调小型但功能强大的模型(如Qwen2 0.5B和SmolLM 135M/360M)提供支持,这些模型在处理JSON格式的结构化数据生成任务时表现不佳。数据集包含`query`、`schema`和`response`三个字段,分别代表用户查询的纯文本、期望的输出JSON模式和符合该模式的LLM响应示例。数据集是通过大型LLM(如Llama 3.1 8B和Claude 3.5 Sonnet)合成生成的,并将定期更新新数据。
创建时间:
2024-08-21
原始信息汇总
JSON Training Data
数据集概述
该数据集旨在为小型但功能强大的模型(如Qwen2 0.5B和SmolLM 135M/360M)提供微调数据,特别是在JSON结构化数据生成方面。这些模型在处理JSON输出时表现不佳,因此需要专门的数据集进行微调。
数据收集
数据完全由大型语言模型(LLMs)合成生成,主要使用Llama 3.1 8B生成,并由Claude 3.5 Sonnet贡献约2000个示例。
数据字段
数据集包含以下字段:
query:用户的纯文本查询,无结构化组件。schema:期望的输出JSON模式。response:符合schema的LLM对query的示例响应。
用户可以根据需要将这些字段转换为任何格式进行微调,例如将模式放入系统提示中,或将模式注入用户消息中。
AI搜集汇总
数据集介绍
构建方式
JSON Training Data数据集的构建主要依赖于大型语言模型的合成生成技术。该数据集通过Llama 3.1 8B模型生成大部分数据,同时Claude 3.5 Sonnet模型贡献了约2000个示例。这种合成方法确保了数据的多样性和复杂性,能够有效模拟真实世界中的结构化数据生成任务,为小型模型的微调提供了高质量的素材。
特点
该数据集的核心特点在于其专注于结构化数据生成,特别是JSON格式的生成。数据集包含三个关键字段:`query`、`schema`和`response`。`query`代表用户的无结构化文本查询,`schema`定义了期望的JSON输出结构,而`response`则是符合`schema`的模型响应示例。这种结构化的设计使得数据集特别适用于训练模型理解和生成复杂的JSON格式数据。
使用方法
使用JSON Training Data数据集时,研究者可以根据需要将`schema`字段整合到系统提示或用户消息中,以适应不同的结构化数据生成应用场景。这种灵活性使得数据集能够广泛应用于各种微调任务,帮助模型更好地理解和执行JSON格式的数据生成。通过这种方式,数据集不仅提升了模型的性能,还增强了其在处理复杂数据结构时的准确性和可靠性。
背景与挑战
背景概述
随着如Qwen2 0.5B和SmolLM 135M/360M等小型但强大的模型的出现,这些模型能够在几乎任何设备上运行,因此需要特定的数据来微调这些模型以应对下游任务。然而,这些模型在处理结构化数据生成,特别是JSON格式时表现不佳,甚至在使用强制JSON输出的框架时,模型也会陷入无限循环,因为它们无法理解任务要求。鉴于此,json-training数据集应运而生,旨在填补HuggingFace平台上缺乏优质JSON训练数据的空白。该数据集由Llama 3.1 8B和Claude 3.5 Sonnet等大型语言模型生成,包含`query`、`schema`和`response`三个字段,分别代表用户查询、期望的JSON模式和符合模式的模型响应。
当前挑战
json-training数据集面临的挑战主要体现在两个方面。首先,尽管该数据集旨在解决模型在生成结构化JSON数据时的困难,但如何确保生成的JSON数据既符合模式要求又具有实际应用价值仍是一个难题。其次,在数据集的构建过程中,依赖大型语言模型生成数据虽然提高了效率,但也带来了数据质量和多样性的挑战。如何确保生成的数据既准确又多样,避免模型在训练过程中出现过拟合或偏差,是构建过程中需要克服的关键问题。
常用场景
经典使用场景
在自然语言处理领域,JSON格式的数据生成一直是一个具有挑战性的任务。JSON Training数据集通过提供结构化的查询、模式和响应,为微调小型语言模型如Qwen2 0.5B和SmolLM 135M/360M提供了理想的训练材料。这些模型在生成符合特定JSON模式的响应时表现不佳,而该数据集通过提供大量合成数据,帮助模型更好地理解和生成结构化数据。
解决学术问题
JSON Training数据集解决了小型语言模型在生成结构化数据时的性能瓶颈问题。传统上,这些模型在生成JSON格式的响应时容易陷入无限循环或生成不符合预期的输出。该数据集通过提供明确的查询、模式和响应示例,帮助模型学习如何在特定模式下生成准确的JSON数据,从而提升了模型在结构化数据生成任务中的表现。
衍生相关工作
JSON Training数据集的发布催生了一系列相关研究工作,特别是在小型语言模型的微调和结构化数据生成领域。许多研究团队基于该数据集开发了新的微调框架和工具,进一步提升了模型在生成JSON数据时的表现。此外,该数据集还启发了更多关于如何利用合成数据提升模型性能的研究,推动了自然语言处理领域的技术进步。
以上内容由AI搜集并总结生成


