AppealCase
收藏arXiv2025-05-22 更新2025-05-24 收录
下载链接:
https://github.com/ythuang02/AppealCase/
下载链接
链接失效反馈官方服务:
资源简介:
AppealCase数据集包含了10,000对真实世界中的第一审和第二审判决书,涵盖了91种民事诉讼类型。该数据集还包括了关于五个方面的详细注释,这些方面对于上诉审查至关重要:判决逆转、逆转原因、引用的法律条文、索赔级别的决定以及第二审中是否有新信息。基于这些注释,我们提出了五个新的LegalAI任务,并在20个主流模型上进行了全面评估。实验结果表明,所有当前模型在判决逆转预测任务上的F1分数都不到50%,突出了上诉场景的复杂性和挑战性。我们希望AppealCase数据集能够激发LegalAI在上诉案件分析方面的进一步研究,并为提高司法决策的一致性做出贡献。
The AppealCase dataset contains 10,000 pairs of real-world first-instance and second-instance court judgment documents, covering 91 types of civil litigation. The dataset also includes detailed annotations on five aspects critical to appellate review: judgment reversal, reasons for reversal, cited legal provisions, claim-level rulings, and whether new information is introduced in the second instance. Based on these annotations, we propose five novel LegalAI tasks and conduct comprehensive evaluations on 20 mainstream models. Experimental results show that the F1 scores of all current models on the judgment reversal prediction task are less than 50%, highlighting the complexity and challenges of appellate scenarios. We hope that the AppealCase dataset will inspire further research on LegalAI for appellate case analysis and contribute to improving the consistency of judicial decision-making.
提供机构:
浙江大学, 中国
创建时间:
2025-05-22
搜集汇总
数据集介绍
构建方式
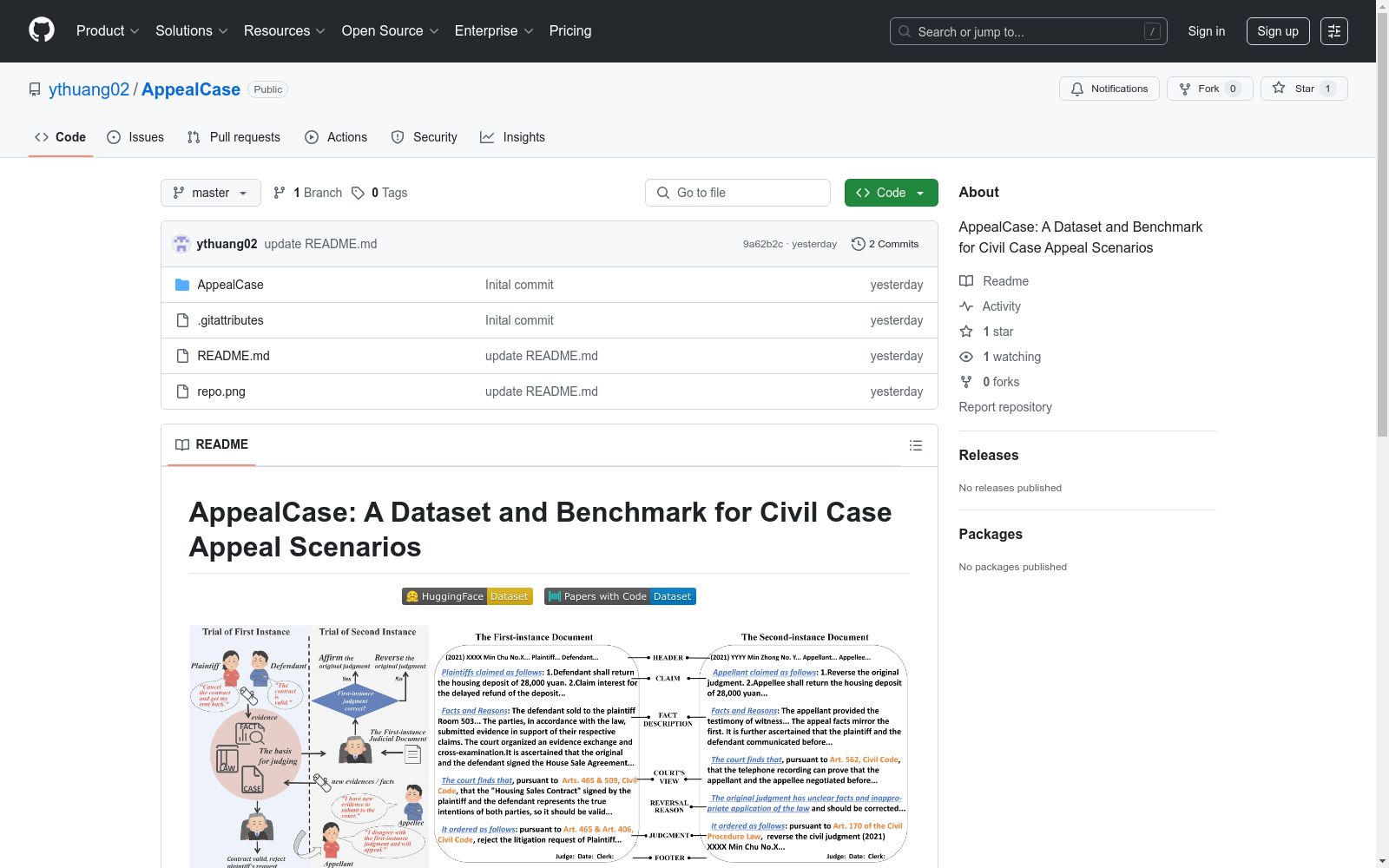
AppealCase数据集的构建采用了多层次的标注框架,结合规则/正则表达式、大语言模型和专家标注三种方法。首先,通过关键词模式将裁判文书分割为六个部分(标题、诉求、事实描述、法院观点、判决和页脚),并基于案件编号匹配一审和二审文书。随后,利用规则提取二审文书中提到的唯一一审案件编号,检索对应的一审文书以建立案件对。对于标注部分,数据集提供了五种类型的标签:判决反转、反转原因、诉求、法律条款和新信息。这些标签通过规则提取、大语言模型生成和专家审核相结合的方式进行标注,确保数据的准确性和一致性。
特点
AppealCase数据集包含10,000对真实世界的一审和二审文书,覆盖91类民事案件,其中50%的案件存在判决反转。数据集的特点在于其多层次标注,包括判决反转、反转原因(事实认定错误或法律适用错误)、诉求支持情况、引用的法律条款以及二审中是否引入新信息。此外,二审文书的平均长度显著长于一审文书,为模型处理长文本能力提供了挑战。数据集还通过专家评估确保了标注的准确性,超过99%的抽样案例被标记为准确。
使用方法
AppealCase数据集支持五种新的LegalAI任务,包括从一审和二审视角的判决反转预测、法律条款推荐、法律判决预测和二审法院观点生成。用户可以通过输入一审文书和二审诉求或事实描述,预测判决是否会被反转及其原因。数据集还可用于训练模型推荐相关法律条款或预测二审对诉求的支持情况。对于法院观点生成任务,模型需基于二审诉求和事实描述生成法院观点和判决。数据集的使用方法灵活多样,适用于不同场景下的法律AI研究和应用。
背景与挑战
背景概述
AppealCase数据集由浙江大学等机构的研究团队于2025年创建,旨在填补法律人工智能领域对上诉程序研究的空白。该数据集包含10,000对真实的一审和二审法律文书,涵盖91类民事案件,并围绕上诉审查的五个核心维度进行了详细标注。作为首个专注于上诉场景的司法数据集,其创新性地构建了匹配的双审级文书对,为研究司法决策一致性提供了重要资源。该数据集通过揭示上诉案件的特殊性,推动了法律AI从单次判决分析向连续性司法过程研究的范式转变,对提升司法系统纠错机制的可解释性具有显著意义。
当前挑战
在领域问题层面,上诉案例分析的复杂性体现在三方面:判决逆转预测需建模双审级文书间的逻辑关联,现有模型F1值普遍低于50%;法律条款推荐需处理动态更新的法规体系;法庭观点生成要求符合司法文书的严谨结构。在构建过程中,数据集面临多重挑战:文书配对需跨审级案例号精准匹配,中国裁判文书网的公开数据覆盖度不均衡;多维度标注依赖法律专家参与,特别是逆转原因分类涉及事实认定与法律适用的专业判断;长文本处理(平均4,818字符)对模型上下文理解能力提出更高要求。这些挑战共同构成了法律AI在上诉场景中的核心研究难点。
常用场景
经典使用场景
AppealCase数据集在司法智能领域具有广泛的应用前景,尤其在民事上诉案件分析中表现突出。该数据集通过匹配一审和二审判决文书,为研究者提供了丰富的案例资源,可用于分析上诉案件中的判决逆转模式、法律条款适用差异以及事实认定错误等核心问题。在司法实践中,该数据集能够帮助研究者深入理解上诉机制,探索判决一致性和司法公平性的内在规律。
衍生相关工作
围绕AppealCase数据集已衍生出多项重要研究工作。在模型开发方面,研究者基于该数据集提出了专门针对上诉场景优化的法律大语言模型。在任务拓展方面,衍生出了上诉理由生成、跨审级案例匹配等新研究方向。方法论上,催生了结合法律知识的增强推理、多任务联合学习等创新方法。这些工作显著推动了司法智能在上诉案件分析领域的发展,并为后续研究奠定了坚实基础。
数据集最近研究
最新研究方向
随着法律人工智能(LegalAI)领域的快速发展,AppealCase数据集的推出填补了上诉案件分析研究的空白。该数据集聚焦民事案件上诉场景,包含10,000对匹配的一审和二审裁判文书,覆盖91类案由,并标注了判决逆转、逆转原因等关键维度。当前研究热点集中在基于该数据集开发的五大创新任务:从一审和二审视角的判决逆转预测、法律条款推荐、判决预测以及法院观点生成。实验表明,现有大语言模型在判决逆转预测任务上的F1值普遍低于50%,凸显了上诉场景分析的复杂性。这一研究方向对于提升司法决策一致性、构建智能上诉辅助系统具有重要价值,也为探索法律文本长上下文理解、司法推理机制等前沿课题提供了新的实验平台。
相关研究论文
- 1AppealCase: A Dataset and Benchmark for Civil Case Appeal Scenarios浙江大学, 中国 · 2025年
以上内容由遇见数据集搜集并总结生成


