MADIS5-spoken-arabic-dialects
收藏Hugging Face2025-05-30 更新2025-05-31 收录
下载链接:
https://huggingface.co/datasets/badrex/MADIS5-spoken-arabic-dialects
下载链接
链接失效反馈官方服务:
资源简介:
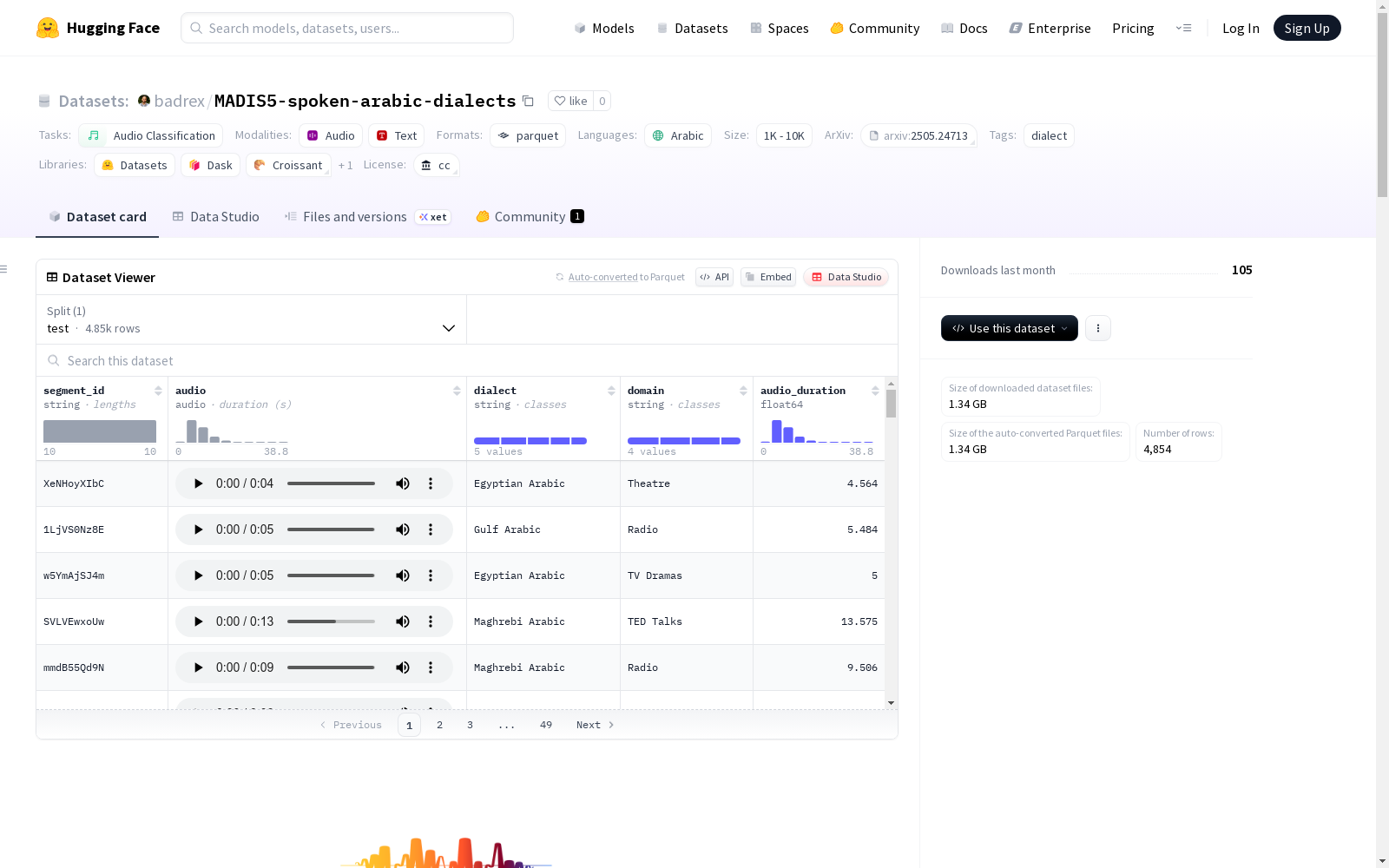
MADIS-5(多领域阿拉伯方言语音识别)是一个经过人工审核的数据集,旨在促进评估阿拉伯方言识别系统在不同领域的跨领域鲁棒性。该数据集为测试跨不同语音领域的离域泛化提供了一个全面的基准,涵盖不同的录制条件和说话风格。数据集包含约12小时的语音,共有4854个话语,涵盖5种主要的阿拉伯方言变体,包括现代标准阿拉伯语、埃及阿拉伯语、海湾阿拉伯语、黎凡特阿拉伯语和马格里布阿拉伯语。数据来自四个不同的公共来源,包括广播、电视剧、TEDx演讲和戏剧表演。
创建时间:
2025-05-28
原始信息汇总
MADIS 5: Multi-domain Arabic Dialect Identification in Speech 数据集概述
数据集基本信息
- 许可证: Creative Commons Attribution-NonCommercial-NoDerivs 4.0 (CC BY-NC-ND 4.0)
- 任务类别: 音频分类
- 语言: 阿拉伯语 (ar)
- 标签: 方言 (dialect)
- 数据集规模: 1K<n<10K
- 下载大小: 1,338,284,576 字节
- 数据集大小: 1,354,672,655.25 字节
数据特征
- 特征字段:
segment_id: 字符串类型audio: 音频类型,采样率16kHzdialect: 字符串类型domain: 字符串类型audio_duration: 浮点型
- 数据划分:
test: 4,854个样本,1,354,672,655.25字节
数据集统计
- 总时长: ~12小时语音
- 总话语数: 4,854条
- 语言/方言: 5种主要阿拉伯语变体
- 现代标准阿拉伯语 (MSA)
- 埃及阿拉伯语
- 海湾阿拉伯语
- 黎凡特阿拉伯语
- 马格里布阿拉伯语
- 领域: 4种不同口语领域
- 收集时间: 2024年11月 - 2025年2月
数据来源
-
广播电台
- 来源: 通过radio.garden收集的阿拉伯世界本地电台
- 特点: 更随意、自发的语音
- 领域相似性: 与现有ADI基准高度相似
-
电视剧
- 来源: Kaggle上的阿拉伯口语方言区域档案(SARA)
- 特点: 5-7秒对话语音片段
- 领域相似性: 相似度低,更多对话
-
TEDx演讲
- 来源: TEDx数据集的阿拉伯语部分
- 特点: 教育内容演讲
- 领域相似性: 中等相似度
-
戏剧
- 来源: 来自不同阿拉伯国家的YouTube戏剧和喜剧
- 特点: 不同时期的戏剧表演
- 领域相似性: 相似度低
标注过程
- 质量保证:
- 主要标注者: 阿拉伯语母语者,计算语言学博士
- 验证: 由第二位阿拉伯语母语专家独立验证
- 标注一致性:
- 完全一致: 97.7%样本
- 不一致: 2.3%(主要在广播片段中MSA与方言分类)
使用场景
- 阿拉伯语方言识别系统的跨领域鲁棒性评估
- ADI模型在不同语音领域的基准测试
- 阿拉伯语语音处理中领域适应的研究
- 开发更鲁棒的阿拉伯语方言分类器
数据集优势
- 领域多样性: 四种不同语音领域
- 专家标注: 高质量语言学专家标注
- 跨领域重点: 专门设计用于测试模型在单一领域外的鲁棒性
- 真实场景: 涵盖各种语境中的真实语音
引用
bibtex @inproceedings{abdullah2025voice, title={Voice Conversion Improves Cross-Domain Robustness for Spoken Arabic Dialect Identification}, author={Abdullah, Badr M. and Matthew Baas and Bernd Möbius and Dietrich Klakow}, year={2025}, publisher={Interspeech}, url={https://huggingface.co/datasets/badrex/MADIS5-spoken-arabic-dialects} }
致谢
感谢所有数据来源和平台的贡献者,包括radio.garden、SARA档案和多语言TEDx数据集。
搜集汇总
数据集介绍
构建方式
在阿拉伯语方言识别研究领域,MADIS-5数据集通过精心设计的跨域采集策略构建而成。该数据集整合了广播、电视剧、TEDx演讲和戏剧表演四大领域的语音样本,每个领域均代表不同的录音条件与说话风格。所有语音片段均经过语言学专家的人工分割与标注,并由两位母语为阿拉伯语的专家进行独立验证,最终达成97.7%的标注一致性,确保了数据标签的高可靠性。
使用方法
研究者可利用该数据集进行阿拉伯语方言识别系统的跨域鲁棒性验证,尤其适用于域适应与泛化能力研究。数据以16kHz采样率的音频片段呈现,并附带方言标签与领域分类信息。通过划分测试集可直接评估模型在未知领域的表现,其多域特性支持对比分析不同录音条件下模型的稳定性,为语音技术在实际应用中的部署提供重要参考依据。
背景与挑战
背景概述
阿拉伯语方言识别作为计算语言学的重要分支,旨在解决语音信号中方言变体的自动分类问题。MADIS-5数据集由萨尔兰大学等研究机构于2024年至2025年联合构建,聚焦于五大阿拉伯语变体(现代标准阿拉伯语、埃及、海湾、黎凡特及马格里布方言)的跨领域鲁棒性评估。该数据集通过整合广播、电视剧、TED演讲及戏剧等四类语音域,填补了现有研究在多样化场景适应性的空白,为语音技术在中东地区的实际应用提供了关键基准。
当前挑战
阿拉伯语方言连续体现象导致方言与标准语边界模糊,尤其在广播场景中MSA与方言的声学特征重叠构成核心分类挑战。数据集构建需克服多源数据异构性:剧场录音存在历史音频质量波动,电视剧对话需人工切分语轮转折,而TED演讲的正式语体与日常方言差异显著。跨领域标注一致性要求语言学专家通过多轮协商解决2.3%的标注分歧,凸显了方言语音数据标准化处理的复杂性。
常用场景
经典使用场景
在阿拉伯语方言识别研究中,MADIS-5数据集作为跨领域鲁棒性评估的基准工具,其经典应用场景集中于测试语音识别模型在广播、戏剧、演讲和剧场等多元语音域中的泛化能力。该数据集通过包含不同录音条件和说话风格的语音样本,使研究者能够系统评估模型在面对域外数据时的表现,从而推动方言识别技术在实际复杂环境下的应用。
解决学术问题
该数据集有效解决了阿拉伯语方言识别领域中的域适应难题,特别是模型在单一训练域上过拟合而难以泛化至新领域的问题。通过提供四个差异显著的语音域数据,MADIS-5支持了对跨域鲁棒性的量化分析,促进了领域自适应方法和泛化理论的研究,为构建更具实用价值的方言识别系统奠定了数据基础。
实际应用
在实际应用中,MADIS-5数据集可服务于智能语音助手、内容审核系统及教育平台,帮助提升其对阿拉伯语不同方言变体的理解精度。例如,在媒体内容自动化分类中,该系统能准确识别广播节目或戏剧对话中的方言类型,进而支持个性化内容推荐或方言特定的语音交互服务,增强技术在中东及北非地区的适用性。
数据集最近研究
最新研究方向
在阿拉伯语方言识别领域,MADIS-5数据集正推动跨领域鲁棒性研究的前沿探索。该数据集整合广播、戏剧、演讲和剧场四大语音域,为方言识别系统在真实多变场景下的泛化能力提供基准。当前研究聚焦于利用语音转换技术增强模型对领域差异的适应性,特别是在低相似度领域如剧场表演中的艺术化语音处理。这一方向呼应了多模态人工智能对语言多样性建模的需求,为阿拉伯语语音技术在媒体监测、教育服务等实际应用奠定了重要基础。
以上内容由遇见数据集搜集并总结生成


