danilotpnta/GTZAN_genre_classification
收藏Hugging Face2024-07-03 更新2024-06-29 收录
下载链接:
https://hf-mirror.com/datasets/danilotpnta/GTZAN_genre_classification
下载链接
链接失效反馈官方服务:
资源简介:
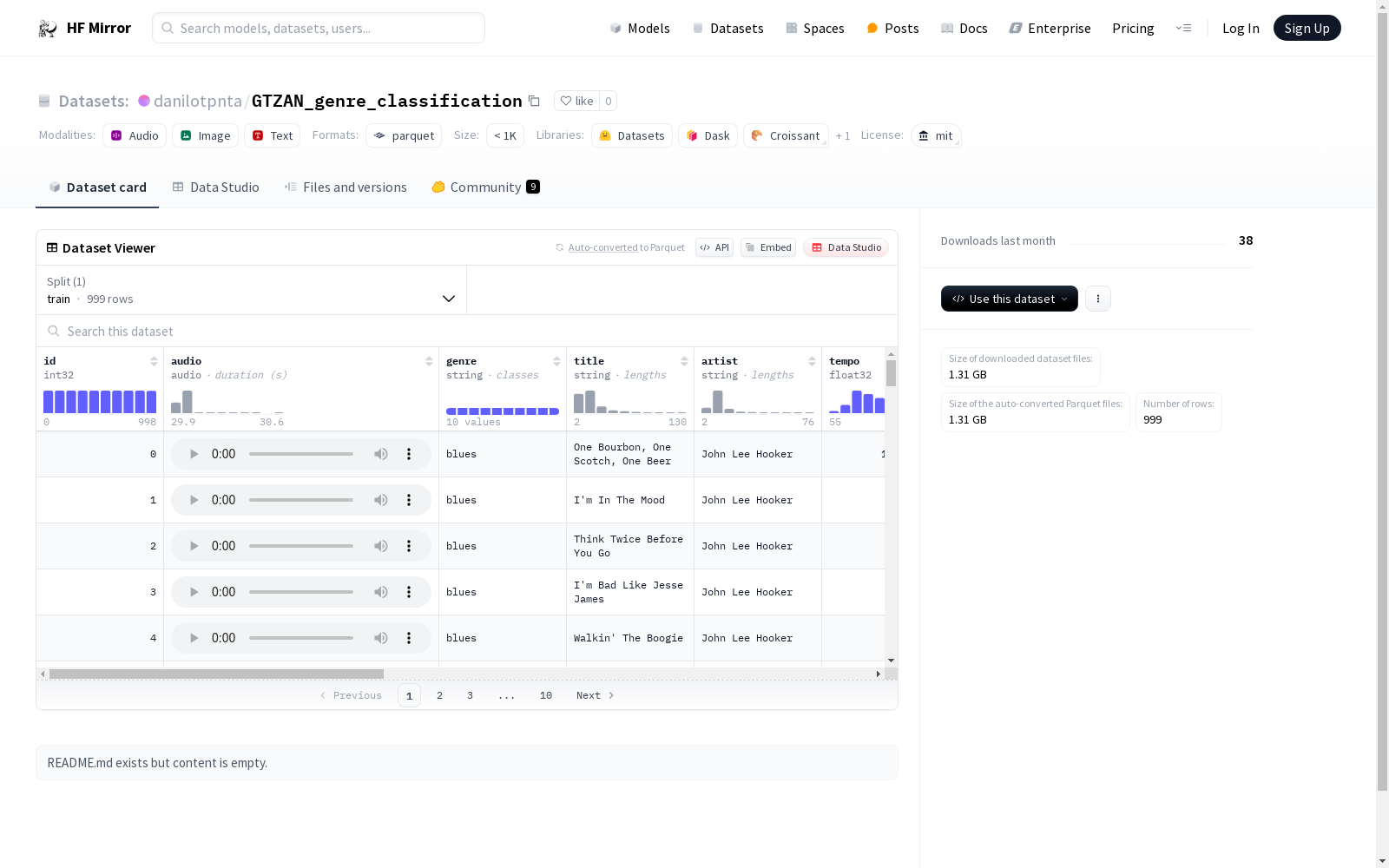
该数据集包含999个音频样本,每个样本具有多个特征,包括id、音频数据、流派、标题、艺术家、节奏、键、响度、预测流派排序以及t-SNE和UMAP的坐标。数据集主要用于音频分析和音乐流派分类任务。
This dataset contains 999 audio samples, each with multiple features including id, audio data, genre, title, artist, tempo, key, loudness, sorted predicted genres, and t-SNE and UMAP coordinates. The dataset is primarily used for audio analysis and music genre classification tasks.
提供机构:
danilotpnta
原始信息汇总
GTZAN 数据集概述
数据集信息
- 配置名称: gtzan
- 特征:
- id: 整数类型 (int32)
- audio: 音频类型,采样率为 44100 Hz
- genre: 字符串类型
- title: 字符串类型
- artist: 字符串类型
- tempo: 浮点类型 (float32)
- keys: 字符串类型
- loudness: 浮点类型 (float32)
- sorted_pred_genres: 字符串类型
- x_tsne: 浮点类型 (float32)
- y_tsne: 浮点类型 (float32)
- z_tsne: 浮点类型 (float32)
- x_umap: 浮点类型 (float32)
- y_umap: 浮点类型 (float32)
- z_umap: 浮点类型 (float32)
数据集分割
- 训练集:
- 样本数: 999
- 数据大小: 1323109027.0 字节
数据集大小
- 下载大小: 1305734429 字节
- 数据集大小: 1323109027.0 字节
配置
- 配置名称: gtzan
- 数据文件:
- 训练集路径: gtzan/train-*
- 默认配置: 是
- 数据文件:
搜集汇总
数据集介绍
构建方式
danilotpnta/GTZAN_genre_classification数据集的构建基于GTZAN数据库,该数据库是音乐研究领域常用的数据集。数据集通过搜集具有不同音乐风格的歌曲,每首歌曲包含音频文件及相关元信息,如曲风、歌曲标题、艺术家、音量、音高等,进而构建成一个多维度特征的数据集。数据集的音频采样率为44100Hz,确保了音频质量。构建过程中,数据被分为训练集,共999个样本,为模型的训练提供了丰富的学习素材。
特点
该数据集显著的特点在于其丰富的音乐元信息,不仅包含音频文件,还涵盖了曲风、艺术家、歌曲标题等文本信息,以及音量、音高、节奏等音频特征信息。此外,数据集还提供了降维后的特征表示,如t-SNE和UMAP,有助于降低数据维度,便于可视化与分析。其多样化的特征为音乐风格识别、音乐信息检索等研究提供了坚实基础。
使用方法
在使用danilotpnta/GTZAN_genre_classification数据集时,用户首先需要根据MIT许可证的规定合理使用数据。数据集可通过HuggingFace的API进行下载,之后用户可以根据需要,将音频数据和元信息导入至相应的数据处理环境中。由于数据集已经包含了预处理后的降维特征,用户可以直接利用这些特征进行模型训练或数据分析,提高了研究的效率。
背景与挑战
背景概述
在音频信号处理与音乐信息检索领域,音乐风格分类是研究的重要方向之一。GTZAN_genre_classification数据集,创建于21世纪初,由丹尼尔·托平塔(Danilo T. P. da Silva)等研究人员构建,旨在解决音乐风格自动分类问题。该数据集汇集了多种音乐风格,提供了音频文件的元数据,如音乐流派、曲名、艺术家、音量、音高等信息,对于音乐信息检索领域产生了深远的影响,成为相关研究的基石。
当前挑战
GTZAN_genre_classification数据集面临的挑战主要涉及两个方面:首先,音乐风格分类本身具有模糊性,不同人对同一音乐片段的风格感知可能存在差异,这对算法的准确性和泛化能力提出了挑战。其次,在构建过程中,数据集的多样性和平衡性是关键因素,而该数据集在样本的分布上可能存在一定的偏差,这影响了模型的公正性和可靠性。
常用场景
经典使用场景
在音乐信息检索领域,danilotpnta/GTZAN_genre_classification数据集的经典使用场景是对音频文件进行音乐风格分类。该数据集提供了音频文件的采样率、风格、曲名、艺术家、节奏、音调、响度等信息,研究者可以利用这些特征训练机器学习模型,以实现对未知音乐片段的风格自动识别。
解决学术问题
该数据集解决了音乐风格分类中的标注不足、特征提取困难等学术研究问题。通过提供标准化的音频特征和预定的分类标签,它为研究者提供了一个统一的实验平台,有助于推动音乐风格识别算法的准确性和泛化能力的研究。
衍生相关工作
基于该数据集,研究者们衍生出了一系列相关工作,如音乐风格识别算法的改进、音频特征提取方法的研究、以及多模态音乐信息处理等。这些工作进一步拓展了音乐信息检索领域的研究边界,丰富了相关学术研究的内涵。
以上内容由遇见数据集搜集并总结生成


