egyptian-dialogue
收藏Hugging Face2025-12-22 更新2025-12-23 收录
下载链接:
https://huggingface.co/datasets/fr3on/egyptian-dialogue
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含4,322个埃及阿拉伯语-英语平行对话对,具有自动领域分类功能。数据来源于电视剧字幕,包含自然的埃及阿拉伯语方言对话(العامية المصرية)。数据集支持多种自然语言处理任务,如翻译模型训练、方言研究、会话人工智能等。
创建时间:
2025-12-17
原始信息汇总
Egyptian Arabic Dialogue Dataset 数据集概述
数据集基本信息
- 数据集名称:Egyptian Arabic Dialogue Dataset
- 发布者:fr3on
- 发布日期:2025-12-17 (v1.0.0)
- 许可证:CC BY 4.0
- 语言:
- 源语言:埃及阿拉伯语 (ar_EG) - 口语方言
- 目标语言:英语 (en)
- 任务类别:翻译、文本生成
- 标签:egyptian-arabic, dialect, colloquial, ar_EG, translation, dialogue, subtitles, domain-classification
- 数据规模:1K<n<10K
- 数据格式:Parquet
数据集描述
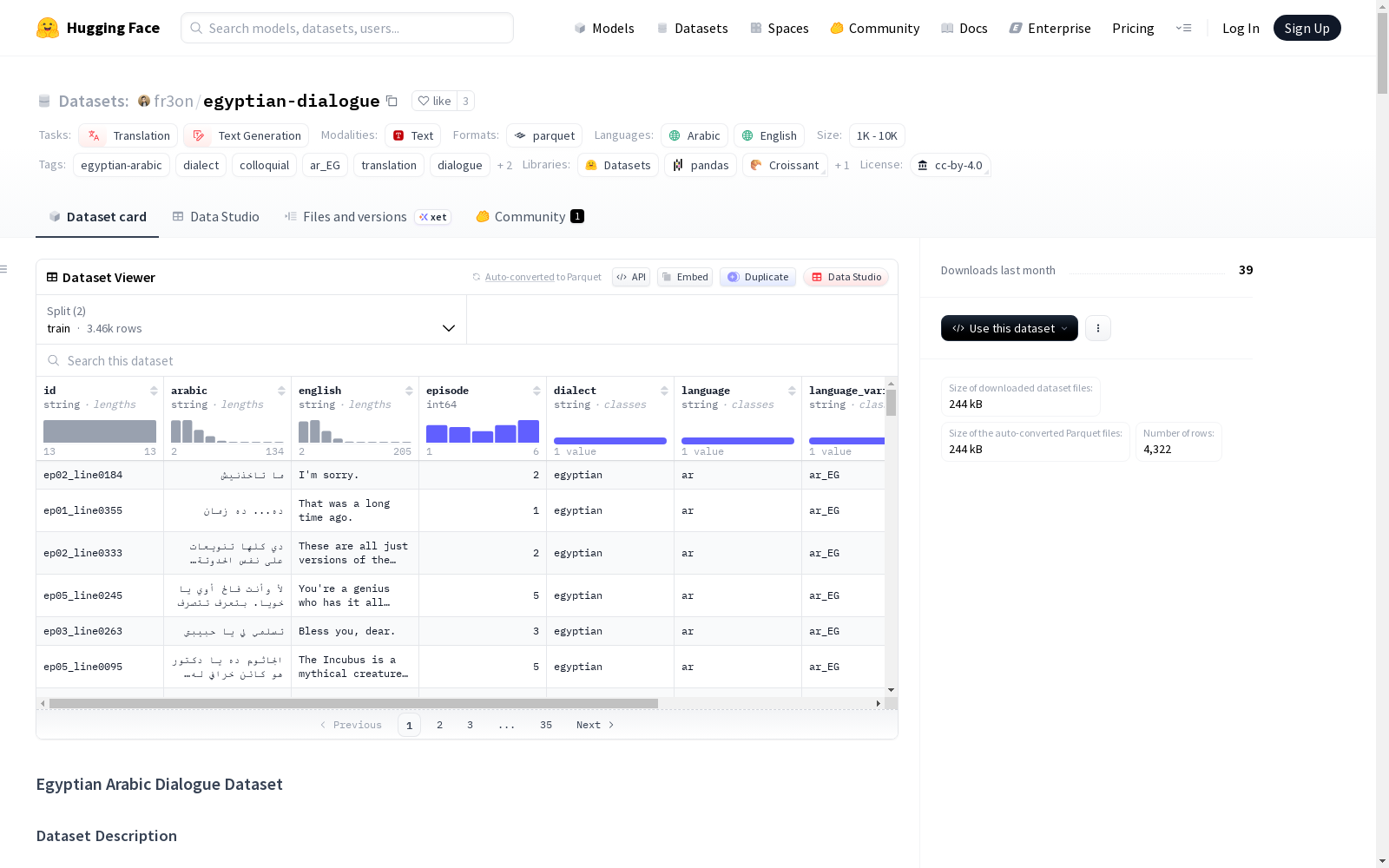
该数据集包含 4,322 个平行的埃及阿拉伯语-英语对话对,并带有自动领域分类。数据提取自电视剧字幕,具有自然的埃及阿拉伯语方言 (العامية المصرية) 对话特征。
数据集结构
数据格式
每个条目为JSON格式,包含以下字段:
id:唯一标识符 (格式: epXX_lineYYYY)arabic:埃及阿拉伯语文本english:英语翻译episode:剧集编号 (用于上下文)dialect:方言标识符 (始终为 "egyptian")language:ISO语言代码 (始终为 "ar")language_variant:特定变体代码 (始终为 "ar_EG")genre:内容类型 (dialogue/narration)domain:自动检测的内容领域
数据集统计
概览
- 总条目数:4,322
- 剧集数:6
- 唯一领域数:18
- 唯一类型数:2
- 阿拉伯语平均长度:25.9 字符
- 英语平均长度:35.0 字符
领域分布
| 领域 | 数量 | 百分比 |
|---|---|---|
| general | 2,143 | 49.6% |
| technology | 531 | 12.3% |
| family | 368 | 8.5% |
| horror | 281 | 6.5% |
| medical | 233 | 5.4% |
| romance | 136 | 3.1% |
| weather | 115 | 2.7% |
| food | 104 | 2.4% |
| paranormal | 86 | 2.0% |
| social | 55 | 1.3% |
剧集分布
| 剧集 | 条目数 |
|---|---|
| Episode 1 | 889 |
| Episode 2 | 782 |
| Episode 3 | 584 |
| Episode 4 | 907 |
| Episode 5 | 554 |
| Episode 6 | 606 |
类型分布
- dialogue:4,301 (99.5%)
- narration:21 (0.5%)
涵盖领域
该数据集包含通过基于关键词检测的自动领域分类,涵盖以下领域: general, family, horror, medical, technology, romance, paranormal, weather, food, social, crime, education, sports, entertainment, legal, news, business, politics。
推荐用途
- 埃及阿拉伯语翻译:专门针对埃及方言训练翻译模型
- 领域特定模型:为特定领域 (医疗、法律等) 训练模型
- 方言研究:研究埃及阿拉伯语特征
- 对话式AI:为埃及用户构建聊天机器人
- 语言建模:在埃及方言上进行预训练或微调
- 多领域学习:训练具有内容领域感知的模型
局限性
- 领域范围:仅限于娱乐/对话领域内容
- 语体:仅包含对话/非正式语言
- 规模:4,322 个条目 (对于大规模预训练相对较小)
- 方言变异:未涵盖埃及阿拉伯语的地区次方言
- 上下文:单个对话行可能缺乏更广泛的叙事上下文
数据收集与处理
来源
- 来源:埃及电视剧字幕
- 语言:专业字幕翻译
- 质量:自然、对话式的埃及阿拉伯语
处理流程
- 提取:从Excel字幕文件加载
- 清洗:删除空行、非常短的条目
- 去重:基于哈希的重复项移除 (移除了945个重复项)
- 领域检测:使用关键词匹配进行自动分类
- 类型分类:自动检测对话与叙述
- 验证:质量检查和统计信息生成
数据质量
- 使用MD5哈希匹配进行去重
- 过滤少于2个字符的条目
- 删除缺少翻译的行
- 标准化空白字符
- 验证阿拉伯语和英语文本对
使用注意事项
埃及阿拉伯语特点
埃及阿拉伯语与现代标准阿拉伯语 (MSA) 有显著差异:
- 词汇:独特的口语词汇
- 语法:简化结构
- 发音:不同的语音
- 文字:口语语境中的非正式拼写约定
推荐训练方法
- 微调多语言模型,而非从头开始训练
- 结合MSA数据以获得更好的阿拉伯语理解
- 使用领域过滤进行专门应用
- 考虑剧集上下文用于叙事任务
- 如果训练通用模型,平衡领域分布
伦理考量
- 方言代表性:埃及阿拉伯语是众多阿拉伯语方言之一
- 文化背景:翻译保留了文化细微差别
- 来源归属:数据来自电视剧字幕
- 隐私:不包含个人信息
引用
若在研究中使用此数据集,请引用: bibtex @dataset{egyptian_dialogue_2026, title={Egyptian Arabic Dialogue Dataset}, author={fr3on}, year={2025}, publisher={Hugging Face}, url={https://huggingface.co/datasets/fr3on/egyptian-dialogue} }
版本历史
- v1.0.0 (2025-12-17):初始发布
- 4,322 个条目
- 18 个领域类别
- 自动领域检测
- Parquet 格式
搜集汇总
数据集介绍
构建方式
在阿拉伯语方言研究领域,埃及阿拉伯语因其广泛的使用人口而备受关注。该数据集的构建源于对自然口语对话资源的系统化采集,其核心内容提取自埃及电视剧的字幕文件。构建过程遵循严谨的流水线:首先从原始Excel字幕文件中提取文本对,随后进行数据清洗以移除空行与过短条目,并基于MD5哈希值执行去重处理,共剔除了945个重复项。为进一步增强数据实用性,构建流程引入了基于关键词匹配的自动领域分类机制,将对话内容划分为包括通用、技术、家庭、医疗在内的18个不同领域,同时自动识别对话与叙述两种文体,最终形成包含4,322个平行句对的结构化语料库。
特点
该数据集在方言机器翻译资源中展现出鲜明的特色。其首要特征在于语料的真实性与自然度,所有埃及阿拉伯语句子均源自电视剧对话,完整保留了该方言的口语词汇、简化语法及非正式拼写习惯。数据集提供了精细的领域标注,覆盖从日常生活到专业话题的广泛光谱,这为训练领域敏感的模型奠定了坚实基础。每个数据条目均附带剧集编号,为理解对话的叙事语境提供了可能。数据规模虽适中,但经过严格的质量控制,确保了双语对齐的准确性与文本的规范性,使其成为研究埃及阿拉伯语语言特性与构建针对性应用模型的宝贵资源。
使用方法
针对自然语言处理任务,该数据集提供了灵活的应用途径。研究者可通过Hugging Face的`datasets`库直接加载,并利用其内置的过滤功能,便捷地按特定领域或剧集筛选子集,例如专注于医疗或技术领域的数据以训练专业化模型。数据集主要适用于埃及阿拉伯语至英语的机器翻译模型训练,建议采用微调现有多语言模型而非从头训练的策略。此外,其领域标签支持多领域学习或领域自适应研究,可用于探究模型在不同内容主题下的表现。在模型开发时,可考虑结合现代标准阿拉伯语数据以提升模型的泛化能力,并注意平衡各领域的数据分布以确保训练效果。
背景与挑战
背景概述
埃及阿拉伯语对话数据集由研究者fr3on于2025年构建并发布,旨在应对阿拉伯语自然语言处理领域内方言资源稀缺的核心问题。该数据集聚焦于埃及阿拉伯语这一拥有逾一亿使用者的重要方言变体,从电视剧字幕中提取了4322条平行对话语料,并辅以自动领域分类。其创建填补了针对埃及方言的机器翻译与对话系统训练数据的空白,为方言计算语言学、领域自适应翻译模型以及面向埃及用户的对话智能体开发提供了关键资源。
当前挑战
该数据集致力于解决阿拉伯语方言机器翻译与理解这一领域难题,其核心挑战在于埃及阿拉伯语与现代标准阿拉伯语在词汇、语法及正字法上存在显著差异,且缺乏大规模高质量标注资源。在构建过程中,挑战主要源于数据源的局限性与处理复杂性:从影视字幕提取的语料虽具自然对话特性,但规模相对有限,且涵盖的领域与语域集中于娱乐性对话;自动领域分类依赖关键词匹配,可能无法完全捕捉语义细微差别;此外,数据清洗需处理重复项、短句过滤及上下文信息缺失等问题,以确保语料质量与适用性。
常用场景
经典使用场景
在阿拉伯语自然语言处理领域,埃及阿拉伯语作为使用人口超过一亿的方言,其口语化表达与标准阿拉伯语存在显著差异。该数据集通过提取电视剧字幕构建了平行对话语料,为机器翻译模型提供了针对埃及方言的训练资源。经典使用场景聚焦于方言翻译模型的微调,研究者利用其自然对话内容和领域分类标签,训练能够准确处理埃及口语中独特词汇、语法及文化隐喻的翻译系统,有效弥合方言与标准语之间的语义鸿沟。
衍生相关工作
围绕该数据集衍生的经典工作主要集中在方言自适应机器翻译与多领域对话建模。研究者常以其为基准,评估如mBART、AraT5等预训练模型在埃及方言上的微调效果。相关工作亦探索了结合领域标签的混合训练策略,以提升模型在医疗、技术等专业场景的翻译鲁棒性。部分研究进一步利用其对话结构,开展叙事连贯性分析或语境感知的生成任务,推动了方言对话系统向更自然、更具上下文理解能力的方向演进。
数据集最近研究
最新研究方向
在阿拉伯语自然语言处理领域,埃及方言作为使用人口最广泛的阿拉伯语变体,其资源稀缺性长期制约着方言级模型的发展。该数据集凭借其从电视剧字幕中提取的真实对话语料,为埃及阿拉伯语的前沿研究提供了关键支撑。当前研究焦点集中于利用其领域分类特征,探索多领域自适应机器翻译模型,旨在提升方言在医疗、法律等专业场景下的翻译准确性。同时,数据集中的自然对话特性正推动着面向埃及用户的个性化对话生成系统的构建,此类系统能够更精准地捕捉方言中的口语习惯与文化隐喻。这些研究方向不仅响应了中东地区数字服务本地化的迫切需求,也为低资源方言的表示学习与跨语言迁移提供了新的实证路径。
以上内容由遇见数据集搜集并总结生成


