mag7-stock-prediction
收藏资源简介:
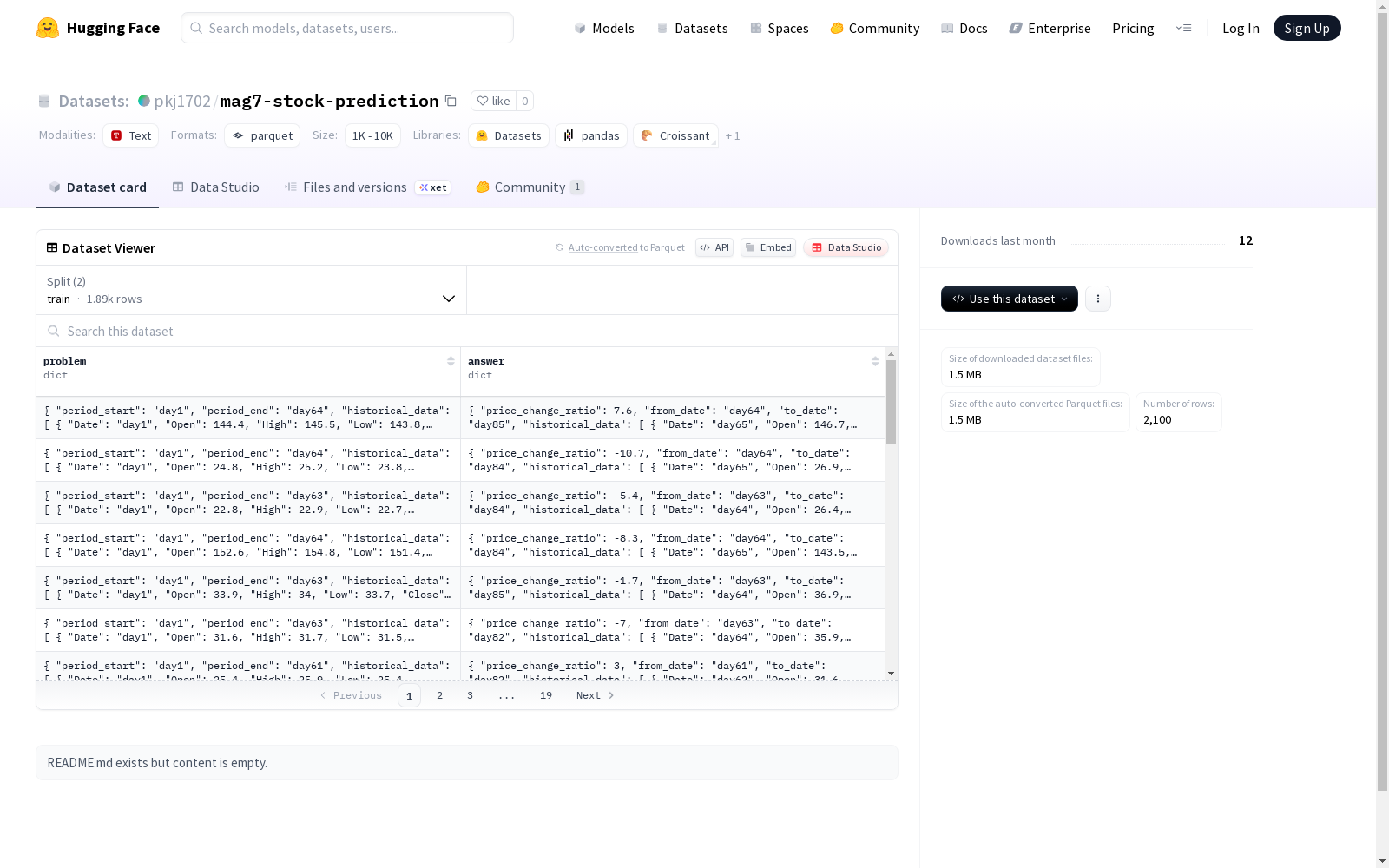
这是一个包含金融股票市场数据的数据集,主要包含两个部分:问题(problem)和答案(answer)。问题部分提供了时间段起始和结束的时间戳,以及该时间段内的历史股价数据,包括日期、开盘价、最高价、最低价、收盘价和成交量。答案部分提供了价格变动比例以及变动期间的起始和结束日期,同样也包括了历史股价数据。数据集分为训练集和测试集,可用于机器学习模型的训练和评估。
This is a dataset focused on financial stock market data, which is primarily divided into two components: the problem set and the answer set. The problem set provides the start and end timestamps of a target time period, along with the historical stock price data of that period, including date, opening price, highest price, lowest price, closing price, and trading volume. The answer set provides the price change ratio, as well as the start and end dates of the price change period, alongside the corresponding historical stock price data. The dataset is split into a training set and a test set, which can be employed for the training and evaluation of machine learning models.
数据集概述
基本信息
- 数据集名称: mag7-stock-prediction
- 下载大小: 6,132,916 字节
- 数据集大小: 47,607,228 字节
数据集结构
特征
- problem:
- period_start: 字符串类型
- period_end: 字符串类型
- historical_data:
- Date: 字符串类型
- Open: float64 类型
- High: float64 类型
- Low: float64 类型
- Close: float64 类型
- Volume: int64 类型
- answer:
- price_change_ratio: float64 类型
- from_date: 字符串类型
- to_date: 字符串类型
- historical_data:
- Date: 字符串类型
- Open: float64 类型
- High: float64 类型
- Low: float64 类型
- Close: float64 类型
- Volume: int64 类型
数据集划分
- train:
- 样本数量: 6,616
- 字节大小: 44,996,598 字节
- test:
- 样本数量: 384
- 字节大小: 2,610,630 字节
配置文件
- config_name: default
- train: data/train-*
- test: data/test-*