CloudPerfTrace
收藏arXiv2025-09-03 更新2025-09-05 收录
下载链接:
https://huggingface.co/datasets/AmirShahbaz/CloudPerfTrace
下载链接
链接失效反馈官方服务:
资源简介:
CloudPerfTrace是一个丰富且精细的数据集,包含206个系统级指标,时间分辨率达到每秒,涵盖了11个云应用程序,覆盖了静态和动态工作负载场景。数据集的收集过程考虑到了虚拟机环境的黑盒特性,为训练和评估云性能预测模型提供了宝贵的数据资源。该数据集旨在解决多租户云环境中虚拟机性能下降预测的挑战,特别是针对动态工作负载场景。
CloudPerfTrace is a rich and fine-grained dataset that contains 206 system-level metrics with a time resolution of one second. It covers 11 cloud applications and spans both static and dynamic workload scenarios. The dataset collection process accounts for the black-box characteristics of virtual machine environments, providing a valuable data resource for training and evaluating cloud performance prediction models. This dataset is designed to address the challenge of virtual machine performance degradation prediction in multi-tenant cloud environments, especially in dynamic workload scenarios.
提供机构:
瑞士洛桑联邦理工学院(EPFL)和西班牙马德里康普顿斯大学(UCM)
创建时间:
2025-09-03
原始信息汇总
数据集概述
基本信息
- 许可证: CC BY 4.0
- 格式: Parquet
- 存储结构: 按应用任务分区存储
- 数据覆盖: 317天追踪记录
任务ID与应用类型对应关系
| 任务ID | 应用类型 |
|---|---|
| 4 | Data Serving |
| 5 | Redis |
| 6 | Web Search |
| 7 | Graph Analytics |
| 9 | Data Analytics |
| 10 | MLPerf |
| 11 | HBase |
| 13 | Alluxio |
| 14 | Minio |
| 15 | TPC-C |
| 16 | Flink |
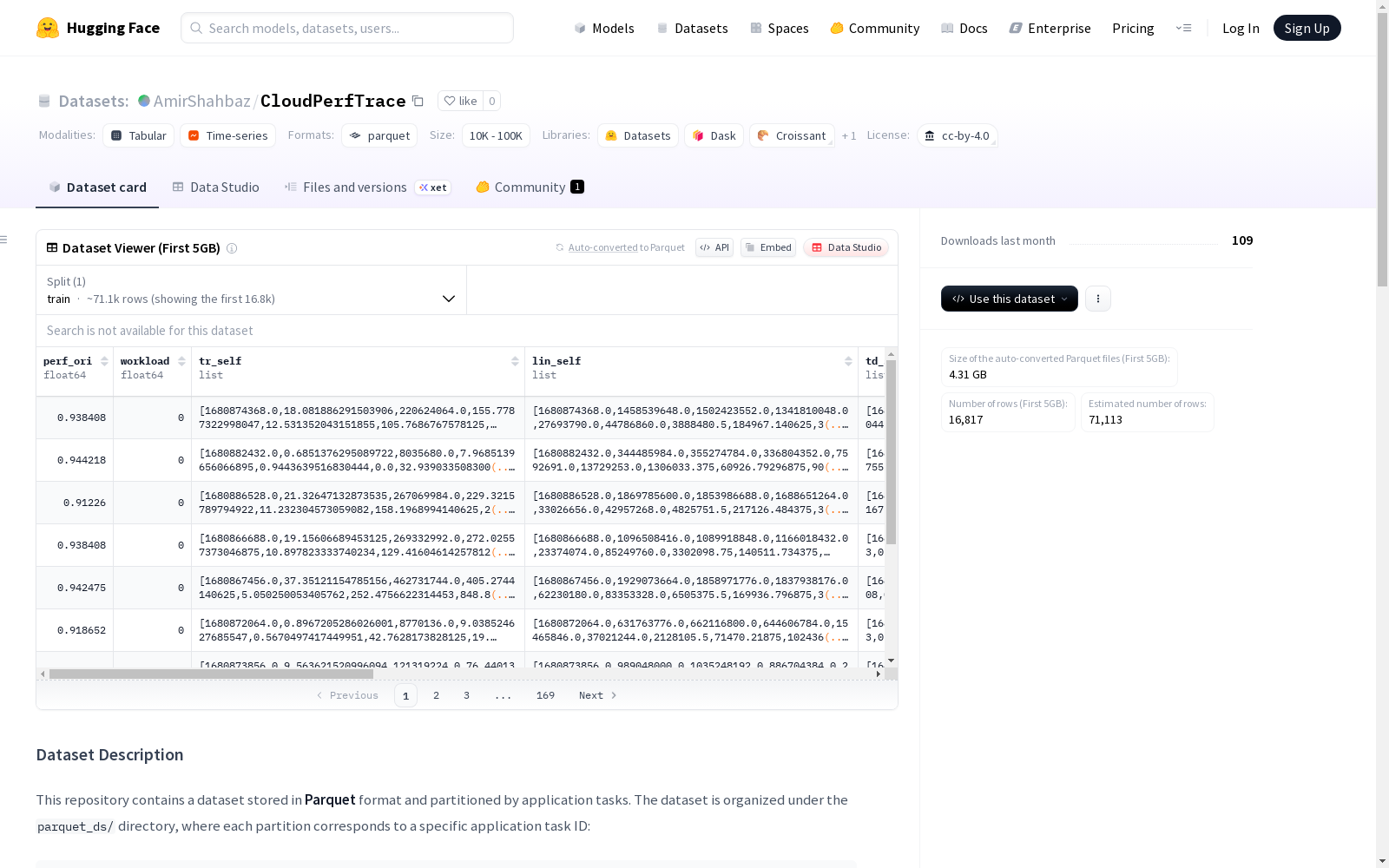
数据模式
性能指标
- perf_ori (double): 标准化性能水平(0-1范围)
- workload (double): 工作负载级别数值标识符
目标应用监控指标
- tr_self: 目标应用的虚拟机指标
- lin_self: 目标应用的Linux Perf指标
- td_self: 目标应用的Top-Down分析指标
邻居虚拟机监控指标
- tr_oth: 共置邻居虚拟机的虚拟机指标
- lin_oth: 邻居虚拟机的Linux Perf指标
- td_oth: 邻居虚拟机的Top-Down分析指标
分区键
- tasks (int32): 应用任务ID(分区键)
数据加载方式
使用PyArrow加载数据集: python import pyarrow.dataset as ds dataset = ds.dataset("parquet_ds", format="parquet", partitioning="hive")
搜集汇总
数据集介绍
构建方式
在云计算性能分析领域,CloudPerfTrace数据集通过精心设计的实验环境构建而成。研究团队采用配备双Intel Xeon Gold处理器的测试服务器,基于libvirt、QEMU和KVM虚拟化栈创建多租户环境,每个虚拟机配置4vCPU和8GB内存。通过Linux perf工具、libvirt API和Intel顶层分析方法,以每秒分辨率持续采集两个月数据,涵盖11种云应用的静态与动态工作负载场景,最终形成包含206个系统指标的标准化数据集。
特点
该数据集的核心价值体现在其前所未有的时间粒度与指标广度。相较于现有基准测试,CloudPerfTrace以每秒时间分辨率捕获系统行为,涵盖虚拟机级指标、硬件计数器及性能瓶颈分析等多元维度。数据集包含317天的连续监测记录,不仅包含稳态工作负载,还创新性地引入单调递增、周期波动和随机变化三种动态场景,为研究瞬时性能干扰效应提供了丰富的时间序列特征。
使用方法
研究人员可利用该数据集训练和验证云端性能预测模型。数据集已按应用类型划分为训练集与测试集,其中7个应用用于模型训练,4个未见应用用于泛化能力评估。使用时需先对206维指标进行标准化处理,随后可构建时序预测模型或系统交互分析模型。数据集支持性能退化指标的定量计算,即通过理想性能指标与实际观测值的比率来量化干扰程度,为资源调度算法提供关键数据支撑。
背景与挑战
背景概述
CloudPerfTrace数据集由瑞士洛桑联邦理工学院(EPFL)与马德里康普顿斯大学(UCM)联合研究团队于2025年创建,旨在解决云计算多租户环境中虚拟机性能退化预测的核心问题。该数据集通过采集11种云应用的206项系统级指标(每秒分辨率),覆盖静态与动态工作负载场景,为黑盒虚拟机环境下的性能建模提供了高粒度数据支持。其创新性在于突破了传统数据集在时间分辨率与指标多样性方面的局限,为云资源调度与性能隔离研究提供了关键基准,对提升云计算服务质量与能效优化具有显著影响力。
当前挑战
该数据集主要解决云计算中多租户资源竞争导致的性能退化预测问题,其核心挑战在于黑盒环境下无法获取虚拟机内部状态,仅能依赖外部系统指标推断性能干扰。构建过程中面临多重挑战:需设计动态工作负载生成机制以模拟真实云环境波动性;需协调超200项异构指标的高频采集与同步,避免数据丢失;需解决多虚拟机并发运行时资源竞争行为的可重现性问题;此外,数据标注需依赖理想性能基线计算退化比率,对实验控制精度要求极高。
常用场景
经典使用场景
在云计算多租户环境中,CloudPerfTrace数据集被广泛应用于虚拟机性能退化预测研究。该数据集通过捕捉一秒分辨率的206个系统级指标,为建模瞬时资源竞争和动态负载变化提供了高精度数据基础。其典型使用场景包括分析CPU密集型、网络密集型及混合负载下虚拟机性能波动,为黑盒环境下的干扰模式识别提供关键支撑。
实际应用
在实际云平台运维中,CloudPerfTrace支持智能资源调度系统的开发,通过预测虚拟机性能退化实现动态资源分配。云服务提供商可基于该数据集构建预警机制,在检测到缓存竞争或内存带宽瓶颈时自动触发虚拟机迁移,从而保障服务质量并优化能源效率,特别适用于电商峰值流量或实时数据处理等关键场景。
衍生相关工作
该数据集催生了多项创新研究,包括基于双分支Transformer的CloudFormer架构及其变体。相关衍生工作扩展至多节点性能预测、在线自适应学习框架以及能效协同优化模型,例如将时序建模与系统级交互分析结合的新型神经网络,这些工作显著推动了云计算性能预测领域从分类检测向定量预测的范式转变。
以上内容由遇见数据集搜集并总结生成


