Teklia/RIMES-2011-line
收藏Hugging Face2024-03-14 更新2024-06-22 收录
下载链接:
https://hf-mirror.com/datasets/Teklia/RIMES-2011-line
下载链接
链接失效反馈官方服务:
资源简介:
RIMES-2011数据库(手写文档和传真的识别与索引)旨在评估手写文档和传真的自动识别和索引系统。该数据库通过邀请志愿者手写信件来收集数据,志愿者使用虚构身份并根据9个现实主题撰写信件。数据集包含12,723页手写文档,对应5,605封邮件,每封邮件包含2至3页。所有图像均调整为128像素的固定高度。数据集中的所有文档均为法语。
RIMES-2011数据库(手写文档和传真的识别与索引)旨在评估手写文档和传真的自动识别和索引系统。该数据库通过邀请志愿者手写信件来收集数据,志愿者使用虚构身份并根据9个现实主题撰写信件。数据集包含12,723页手写文档,对应5,605封邮件,每封邮件包含2至3页。所有图像均调整为128像素的固定高度。数据集中的所有文档均为法语。
提供机构:
Teklia
原始信息汇总
RIMES-2011 - line level 数据集概述
数据集描述
RIMES-2011 数据库(手写文档和传真的识别与索引)是为了评估手写信件的自动识别和索引系统而创建的。该数据库通过邀请志愿者书写手写信件以换取礼品券的方式收集。志愿者被赋予一个虚构的身份(与真实性别相同),并提供最多5个情景。每个情景从9个现实主题中选择:个人数据变更(地址、银行账户)、信息请求、账户开闭、合同或订单变更、服务质量投诉、支付困难(延期请求、免税...)、提醒、其他情况的投诉以及目标(行政机构或服务提供商(电话、电力、银行、保险))。志愿者用自己的话书写包含这些信息的信件。布局自由,唯一的要求是使用白纸和黑色墨水书写清晰。
该活动取得了成功,超过1,300人参与了RIMES数据库的创建,每人最多书写5封信件。最终的RIMES数据库包含12,723页,对应5605封两到三页的邮件。
注意,所有图像都被调整为固定高度128像素。
语言
数据集中的所有文档均为法语书写。
数据集结构
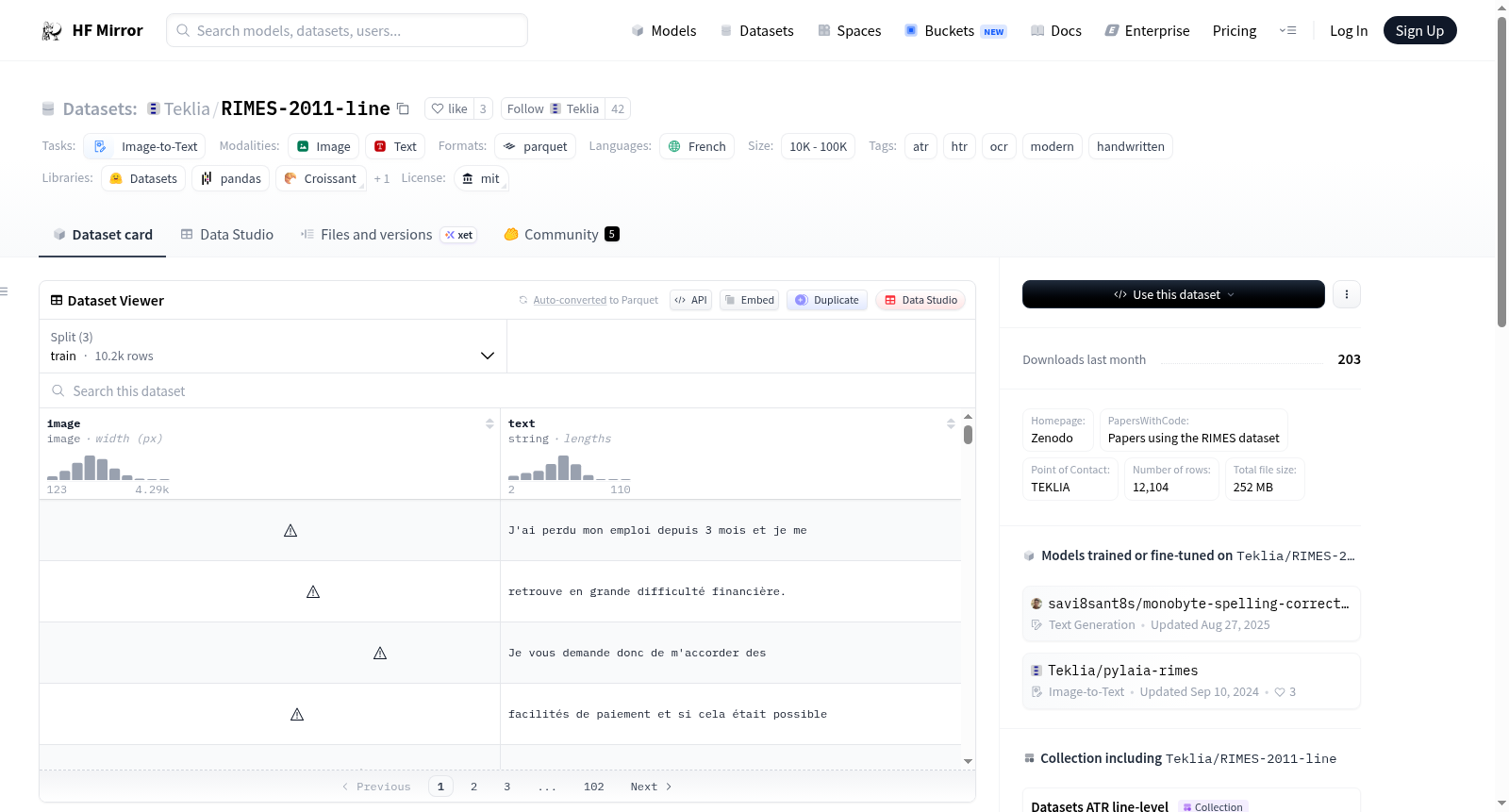
数据实例
json { image: <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=2560x128 at 0x1A800E8E190>, text: Comme indiqué dans les conditions particulières de mon contrat dassurance }
数据字段
image: 包含图像的PIL.Image.Image对象。注意,当访问图像列(使用dataset[0]["image"])时,图像文件会自动解码。解码大量图像文件可能需要较长时间。因此,建议先查询样本索引再访问“image”列,即dataset[0]["image"]应始终优先于dataset["image"][0]。text: 图像的标签转录。
搜集汇总
数据集介绍
构建方式
在文档分析与识别领域,RIMES-2011-line数据集通过精心设计的采集流程构建而成。研究团队邀请超过1300名志愿者,依据虚构身份与九类现实场景(如个人信息变更、投诉、支付困难等),以自由格式在白色纸张上用黑色墨水手写法文书信。每位参与者最多撰写五封信件,最终汇集了5605封邮件,总计12723页图像数据。所有图像均被统一调整为128像素的固定高度,确保了数据格式的一致性,为手写文本识别任务提供了扎实的基础。
使用方法
使用该数据集时,可通过HuggingFace数据集库直接加载,访问键包括'image'和'text'。'image'字段为PIL图像对象,自动解码;'text'字段为对应的转录文本。为优化处理效率,建议按索引优先查询图像列,即采用dataset[0]["image"]而非dataset["image"][0]的方式,以避免大规模图像解码时的性能瓶颈。数据集已划分为训练、验证和测试集,可直接用于模型训练、验证及性能测试,支撑手写文本识别领域的算法开发与评估。
背景与挑战
背景概述
手写文档识别作为模式识别领域的重要分支,其研究旨在将非结构化的手写信息转化为可编辑的数字化文本。RIMES-2011-line数据集由法国TEKLIA机构于2011年主导构建,核心目标是评估手写信件自动识别与索引系统的性能。该数据集通过大规模志愿者征集活动,模拟了九类现实场景下的法文手写信件撰写,共收录超过一万两千行图像-文本对,为手写文本识别研究提供了高真实性与多样性的基准数据,显著推动了离线手写识别技术的进展。
当前挑战
该数据集致力于解决手写文本识别中因个人书写风格、笔迹工整度及版面布局自由多变所导致的识别鲁棒性挑战。在构建过程中,研究团队面临了模拟真实信件场景的复杂性,需在保持内容自然性的同时控制变量;同时,数据采集依赖大量志愿者,在确保笔迹多样性与数据标注一致性之间需精细平衡。此外,原始图像尺寸不一,后续统一预处理为固定高度,虽便于模型输入,但也可能引入信息损失或形变,增加了识别算法的设计难度。
常用场景
经典使用场景
在文档分析与识别领域,RIMES-2011-line数据集作为手写法语文本识别的基准资源,其经典使用场景集中于手写文本行识别模型的训练与评估。该数据集通过提供大量真实手写信函的行级图像与对应转录文本,为研究者构建端到端的手写文本识别系统奠定了数据基础。模型通常利用卷积神经网络提取图像特征,再结合循环神经网络或Transformer架构进行序列建模,以准确预测每行手写体的文字内容。这一过程不仅验证了模型在复杂手写风格下的鲁棒性,也推动了手写识别技术向更高精度发展。
解决学术问题
该数据集有效解决了手写文本识别中因个人书写风格差异、版面布局自由及上下文语义依赖所带来的学术挑战。通过提供大规模、多样化的真实手写信函样本,它支持研究者探索如何提升模型对连笔、倾斜、字符粘连等复杂书写现象的泛化能力。其存在促进了对抗训练、注意力机制及多模态融合等方法的创新,显著降低了手写体识别的错误率,并为历史档案数字化、教育自动化等跨学科研究提供了可靠的数据支撑。
实际应用
在实际应用层面,RIMES-2011-line数据集直接服务于法语区的手写文档自动化处理需求。例如,在银行与保险行业,系统可自动识别客户手写申请或投诉信函,加速信息录入与分类流程;在文化遗产保护领域,该数据集训练的模型有助于数字化存档大量历史手稿与信件。此外,其技术可集成至移动应用,为用户提供实时手写笔记转文本功能,提升办公与教育场景的效率,展现了从学术研究到产业落地的无缝衔接。
数据集最近研究
最新研究方向
在文档分析与手写识别领域,RIMES-2011-line数据集作为法语手写文本识别的基准资源,持续推动着前沿技术的演进。当前研究聚焦于结合深度学习的端到端模型,特别是基于Transformer架构的视觉-语言模型,以提升对自由布局、多样化书写风格的法语手写文本的识别精度与鲁棒性。热点方向包括利用自监督预训练技术从有限标注数据中学习泛化特征,以及探索多模态融合方法,整合图像上下文与语言先验知识,以应对实际应用中常见的模糊、倾斜或噪声干扰。这些进展不仅促进了历史档案数字化与自动化办公系统的发展,也为跨语言手写识别研究提供了重要参照,具有显著的学术与实用价值。
以上内容由遇见数据集搜集并总结生成


