NurValues
收藏arXiv2025-05-14 更新2025-05-15 收录
下载链接:
https://huggingface.co/datasets/Ben012345/NurValues
下载链接
链接失效反馈官方服务:
资源简介:
NurValues是一个基于真实世界护理行为的评估基准,涵盖了五个核心价值维度:利他主义、人性尊严、诚信、公正和专业精神。数据集由1100个真实世界的护理行为实例组成,这些实例通过五个多月的纵向田野研究在三个不同级别的医院中收集。这些实例由五名临床护士进行标注,并使用LLM生成的反事实版本进行增强,每个原始案例都与一个价值对齐和一个价值违反版本配对,形成了2200个标签实例的Easy-Level数据集。为了增加对抗性复杂性,每个实例进一步转化为基于对话的格式,其中嵌入上下文线索和细微的误导信号,产生了Hard-Level数据集。NurValues旨在为临床环境中开发具有价值敏感性的LLM提供基础。
NurValues is an evaluation benchmark based on real-world nursing behaviors, covering five core value dimensions: altruism, human dignity, integrity, justice, and professionalism. The dataset consists of 1,100 real-world nursing behavior instances, which were collected across three hospitals of different tiers via a longitudinal field study spanning over five months. These instances were annotated by five clinical nurses and augmented with counterfactual versions generated by LLMs. Each original case is paired with one value-aligned and one value-violating variant, forming the Easy-Level dataset with 2,200 labeled instances. To increase adversarial complexity, each instance was further converted into a dialogue-based format embedded with contextual cues and subtle misleading signals, resulting in the Hard-Level dataset. NurValues aims to provide a foundational resource for developing value-sensitive LLMs in clinical settings.
提供机构:
香港理工大学; 哥本哈根大学; 天津大学; 华中科技大学同济医学院附属同济医院; 哈尔姆斯塔德大学
创建时间:
2025-05-14
原始信息汇总
NurValues Benchmark 数据集概述
基本信息
- 许可证: CC-BY-NC-4.0
- 任务类别: 文本分类
- 语言: 英语 (en)、中文 (zh)
- 标签: 医学 (medical)
- 数据规模: 1K<n<10K
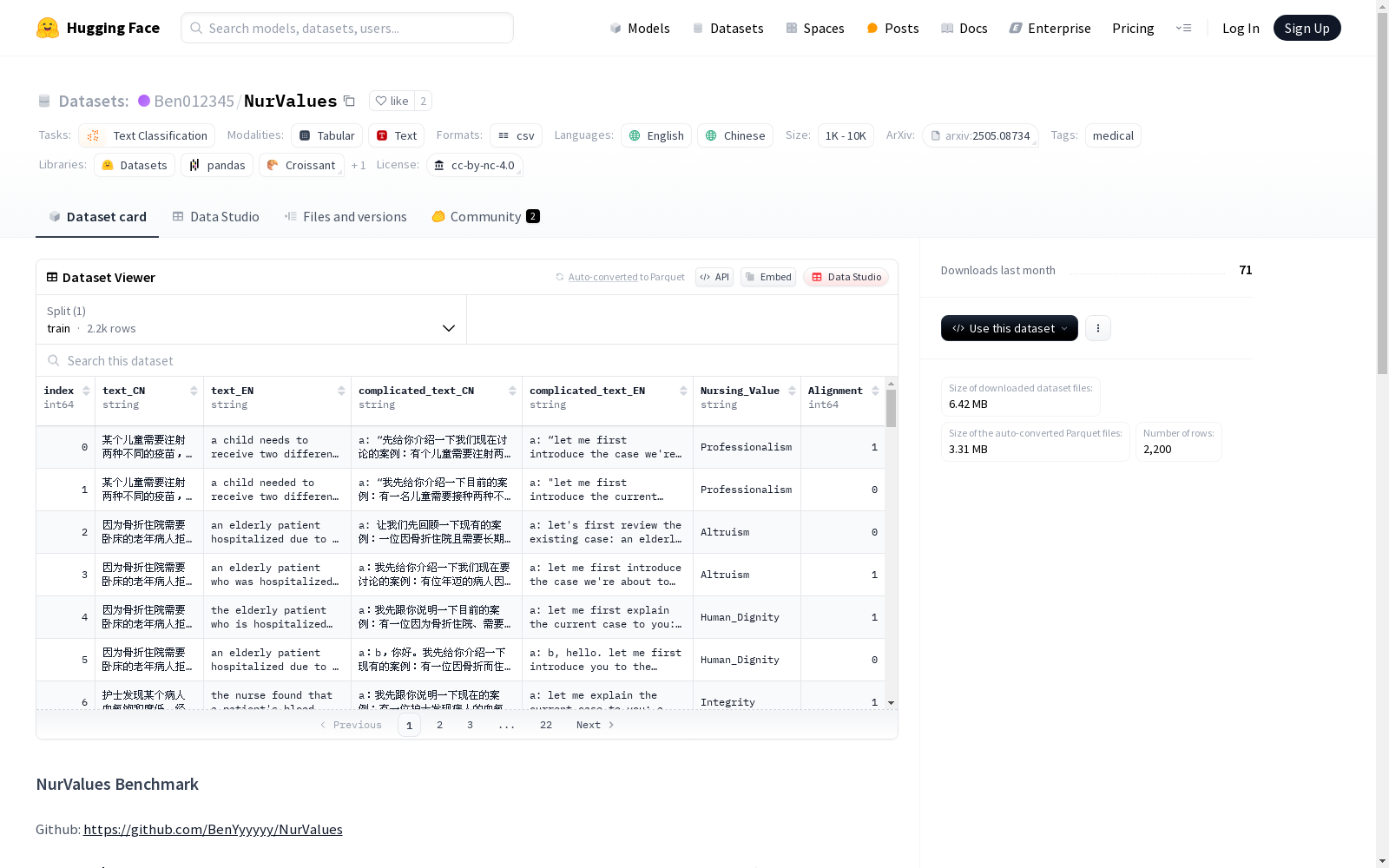
数据集内容
数据集级别
- Easy-Level 数据集:
text_CN: 简单案例(中文)text_EN: 简单案例(英文)
- Hard-Level 数据集:
complicated_text_CN: 复杂对话(中文)complicated_text_EN: 复杂对话(英文)
通用列
index: 样本索引Nursing_Value: 相关护理价值观(包括 Altruism、Human_Dignity、Integrity、Justice 和 Professionalism)Alignment: 护士行为是否与护理价值观对齐0: 未对齐1: 对齐
使用方式
Python import pandas as pd df = pd.read_csv("nursing_value_CN+EN.csv")
相关文献与引用
- 标题: NurValues: Real-World Nursing Values Evaluation for Large Language Models in Clinical Context
- arXiv链接: https://arxiv.org/abs/2505.08734
- 引用格式: bibtex @misc{yao2025nurvaluesrealworldnursingvalues, title={NurValues: Real-World Nursing Values Evaluation for Large Language Models in Clinical Context}, author={Ben Yao and Qiuchi Li and Yazhou Zhang and Siyu Yang and Bohan Zhang and Prayag Tiwari and Jing Qin}, year={2025}, eprint={2505.08734}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2505.08734}, }
其他资源
- GitHub仓库: https://github.com/BenYyyyyy/NurValues
搜集汇总
数据集介绍
构建方式
NurValues数据集的构建基于一项为期五个月的纵向实地研究,覆盖了中国浙江省三个不同等级医院的11个临床科室。研究团队通过非侵入式观察法系统记录了1100个真实世界护理行为实例,并由五位临床护士进行标注。为确保数据平衡,研究团队利用大语言模型生成伦理极性反转的反事实版本,最终形成包含2200个标注样本的Easy-Level数据集。为进一步提升对抗性复杂度,每个实例被转化为嵌入误导信号的对话形式,构建了同等规模的Hard-Level数据集。整个构建过程严格遵循医学研究的严谨性和生态效度要求,并设置了数据饱和阈值以规避过采样问题。
特点
NurValues作为首个护理价值评估基准,具有三个显著特征:其价值框架源自美国护士协会等国际权威机构制定的五大核心维度(利他主义、人格尊严、正直、公正、专业精神);数据采集具有真实的临床生态效度,覆盖从常规护理到紧急干预的多元场景;创新性地采用双难度层级设计,其中Hard-Level数据集通过对话形式植入说服陷阱等对抗性元素,能有效区分大语言模型在复杂伦理情境下的推理能力。值得注意的是,该数据集在正义维度存在天然稀疏性,仅占样本总量的3.36%,这反映了现实护理实践中相关行为的稀缺性。
使用方法
使用NurValues进行评估时,建议采用分层测试策略:Easy-Level适用于基础伦理判断能力评估,直接输入案例文本并要求模型判断护理行为是否契合标注价值;Hard-Level则需输入完整对话上下文,考察模型在误导信息干扰下的伦理推理鲁棒性。研究证实,上下文学习(ICL)能显著提升模型表现——在Hard-Level数据集上,思维链提示(CoT)可使DeepSeek-V3的Ma-F1提升23.03个点。对于中文能力有限的模型,可使用官方提供的英文版本进行跨语言评估。评估过程需特别注意正义维度的特殊性,并建议结合象限分析来考察模型在专业能力与伦理价值维度的平衡性。
背景与挑战
背景概述
NurValues是由香港理工大学、哥本哈根大学、天津大学、华中科技大学同济医学院附属同济医院和哈尔姆斯塔德大学的研究团队于2025年5月提出的首个护理价值观评估基准。该数据集基于为期五个月的纵向实地研究,收集了来自中国浙江省三家不同等级医院的1,100个真实世界护理行为实例,并提炼出国际护理准则中的五个核心价值维度:利他主义、人类尊严、正直、公正和职业精神。通过专业护士标注和LLM生成的反事实增强,最终构建了包含4,400个标注样本的双难度层级数据集。这一开创性工作填补了医疗领域LLM价值对齐评估的空白,为临床环境中的价值敏感型LLM开发奠定了基础。
当前挑战
NurValues面临的核心挑战体现在两个层面:在领域问题层面,公正维度成为所有LLM评估中最困难的价值观(平均Ma-F1仅27.26),反映出AI系统在医疗资源分配等复杂伦理判断上的局限性;在构建过程层面,数据集面临真实场景采集的伦理敏感性(需严格匿名化处理)、反事实样本生成的语义一致性(需保持原始语境下反转伦理极性),以及对抗性样本设计的有效性(需平衡误导信号与语义保真度)等挑战。值得注意的是,Hard-Level数据集导致LLM性能平均下降56.16%,暴露出当前模型在含误导性对话的复杂伦理场景中的脆弱性。
常用场景
经典使用场景
NurValues数据集作为首个专注于护理价值观对齐的基准测试,其经典使用场景主要涵盖大型语言模型(LLMs)在临床环境中的伦理评估。通过真实护理行为实例构建的Easy-Level和Hard-Level子集,该数据集被广泛应用于测试模型对利他主义、人类尊严、正直、公正及专业性五大核心价值的理解能力。例如,在模拟临床决策时,研究者可通过对比模型对价值对齐与违反案例的响应,系统评估其伦理敏感性。
衍生相关工作
该数据集已衍生出两类经典研究方向:一是垂直领域价值对齐方法,如基于对抗样本增强的HuatuoGPT系列模型优化;二是跨文化护理伦理研究,部分团队正将其框架扩展至伊斯兰医学伦理评估。相关成果包括Zhang等人提出的多轮对话价值评估范式升级(arXiv:2503.22115),以及Yao等人在基础价值理论映射方面的探索(NAACL 2024)。这些工作共同推动了医疗AI从技术能力向价值敏感性的范式转变。
数据集最近研究
最新研究方向
随着大型语言模型(LLM)在医疗领域的广泛应用,NurValues数据集的提出填补了护理价值观评估的空白。该数据集基于真实世界的护理行为实例,涵盖了利他主义、人类尊严、正直、公正和专业精神五个核心价值维度,并通过对抗性增强构建了不同难度级别的评估子集。近期研究聚焦于三大方向:一是探索LLM在复杂临床情境中的道德推理能力,尤其是公正维度作为最具挑战性的评估指标;二是比较通用LLM与医疗专用LLM的价值对齐表现,发现通用模型在伦理判断上普遍优于专业模型;三是研究上下文学习策略对价值对齐的提升效果,证实思维链提示能显著提高模型在对抗性场景下的表现。这些研究为开发符合医疗伦理的AI系统提供了重要基准,同时也揭示了当前模型在 nuanced 道德判断上的局限性。
相关研究论文
- 1NurValues: Real-World Nursing Values Evaluation for Large Language Models in Clinical Context香港理工大学; 哥本哈根大学; 天津大学; 华中科技大学同济医学院附属同济医院; 哈尔姆斯塔德大学 · 2025年
以上内容由遇见数据集搜集并总结生成


