BDLawCorpus-Dataset-V1
收藏Hugging Face2026-05-08 更新2026-05-09 收录
下载链接:
https://huggingface.co/datasets/millat/BDLawCorpus-Dataset-V1
下载链接
链接失效反馈官方服务:
资源简介:
BDLawCorpus-1 安全指令与 RAG 数据集是首个针对孟加拉国法律的综合性、抗幻觉且经过指令调优的数据集,旨在训练法律 AI 助手。该数据集将复杂的法律条文翻译为易于理解的孟加拉语(সহজ বাংলা),并嵌入了严格的安全防护措施。数据集包含四个部分:1) `rag_passages.jsonl`(15.4k+ 段落),用于语义搜索/向量数据库;2) `finetune.jsonl`(4.7k+ 对),用于训练 LLMs 成为“法律顾问”;3) `qa_pairs.jsonl`,包含问题-答案对;4) `metadata.csv`,提供元数据框架以防止提供过时的建议。数据集适用于检索增强生成(RAG)和指令微调(LoRA/QLoRA),并已通过实证质量评估,确保其定量、安全和结构维度的有效性。
创建时间:
2026-05-08
原始信息汇总
数据集概述
数据集名称:BDLawCorpus-1 Safe Instruction & RAG Dataset
数据集地址:https://huggingface.co/datasets/millat/BDLawCorpus-Dataset-V1
许可证:MIT
任务类别:问答、文本生成、特征提取
语言:孟加拉语(bn)、英语(en)
标签:法律、孟加拉国、法律、指令微调、RAG、法律顾问
数据规模:10K < n < 100K
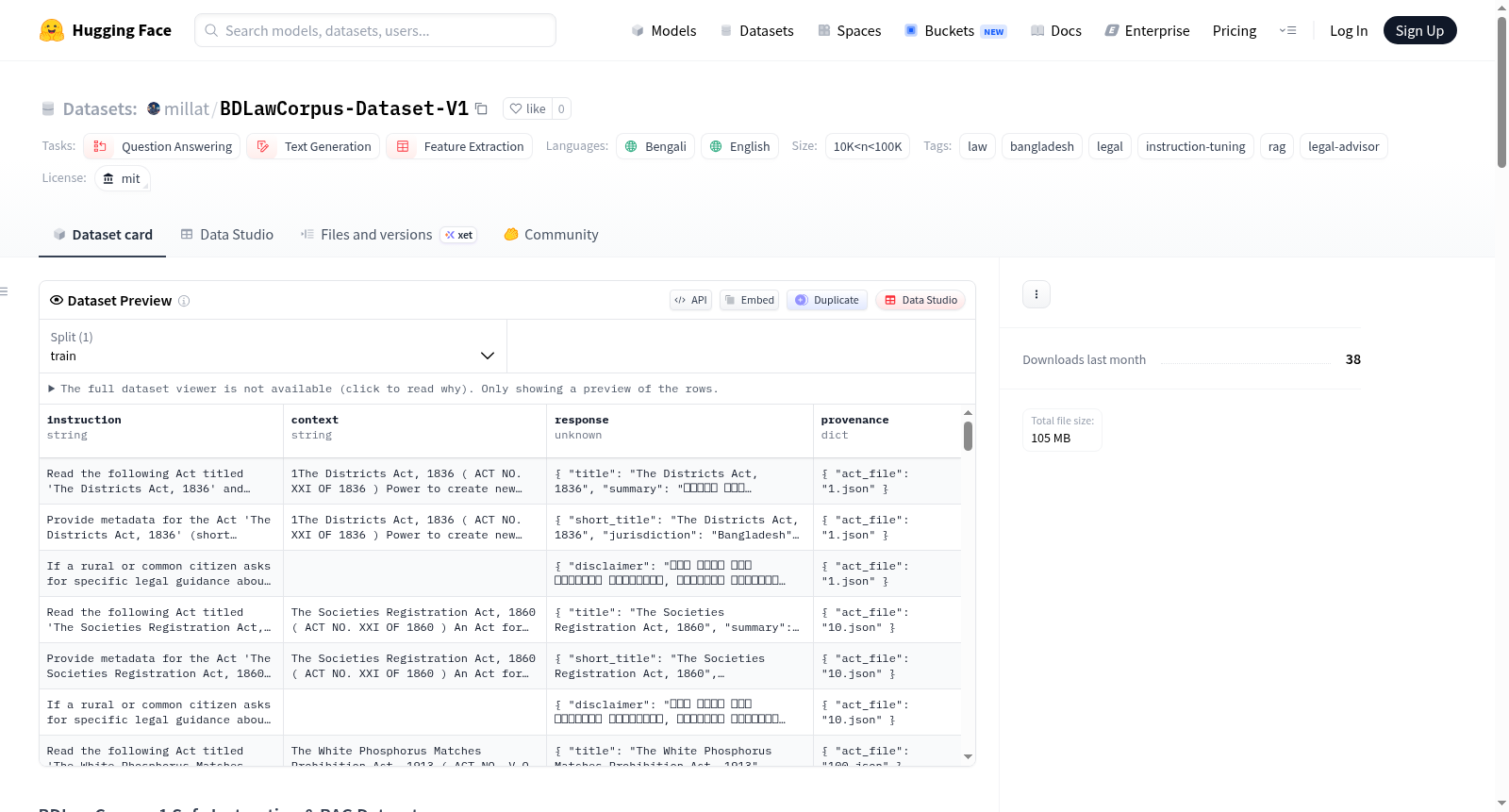
数据集构成
该数据集包含四个独立部分,适用于RAG流水线和模型微调(LoRA):
- rag_passages.jsonl:包含15,400多个分块,涵盖1,570部孟加拉国现行及历史法案的语义分块,适用于语义搜索和向量数据库。
- finetune.jsonl:包含4,700多个指令-上下文-响应对,用于将大语言模型训练为“法律顾问”角色,每条响应均包含强制免责声明。
- qa_pairs.jsonl:包含问答分块,映射至法案目的,并包含“对抗性拒绝”训练样本,引导模型在缺乏上下文时拒绝回答。
- metadata.csv:包含元数据框架,记录“提及修正”、“已废除”及“被替代”规则,防止RAG系统提供过时建议。
数据集结构示例
-
RAG分块:
- 包含ID、标题、法案文件名、文本起始/结束位置及文本内容。
- 示例字段:
id、title、act_file、start、end、text
-
微调对:
- 包含指令(instruction)、原始法律文本(context)、结构化AI响应(response)及溯源信息(provenance)。
- 示例字段:
instruction、context、response(含disclaimer、info、next_steps)、provenance
数据集用途
- 为孟加拉国法律AI应用提供安全、结构完整且语言易用的基础。
- 限制AI作为咨询实体而非权威法院,通过内置免责声明和特定拒绝训练降低法律幻觉风险。
使用方法
可通过Hugging Face datasets 库加载数据:
-
加载RAG分块: python rag_dataset = load_dataset("millat/BDLawCorpus-Dataset-V1", data_files="rag_passages.jsonl")
-
加载微调对: python finetune_dataset = load_dataset("millat/BDLawCorpus-Dataset-V1", data_files="finetune.jsonl")
用例1:RAG:将 rag_dataset 输入多语言嵌入模型,存储向量至ChromaDB、Pinecone或FAISS。
用例2:指令微调:使用 finetune_dataset 结合Unsloth或Hugging Face TRL框架微调基础模型(如Llama-3-8B、Qwen-2.5)。
相关资源
- 代码库与方法论:完整开源,详见 GitHub 仓库:https://github.com/codermillat/BDLawCorpus
数据质量评估
-
量化统计:
- RAG分块总数:15,428个
- RAG分块平均长度:2,581.55字符,最大长度:10,934字符
- 微调场景数:4,710对
- 指令响应平均长度:260.95字符
-
对齐与安全防护:
- 免责声明注入率:33.33%(1,570条微调对)
- 对抗性拒绝嵌入率:33.33%(1,570条微调对)
-
结构完整性与溯源:
- 数据污染(HTML/JS痕迹):0%(完美清洗)
- RAG溯源链接率:100%
- 微调对溯源链接率:100%
搜集汇总
数据集介绍
构建方式
BDLawCorpus-Dataset-V1是孟加拉国首个综合性法律AI指令与检索增强生成数据集。其构建过程始于对孟加拉国全部1570部现行及历史法律文本的系统性爬取,随后通过去重、清洗及基于语言模型的token感知分块技术,将原始法律条文切割为15428个语义连贯且结构完整的文本段落。在此基础上,研究团队精心设计了4710组指令-上下文-响应对,用于微调大型语言模型,使其扮演“法律顾问”角色。该数据集还融合了对抗性拒绝样本,以抑制模型在没有充分上下文时生成幻觉性回答。同时,通过结构化元数据框架(包括修法记录、废止标识及替代法律索引)确保信息时效性与溯源完整性。所有数据均以JSONL和CSV格式存储,便于直接集成至向量数据库及微调流程。
特点
该数据集的核心特色在于其多维度的安全性与可靠性设计。一方面,数据集强制嵌入约33.33%的免责声明样本,确保AI模型在提供法律信息时明确其辅助性而非权威性地位,从而规避法律风险。另一方面,同等比例的对抗性拒绝样本被注入微调数据中,使模型在面临超出知识范围的询问时能够坦然承认自身局限,而非生成虚构内容。此外,数据集实现了100%的溯源可追溯性——每个RAG段落与微调样本均携带有精确的法律来源映射文件标识,确保输出可被验证。在结构层面,数据分块经过优化设计与去污染处理,HTML或脚本残留率为0%,保证数据纯净度与上下文窗口兼容性。
使用方法
使用该数据集主要涵盖两大应用场景。对于检索增强生成(RAG)任务,用户可通过Hugging Face的datasets库直接加载rag_passages.jsonl文件,并将文本块输入至多语言嵌入模型(如sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2)生成向量,随后存储于ChromaDB、Pinecone或FAISS等向量数据库,以支持基于语义搜索的法律条文检索。对于指令微调任务,研究者可加载finetune.jsonl文件,利用Unsloth或Hugging Face TRL等框架对Llama-3、Qwen等基础模型进行低秩适配(LoRA/QLoRA)训练;数据中的instruction、context及response字段已预先结构化,可直接用于监督式微调。该数据集同时提供了完整的开源处理代码库,用户可参考GitHub仓库实现自定义扩展。
背景与挑战
背景概述
BDLawCorpus-Dataset-V1是首个专为孟加拉国法律体系设计的综合性大型语言模型指令微调与检索增强生成(RAG)数据集,由研究人员millat主导开发并开源发布于GitHub。该数据集创建于2024年,旨在填补孟加拉语法律人工智能领域的空白,将复杂的法律条文转化为通俗易懂的孟加拉语表述,并嵌入严格的安全机制,以服务于当地农村及普通民众的法律咨询需求。通过涵盖1570部现行与历史法案的15428个语义分块和4710组指令-回复对,该数据集为自研模型BDLaw-Instruct的训练奠定了基础,对推动孟加拉国乃至南亚区域的法律科技发展具有深远影响。
当前挑战
该数据集旨在解决多重挑战。首先,在法律AI领域,核心问题是防止模型在缺乏上下文时产生“法律幻觉”并给出错误建议,同时确保模型能主动承认自身知识局限。为此,数据集通过嵌入强制性免责声明和对抗性拒绝样本,强制模型扮演咨询顾问而非权威法官的角色。其次,在构建过程中,研究者面临挑战:需对众多法案进行语义分块以适配RAG流水线,并保证每个片段可溯源至原始法案;还需处理法案之间的修订、废止与替代关系,避免向用户提供过时信息。此外,数据污染(如HTML痕迹)的彻底清除是保障语料质量的关键技术难题。
常用场景
经典使用场景
在法律人工智能领域,BDLawCorpus-Dataset-V1最经典的用途在于构建针对孟加拉国法律的检索增强生成(RAG)系统与指令微调(Instruction Tuning)管道。该数据集将1570部现行及历史法案精细切分为15428个语义块,每个语块均携带完整溯源元数据,可直接注入多语言嵌入模型(如paraphrase-multilingual-MiniLM-L12-v2)以生成向量索引,并存储于ChromaDB或FAISS等向量数据库。与此同时,4710组指令-上下文-响应对为大型语言模型(如Llama-3、Qwen)提供了结构化训练材料,使得模型能够以“法律顾问(লিগ্যাল এডভাইজার)”角色进行安全应答。这种双轨架构——RAG管道保证实时检索的准确性,指令微调塑造稳健的对话风格——共同构筑了从法条到自然人可理解建议的完整桥梁。
实际应用
在实际落地层面,BDLawCorpus-Dataset-V1已展现出明确的部署价值。孟加拉国农村地区的普通公民可通过搭载该数据集的法治聊天机器人,以孟加拉语(সহজ বাংলা)提出关于土地纠纷、婚姻继承或行政处罚等日常法律问题;系统利用RAG管道实时检索最相关法案段落,并由经过指令微调的模型以浅显直白的语言给出解释性建议,同时附上前往当地法律诊所或司法援助(Legal Aid)机构的行动指引。此外,法律从业者可将数据集整合至内部知识管理平台,用于快速审阅法案修订历史、评估新规对原有条款的替代效力(replaced_by字段),从而提升案件研判效率。这一应用场景直接回应了孟加拉国法律资源分布不均的现实困境,使得非专业人士也能在可控风险内获得初步法律导航。
衍生相关工作
此数据集已催生一系列具有前瞻性的衍生工作。其姊妹项目BDLaw-Instruct模型正在训练中,旨在通过LoRA/QLoRA微调策略,进一步优化模型在农村网络环境下的响应速度与多轮对话能力。开源社区基于该数据集构建了首个孟加拉语法律语义搜索基准(Legal Semantic Search Benchmark),验证了跨语言嵌入模型在极端低资源场景下的检索截止点(Recall@K)。此外,研究者正利用数据集中配备的对抗性拒绝样本集合,探索‘拒绝训练’(Refusal Training)对模型公平性(Fairness)与过度拒答(Over-refusal)之间的平衡策略。这些工作共同拓展了数据集的影响力边界——它不仅是静态的语料库,更是激发‘安全对齐-可解释检索-社区参与’三位一体创新方法的孵化器。
以上内容由遇见数据集搜集并总结生成


