mhan/Shot2Story-134K
收藏Hugging Face2024-04-24 更新2024-05-25 收录
下载链接:
https://hf-mirror.com/datasets/mhan/Shot2Story-134K
下载链接
链接失效反馈官方服务:
资源简介:
Shot2Story数据集是一个用于多镜头视频理解的新基准,包含134k个视频的详细长摘要(人类注释+GPTV生成)和188k个视频镜头的镜头字幕(人类注释)。数据集分为多镜头和单镜头配置,每个配置包含不同的训练、测试和验证集。数据集的注释格式为JSON,每个视频作为一个JSON对象,包含视频文件名、唯一视频ID、视频摘要、全视频ASR、视频镜头名称数组、每个镜头的旁白字幕数组、每个镜头的视频字幕数组和每个镜头的ASR输出数组。数据集不提供原始视频,但提供了访问信息和下载脚本。数据集的文本注释遵循CC BY-NC-SA 4.0许可证,仅用于非商业研究。
Shot2Story数据集是一个用于多镜头视频理解的新基准,包含134k个视频的详细长摘要(人类注释+GPTV生成)和188k个视频镜头的镜头字幕(人类注释)。数据集分为多镜头和单镜头配置,每个配置包含不同的训练、测试和验证集。数据集的注释格式为JSON,每个视频作为一个JSON对象,包含视频文件名、唯一视频ID、视频摘要、全视频ASR、视频镜头名称数组、每个镜头的旁白字幕数组、每个镜头的视频字幕数组和每个镜头的ASR输出数组。数据集不提供原始视频,但提供了访问信息和下载脚本。数据集的文本注释遵循CC BY-NC-SA 4.0许可证,仅用于非商业研究。
提供机构:
mhan
原始信息汇总
数据集概述
数据集名称
- 名称: Shot2Story
数据集内容
- 类型: 视频-文本数据集
- 规模: 包含134k视频数据
- 详细内容:
- 提供134k视频的详细长摘要(人类标注+GPTV生成)
- 提供188k视频镜头的镜头描述(人类标注)
数据集配置
- 多重射击配置 (multi-shot)
- 数据文件:
- 43k_human_train.json
- 90k_gptv_train.json
- 134k_full_train.json
- 20k_test.json
- 20k_val.json
- 数据文件:
- 单次射击配置 (single-shot)
- 数据文件:
- 43k_human_shot_train.json
- 20k_human_shot_test.json
- 20k_human_shot_val.json
- 数据文件:
数据集任务类别
- 总结
- 视觉问答
- 问答
数据集语言
- 英语
数据集规模类别
- 100K<n<1M
数据集许可证
- 许可证: Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0)
- 使用限制: 仅限非商业研究使用
数据集联系信息
- 联系人: Mingfei Han
- 联系方式: hmf282@gmail.com
数据集引用信息
-
论文: 2312.10300
-
引用格式:
@misc{han2023shot2story20k, title={Shot2Story20K: A New Benchmark for Comprehensive Understanding of Multi-shot Videos}, author={Mingfei Han and Linjie Yang and Xiaojun Chang and Heng Wang}, year={2023}, eprint={2312.10300}, archivePrefix={arXiv}, primaryClass={cs.CV} }
搜集汇总
数据集介绍
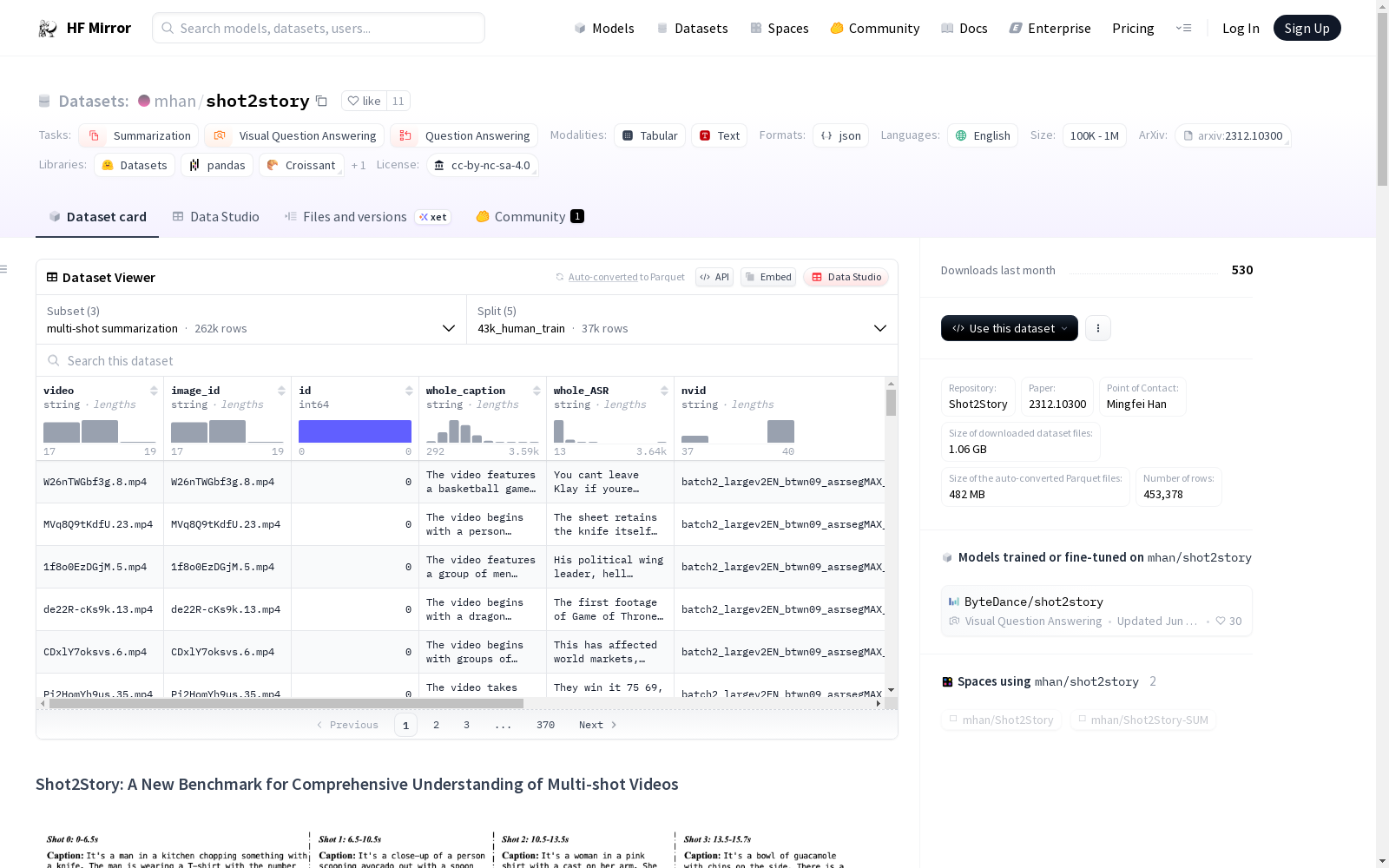
构建方式
mhan/Shot2Story-134K数据集的构建,是基于多镜头视频的理解任务,涵盖了详细的长篇总结(包括人工注释和GPTV生成的文本)以及针对188k视频镜头的人工注释视频字幕和旁白字幕。数据集由43k人工注释的训练集、90k由GPTV生成的训练集、以及包含548k视频镜头的134k完整训练集构成,同时还包括了针对测试和验证视频的手工注释的多镜头问答对。
特点
该数据集的特点在于其规模宏大,包含了134k多镜头视频的详细文本描述,以及超过548k的视频镜头。它不仅提供了人工注释的总结,还包含了由GPTV生成的文本总结,为研究多镜头视频理解提供了全面的数据支持。此外,数据集还提供了针对测试和验证视频的多镜头问答对,有助于评估模型在多镜头视频理解方面的性能。
使用方法
使用mhan/Shot2Story-134K数据集时,用户需先从OneDrive或HuggingFace下载多镜头视频。数据集的注释以JSON格式存储,每个视频对象都包含了视频文件名、唯一视频ID、视频总结、全视频ASR输出、视频镜头名称、每个镜头的旁白字幕和视频字幕等信息。用户可以使用提供的Python脚本下载视频,并使用处理脚本准备视频片段和单镜头视频。在使用数据集时,需遵守Creative Commons Attribution-NonCommercial-ShareAlike 4.0国际许可协议,仅限非商业研究用途。
背景与挑战
背景概述
在深入理解多镜头视频的领域中,Shot2Story-134K数据集应运而生,由字节跳动团队于2023年推出。该数据集旨在促进对多镜头视频的综合理解,涵盖视频摘要、视觉问答和问答等任务。核心研究人员包括Mingfei Han等,数据集的创建不仅丰富了相关领域的研究资源,也为多镜头视频的理解与生成提供了新的视角和挑战。其影响力迅速在学术界扩散,成为推动该领域发展的关键力量。
当前挑战
数据集在构建过程中面临的挑战主要包括:一是如何高效地生成和校对大量视频摘要,二是确保多镜头视频的标注质量,三是处理视频和文本之间的复杂关联。此外,数据集在解决多镜头视频理解问题的挑战上,如视频内容的时间关联性、视觉与语言的融合、以及视频摘要的多样性和准确性,均为当前研究的热点和难点。
常用场景
经典使用场景
在深入理解多镜头视频的领域,mhan/Shot2Story-134K数据集提供了一个全新的基准,其经典使用场景在于,研究者能够利用该数据集中的详尽文本描述,对多镜头视频进行综合性的理解和分析。这些描述包括人类注释和GPTV生成的长篇摘要,以及针对视频镜头的人类注释标题和旁白标题,从而促进了对视频内容的深层次解读和总结。
衍生相关工作
基于mhan/Shot2Story-134K数据集的研究已经衍生出一系列相关工作,包括对多镜头视频理解模型的评估和比较,以及探索视频内容与文本描述之间更深层次关联的研究,这些工作进一步推动了多模态学习和视频理解领域的发展。
数据集最近研究
最新研究方向
在多镜头视频理解领域,mhan/Shot2Story-134K数据集的发布标志着对视频内容深层次、综合性的解读能力的研究迈出了新的一步。该数据集通过提供详尽的视频文本描述,促进了多镜头视频的总结、视觉问答以及问答等任务的研究。近期研究利用该数据集,致力于提升模型对视频时序、整体理解及音频相关方面的洞察能力,为智能视频内容分析领域带来了新的研究热点,对于推动相关技术的发展具有重要的理论与实际意义。
以上内容由遇见数据集搜集并总结生成


