OrionBench
收藏github2025-05-28 更新2025-05-31 收录
下载链接:
https://github.com/OrionBench/OrionBench
下载链接
链接失效反馈官方服务:
资源简介:
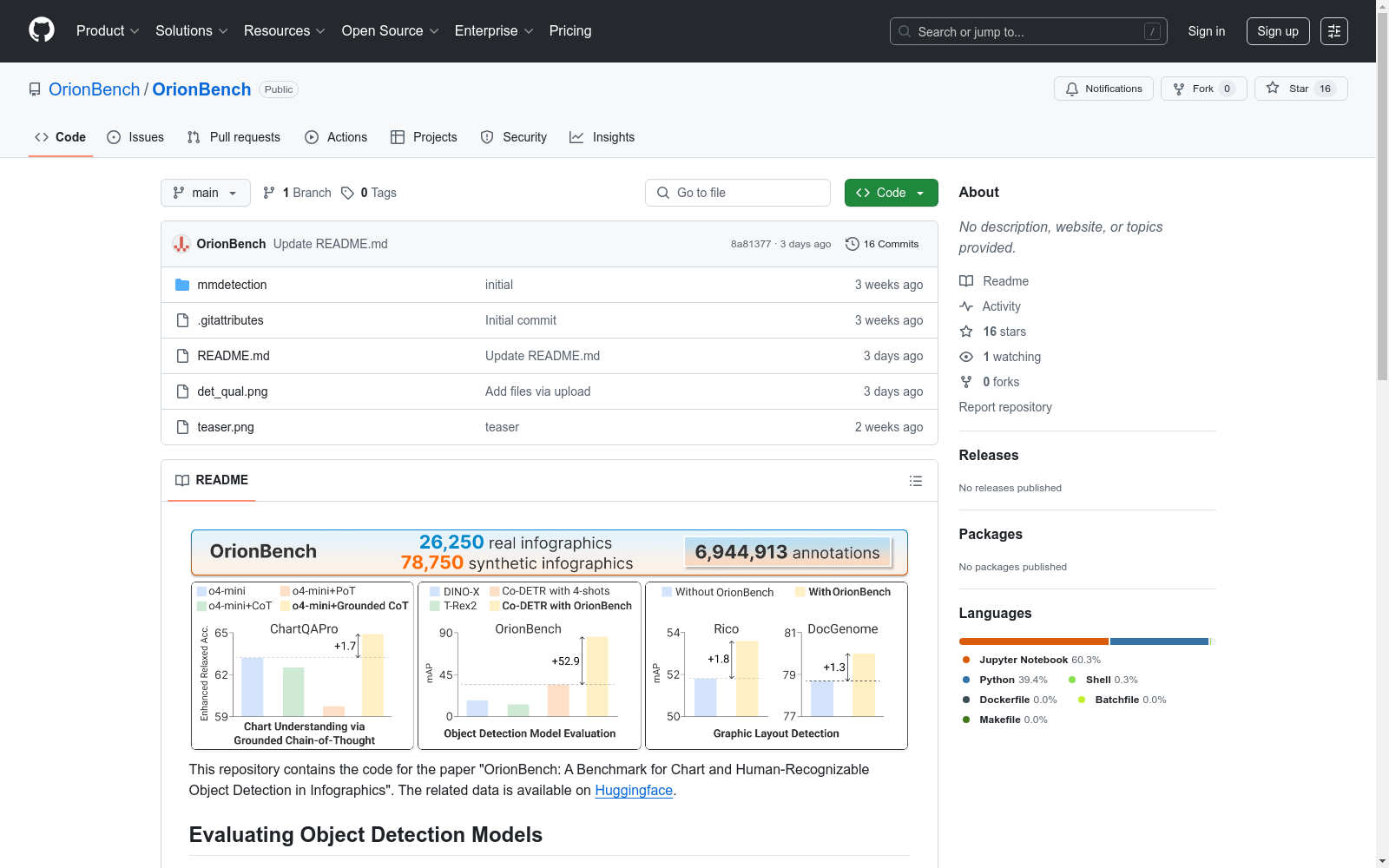
OrionBench是一个用于信息图中图表和人类可识别对象检测的基准数据集。
OrionBench serves as a benchmark dataset for information graphic chart and human-recognizable object detection.
创建时间:
2025-05-13
原始信息汇总
OrionBench数据集概述
数据集基本信息
- 名称:OrionBench
- 用途:用于图表和人类可识别对象(HRO)检测的基准测试
- 相关论文:"OrionBench: A Benchmark for Chart and Human-Recognizable Object Detection in Infographics"
- 数据获取:https://huggingface.co/datasets/OrionBench/OrionBench
评估模型
- 支持评估的四种对象检测模型:
- Faster-Rcnn
- YOLOv3
- RTMDet
- Co-DETR
模型训练
- 训练环境:基于MMDetection框架
- 训练命令示例: bash bash tools/dist_train.sh configs/faster_rcnn/faster-rcnn_my_full.py 8 --cfg-options data.samples_per_gpu=1 optimizer_config.cumulative_iters=8 optimizer_config.type="GradientCumulativeOptimizerHook" --work-dir work_dir/faster-rcnn_my_full
预训练模型
- InternImage-based模型:https://huggingface.co/OrionBench/InternImage_L_DINO
引用信息
bibtex @misc{zhu2025orionbench, title={OrionBench: A Benchmark for Chart and Human-Recognizable Object Detection in Infographics}, author={Jiangning Zhu and Yuxing Zhou and Zheng Wang and Juntao Yao and Yima Gu and Yuhui Yuan and Shixia Liu}, year={2025}, eprint={2505.17473}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2505.17473}, }
搜集汇总
数据集介绍
构建方式
在信息可视化领域,OrionBench数据集的构建采用了系统化的标注流程,专注于图表和人类可识别对象(HRO)的检测任务。研究团队通过收集多样化的信息图表,采用专业标注工具对图表元素和HRO进行边界框标注,确保标注质量的一致性。数据集构建过程中特别考虑了类别平衡和场景多样性,涵盖了常见的图表类型和各类HRO,为模型评估提供了全面的基准。
使用方法
使用OrionBench数据集需要先配置MMDetection环境,研究者可根据提供的配置文件快速复现基准测试结果。数据集支持多种使用方式,包括零样本提示学习、小样本微调以及完整训练。通过修改配置文件中的路径参数,用户可以灵活地将数据集应用于不同的检测模型。数据集还提供了InternImage等预训练模型,便于研究者进行迁移学习和性能比较。
背景与挑战
背景概述
OrionBench数据集由Jiangning Zhu等研究人员于2025年提出,旨在为信息图表中的图表和人类可识别对象(HROs)检测任务提供标准化评估基准。该数据集由多所知名机构联合开发,包括清华大学等高校的研究团队,其核心研究问题聚焦于解决信息图表中复杂视觉元素的自动化识别难题。作为计算机视觉领域的前沿探索,OrionBench通过融合图表检测与通用物体检测的双重特性,显著推动了多媒体内容理解与文档分析交叉领域的发展,为后续研究提供了重要的数据基础和方法论参考。
当前挑战
该数据集面临的领域挑战主要体现在信息图表特有的视觉复杂性上:多尺度图表元素与自然物体的混合分布导致传统检测模型难以平衡局部特征与全局语义的捕捉;密集文本与装饰性图案形成的背景干扰显著提高了误检率。在构建过程中,研究团队需克服标注一致性问题,由于信息图表中图表类型与HROs的形态多样性,需设计兼顾精确边界框标注与语义类别描述的标注规范。此外,数据分布的均衡性也是关键挑战,需确保不同图表类型及HROs类别在训练集和测试集中的合理配比以避免模型偏见。
常用场景
经典使用场景
在信息图表分析领域,OrionBench数据集为研究者提供了一个标准化的评估平台,专门用于测试和比较不同目标检测模型在识别图表和人类可识别对象(HROs)方面的性能。通过该数据集,研究者能够系统地评估模型在复杂信息图表中的检测能力,为后续的模型优化和算法改进提供可靠依据。
解决学术问题
OrionBench数据集解决了信息图表中目标检测的学术难题,尤其是在多类别对象识别和复杂背景干扰下的检测精度问题。该数据集通过提供丰富的标注数据,帮助研究者深入理解模型在图表和HROs检测中的局限性,推动了目标检测算法在特定场景下的性能提升。
实际应用
在实际应用中,OrionBench数据集被广泛用于设计自动化信息图表分析工具,例如数据可视化生成系统和智能文档处理平台。通过利用该数据集训练的模型,企业能够高效提取图表中的关键信息,提升数据分析和决策支持的效率。
数据集最近研究
最新研究方向
在信息可视化领域,图表与人类可识别对象(HRO)的检测技术正逐渐成为计算机视觉研究的热点。OrionBench作为该领域的基准数据集,近期研究聚焦于多模态检测模型的性能评估与优化,特别是针对零样本提示、少样本微调等前沿方法的探索。通过集成Faster-RCNN、YOLOv3、RTMDet和Co-DETR等主流检测框架,该数据集为模型在复杂信息图表中的泛化能力提供了标准化测试平台。值得注意的是,基于InternImage架构的联合开发模型进一步推动了检测精度与效率的边界,相关成果已应用于数据新闻生成和智能报告分析等实际场景,为跨模态理解技术的工业化落地提供了重要参考。
以上内容由遇见数据集搜集并总结生成


