CoNLL-NERC-es
收藏Hugging Face2026-02-06 更新2026-02-07 收录
下载链接:
https://huggingface.co/datasets/IIC/CoNLL-NERC-es
下载链接
链接失效反馈官方服务:
资源简介:
CoNLL-NERC-es 是 CoNLL-2002 共享任务的西班牙语数据集,专注于命名实体识别和分类任务。该数据集包含四种类型的命名实体标注(人物、地点、组织和其他杂项实体),采用标准的 BIO 格式。数据集由西班牙 EFE 新闻社 2000 年 5 月的新闻电讯文章构成,包含 8,324 个训练句子(19,400 个命名实体)、1,916 个开发句子(4,568 个命名实体)和 1,518 个测试句子(3,644 个命名实体)。数据标注由加泰罗尼亚理工大学 TALP 研究中心和巴塞罗那大学语言与计算中心完成,得到了欧盟 NAMIC 项目的资助。该数据集适用于西班牙语自然语言处理任务,特别是命名实体识别领域的研究和应用。
提供机构:
Instituto de Ingeniería del Conocimiento
创建时间:
2026-02-06
原始信息汇总
CoNLL-NERC-es 数据集概述
数据集基本信息
- 数据集名称:CoNLL-NERC-es
- 来源页面:https://huggingface.co/datasets/IIC/CoNLL-NERC-es
- 原始网站:https://www.cs.upc.edu/~nlp/tools/nerc/nerc.html
- 联系人:Xavier Carreras (carreras@lsi.upc.es)
- 语言:西班牙语 (es-ES)
- 多语言性:单语
- 任务类别:词元分类
- 任务ID:词性标注
- 标注创建者:专家生成
- 语言创建者:发现
数据集摘要
CoNLL-NERC是CoNLL-2002共享任务的西班牙语数据集。该数据集使用标准的开始-内部-外部(BIO)格式标注了四种类型的命名实体:人物、地点、组织和其他杂项实体。语料库包含8,324个训练句子(19,400个命名实体)、1,916个开发句子(4,568个命名实体)和1,518个测试句子(3,644个命名实体)。该数据集被用作EvalEs西班牙语基准测试的一部分。
支持的任务
- 命名实体识别与分类
数据集结构
数据字段
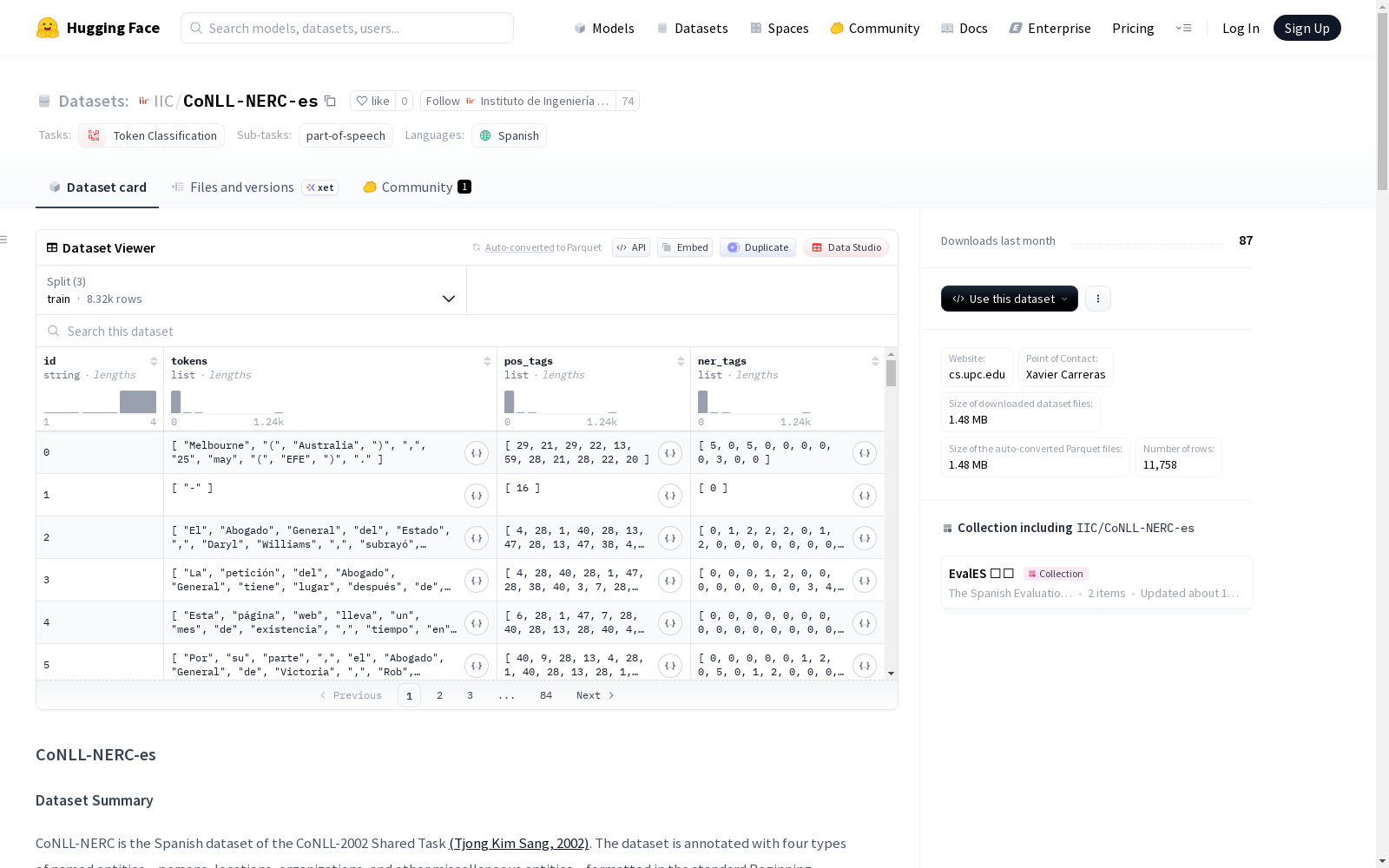
id:字符串类型tokens:字符串列表pos_tags:列表类型,包含60个词性标签类别(AO, AQ, CC, CS, DA, DE, DD, DI, DN, DP, DT, Faa, Fat, Fc, Fd, Fe, Fg, Fh, Fia, Fit, Fp, Fpa, Fpt, Fs, Ft, Fx, Fz, I, NC, NP, P0, PD, PI, PN, PP, PR, PT, PX, RG, RN, SP, VAI, VAM, VAN, VAP, VAS, VMG, VMI, VMM, VMN, VMP, VMS, VSG, VSI, VSM, VSN, VSP, VSS, Y, Z)ner_tags:列表类型,包含9个命名实体标签类别(O, B-PER, I-PER, B-ORG, I-ORG, B-LOC, I-LOC, B-MISC, I-MISC)
数据实例示例
每个文件有两列,第一列是单词形式或标点符号,第二列是对应的IOB标签。不同文件之间用空行分隔。
数据划分
- 训练集:8,324个样本,6,672,153字节
- 验证集:1,916个样本,1,333,764字节
- 测试集:1,518个样本,1,294,136字节
- 总数据集大小:9,300,053字节
- 下载大小:1,479,313字节
原始文件划分
- esp.train:273,037行
- esp.testa:54,837行(用作开发集)
- esp.testb:53,049行(用作测试集)
数据集创建
数据来源
数据来源于西班牙EFE新闻社提供的新闻电讯文章集,文章时间为2000年5月。
标注信息
标注由加泰罗尼亚理工大学(UPC)的TALP研究中心和巴塞罗那大学(UB)的语言与计算中心(CLiC)完成,由欧洲委员会通过NAMIC项目(IST-1999-12392)资助。
使用注意事项
社会影响
该数据集有助于西班牙语语言模型的发展。
引用信息
使用该语料库时必须引用以下论文: Erik F. Tjong Kim Sang. 2002. Introduction to the CoNLL-2002 Shared Task: Language-Independent Named Entity Recognition. In COLING-02: The 6th Conference on Natural Language Learning 2002 (CoNLL-2002).
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,西班牙语命名实体识别任务的发展离不开高质量标注资源的支撑。CoNLL-NERC-es数据集的构建源于CoNLL-2002共享任务,其语料来源于西班牙埃菲通讯社2000年5月的新闻电讯稿。由加泰罗尼亚理工大学TALP研究中心与巴塞罗那大学CLiC中心组成的专家团队,采用严谨的标注流程,对文本中的人物、地点、组织及其他杂类实体进行了系统标注,最终形成了包含训练集、验证集和测试集的完整语料库,为西班牙语信息抽取研究奠定了坚实基础。
特点
该数据集在西班牙语命名实体识别领域具有显著的代表性。其标注体系采用经典的BIO格式,涵盖了四类核心命名实体类型,并配备了精细的词性标注体系,包含60种词性标签。数据集规模适中,包含万余个句子与近三万个命名实体实例,数据分割科学合理,确保了模型训练与评估的有效性。作为EvalEs西班牙语基准测试的重要组成部分,该数据集为衡量语言模型在西班牙语实体识别任务上的性能提供了权威标准。
使用方法
对于研究人员而言,该数据集主要用于西班牙语命名实体识别模型的训练与评估。数据以标准的双列格式组织,便于直接加载与处理。使用者可通过HuggingFace平台便捷获取数据,并利用其预定义的数据分割进行模型开发。在应用过程中,需遵循数据集的引用规范,援引原始共享任务论文,以确保学术研究的严谨性与可追溯性。该数据集为探索西班牙语语言理解技术提供了关键实验平台。
背景与挑战
背景概述
CoNLL-NERC-es数据集源于2002年计算自然语言学习会议(CoNLL)的共享任务,由加泰罗尼亚理工大学TALP研究中心和巴塞罗那大学CLiC中心联合构建,并得到欧盟NAMIC项目的资助。该数据集专注于西班牙语命名实体识别任务,其语料源自西班牙埃菲通讯社2000年5月的新闻电讯稿,涵盖了人物、地点、组织及其他杂类实体等四类命名实体标注。作为西班牙语自然语言处理领域的基准资源之一,该数据集为后续研究提供了重要的评估基础,推动了西班牙语信息抽取技术的发展。
当前挑战
在命名实体识别领域,西班牙语文本面临实体边界模糊和类别歧义等挑战,例如复合实体与缩略语的识别难题。数据集构建过程中,专家标注者需处理新闻文本中多样的语言表达和领域特异性实体,确保标注一致性与准确性。此外,语料规模相对有限且集中于新闻领域,可能限制模型在其他文本类型上的泛化能力,这些因素共同构成了该数据集应用与扩展的核心挑战。
常用场景
经典使用场景
在自然语言处理领域,西班牙语命名实体识别任务长期面临高质量标注资源的稀缺。CoNLL-NERC-es数据集作为CoNLL-2002共享任务的核心语料,为研究者提供了标准化的评估基准。该数据集广泛应用于序列标注模型的训练与验证,特别是基于条件随机场、循环神经网络以及Transformer架构的命名实体识别系统开发。通过其精确标注的人名、地名、机构名等实体类别,该数据集成为衡量西班牙语信息抽取系统性能的黄金标准。
解决学术问题
该数据集有效解决了跨语言自然语言处理中西班牙语实体识别模型泛化能力不足的学术难题。通过提供大规模人工标注的新闻语料,它支撑了命名实体识别领域从传统机器学习到深度学习范式的演进研究。其标准化的BIO标注体系促进了序列标注算法的可比较性,为语言无关的实体识别方法提供了验证平台。该资源显著降低了西班牙语NLP研究的门槛,推动了多语言信息抽取技术的均衡发展。
衍生相关工作
该数据集催生了西班牙语自然语言处理领域的系列经典研究。早期工作如Carreras等人基于支持向量机的混合模型,首次在该数据集上实现了超过80%的F1分数。后续研究逐步引入条件随机场、双向LSTM-CRF等序列标注架构。近年来,以BETO为代表的西班牙语预训练语言模型均使用该数据集进行下游任务微调评估。这些衍生工作共同推动了IberLEF等西班牙语NLP评测会议的技术发展。
以上内容由遇见数据集搜集并总结生成


