KnoWoGen
收藏arXiv2024-09-06 更新2024-09-10 收录
下载链接:
https://purl.archive.org/knowogen/examples
下载链接
链接失效反馈官方服务:
资源简介:
KnoWoGen是由德国人工智能研究中心和凯撒斯劳滕-兰道大学计算机科学系开发的用于生成多代理知识工作数据集的框架。该数据集包含25封电子邮件和会议记录,旨在模拟真实的知识工作环境。数据集的创建过程涉及使用大型语言模型生成文档,并通过多代理系统进行任务分配和调度。KnoWoGen的应用领域主要集中在知识工作支持工具的评估和优化,旨在解决现有数据集缺乏多样性、背景信息和上下文的问题。
KnoWoGen is a framework for generating multi-agent knowledge work datasets, developed by the German Research Center for Artificial Intelligence and the Department of Computer Science, Kaiserslautern-Landau University. The datasets generated using this framework contain 25 emails and meeting minutes, designed to simulate real-world knowledge work environments. The dataset creation process involves utilizing Large Language Models (LLMs) to generate documents, as well as task assignment and scheduling via multi-agent systems. The primary application areas of KnoWoGen focus on the evaluation and optimization of knowledge work support tools, aiming to address the shortcomings of existing datasets, namely their lack of diversity, background information and contextual details.
提供机构:
德国人工智能研究中心(DFKI)和凯撒斯劳滕-兰道大学计算机科学系
创建时间:
2024-09-06
原始信息汇总
KnoWoGen – The Knowledge Work Dataset Generator
摘要
当前公开的知识工作数据集缺乏多样性、广泛的注释以及用户及其文档的上下文信息。这些问题阻碍了知识工作辅助系统的客观和可比较的数据驱动评估和优化。由于在现实环境中收集此类数据需要大量资源,并且需要数据审查,因此收集这样的数据集几乎是不可能的。为此,我们提出了一种可配置的多代理知识工作数据集生成器。该系统模拟代理之间的协作知识工作,生成大型语言模型生成的文档和伴随的数据跟踪。此外,生成器捕获其配置或模拟过程中创建的所有背景信息,并将其存储在知识图中。最终,生成的数据集可以在没有隐私或保密问题的情况下使用和共享。
作者
- Desiree Heim
- Christian Jilek
- Adrian Ulges
- Andreas Dengel
详细信息
(即将推出)
示例(提示和生成的文档)
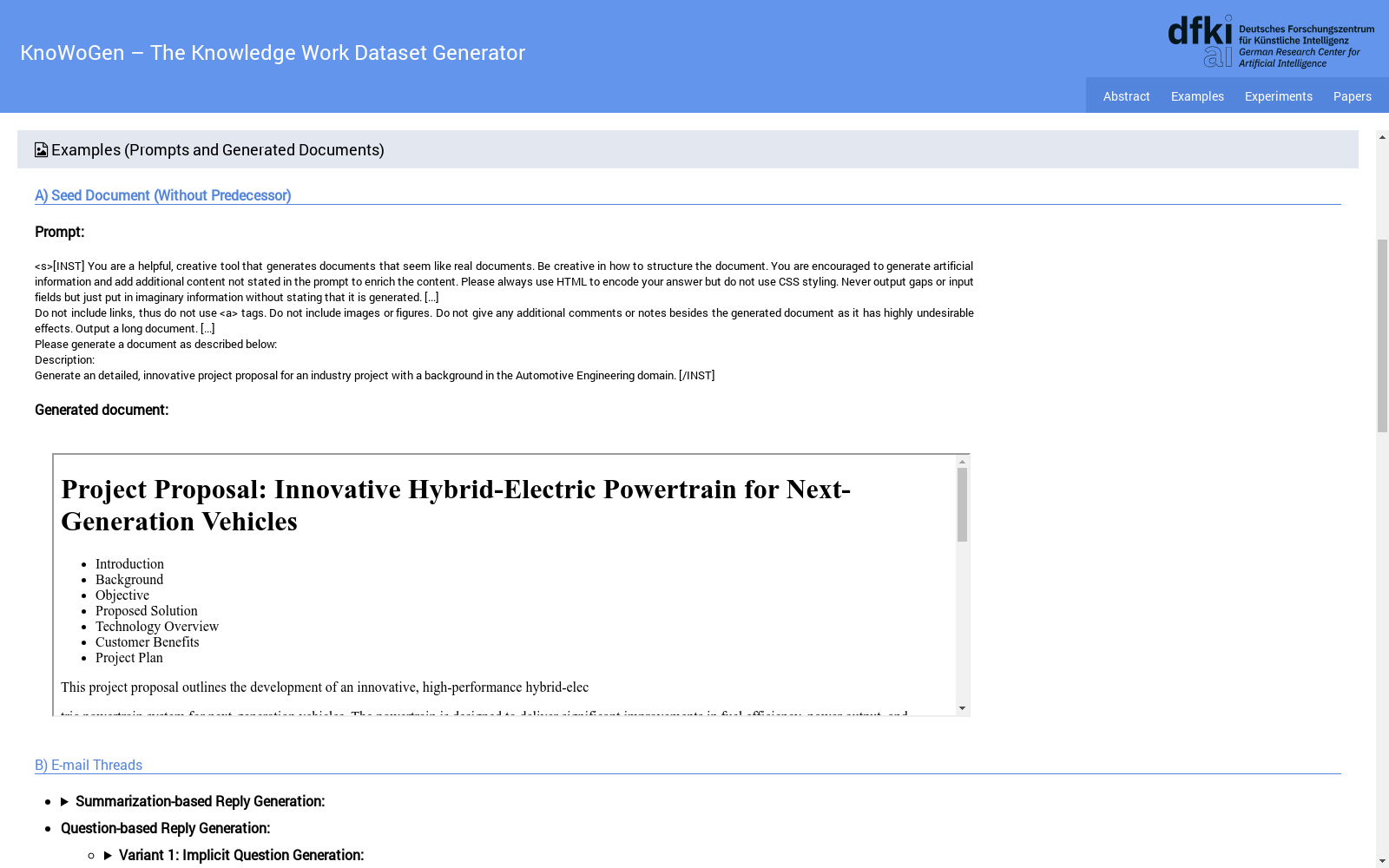
A) 种子文档(无前驱)
提示:
<s>[INST] 你是一个有帮助的、创造性的工具,生成看起来像真实文档的文档。在文档结构上要有创意。鼓励生成人工信息,并添加未在提示中声明的额外内容以丰富内容。请始终使用HTML编码你的答案,但不要使用CSS样式。永远不要输出空白或输入字段,只需放入虚构的信息,而不声明它是生成的。[...] 不要包含链接,因此不要使用<a>标签。不要包含图像或图表。不要给出任何额外的评论或注释,因为这会产生非常不利的影响。输出一个长文档。[...] 请按照以下描述生成文档: 描述: 生成一个详细的、创新的项目提案,背景为汽车工程领域的行业项目。 [/INST]
生成的文档:
(嵌入的HTML文档)
实验
实验1:比较真实文档和生成文档的真实性
在这个实验中,我们让参与者在7点李克特量表上对真实文档和生成文档的真实性进行评分。评分越高,参与者认为文档越真实。
以下图表展示了真实文档和生成文档的评分分布: (图表图像)
论文
(即将推出)
搜集汇总
数据集介绍
构建方式
KnoWoGen是一种可定制的知识工作数据集生成器,通过模拟多代理人的协作知识工作来构建数据集。用户需配置KnoWoGen以创建适合其评估需求的数据集。基于配置,KnoWoGen设置模拟环境,为代理人分配任务,并通过提示大型语言模型(LLM)生成文档。所有背景信息和生成的文档都存储在知识图中,以保留所有上下文相关信息。
特点
KnoWoGen生成的数据集具有多样性、可定制性、上下文丰富性等特点。它解决了现有数据集存在的完整性、背景信息缺失、泛化能力有限等问题。数据集通过模拟真实的知识工作流程,生成包含文档和伴随数据痕迹的知识工作数据集。
使用方法
使用KnoWoGen时,用户首先需要配置模拟环境,包括指定代理人、公司、部门和领域。然后,用户定义任务,任务由一系列具有逻辑或内容依赖性的动作组成。根据任务配置,KnoWoGen会提示LLM生成文档,并将所有信息和生成的文档存储在知识图中。生成的数据集可用于评估和优化知识工作辅助工具。
背景与挑战
背景概述
KnoWoGen数据集是由德国研究中心(DFKI)的研究人员提出的一种知识工作数据集生成器。该数据集旨在解决现有数据集存在的不足,如不完整、缺乏背景信息、适用性有限等问题。KnoWoGen通过模拟多个知识工作者协作完成任务的方式,生成包含文档和伴随数据痕迹的知识工作数据集。其核心研究问题是创建一个能够生成真实、多样化的知识工作文档的生成器,以供知识工作支持工具的评价和优化。该数据集的创建时间为2024年,主要研究人员来自DFKI和凯撒斯劳滕大学计算机科学系。
当前挑战
KnoWoGen面临的挑战主要包括:1)生成具有多样性和真实性的文档,确保所生成的文档能够反映知识工作的实际情况;2)构建过程中,需要处理数据不完整、缺乏背景信息等问题;3)所生成的数据集需要能够适用于不同的评价需求,具有一定的适应性和通用性;4)在保证数据质量的同时,还需要考虑数据集的隐私和保密性问题。
常用场景
经典使用场景
KnoWoGen作为一个知识工作数据集生成器,其经典使用场景在于模拟多智能体之间的协作知识工作,生成包含文档和伴随数据痕迹的知识工作数据集。这些数据集可用于评估和优化知识工作辅助工具,如任务预测器、信息提取、搜索或推荐系统。
衍生相关工作
基于KnoWoGen的生成方法和理念,衍生出了一系列相关工作。例如,研究者可以进一步探索不同类型文档的生成、智能体行为的建模,以及如何利用生成文档来影响模拟过程等方面的工作。
数据集最近研究
最新研究方向
KnoWoGen数据集最新研究方向关注于利用大型语言模型生成真实的知识工作文档,以及通过多智能体模拟来创建多样化的知识工作数据集。该研究旨在解决现有数据集存在的多样性不足、背景信息缺乏、泛化能力有限等问题。KnoWoGen通过模拟多智能体之间的协作和任务执行,生成包含文档和伴随数据痕迹的知识工作数据集,并通过知识图谱保存所有背景信息。最新研究结果显示,KnoWoGen生成的文档在真实性评估中取得了 promising的成绩,但仍有一些内容相关的 issues 需要解决,以提高文档的真实性。
相关研究论文
- 1Using Large Language Models to Generate Authentic Multi-agent Knowledge Work Datasets德国人工智能研究中心(DFKI)和凯撒斯劳滕-兰道大学计算机科学系 · 2024年
以上内容由遇见数据集搜集并总结生成


