有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
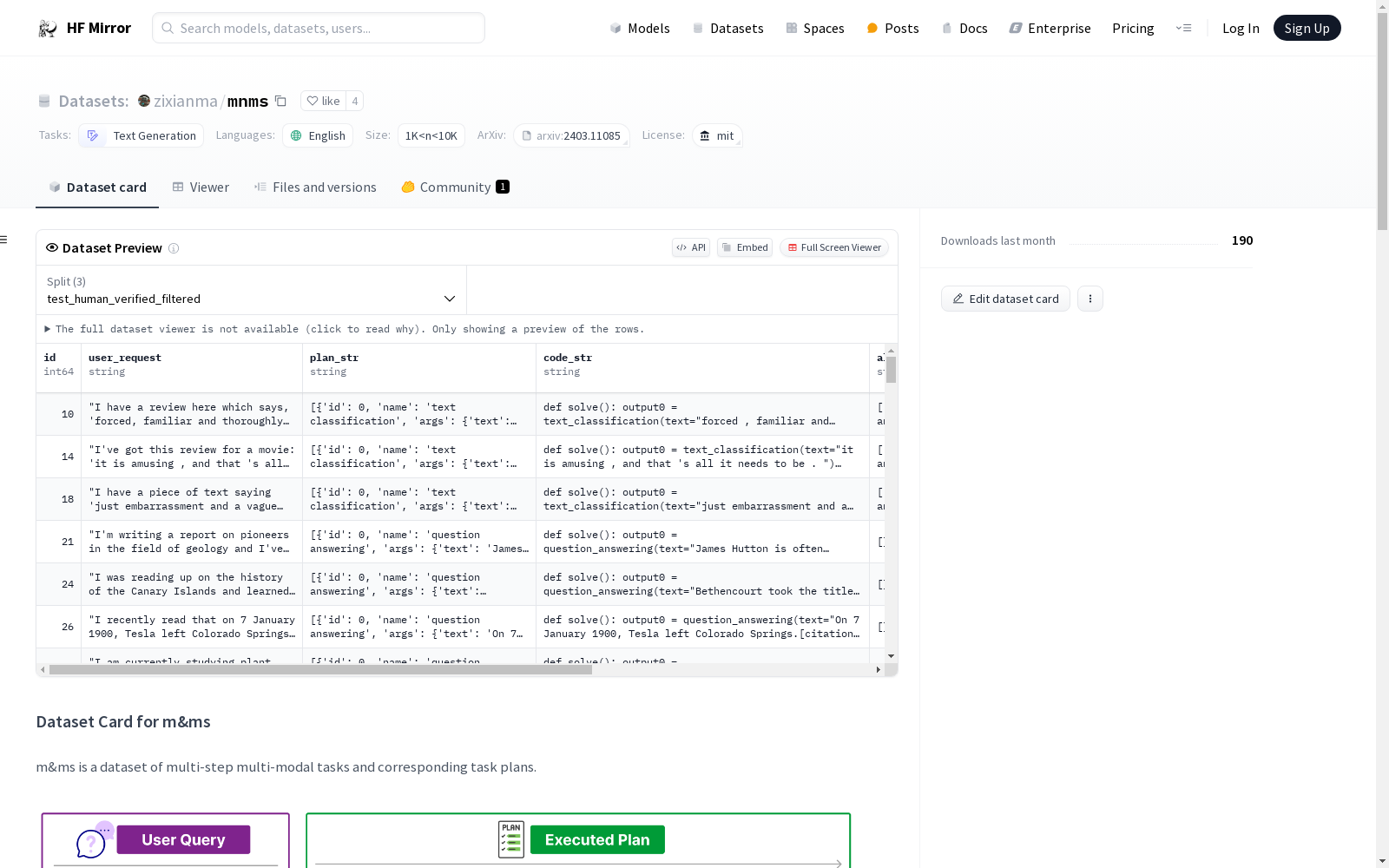
数据集名称: m&ms
数据集描述: m&ms是一个包含多步骤多模态任务及其对应任务计划的数据集。该数据集包含超过4,000个多步骤多模态任务,涉及33种工具,包括13种多模态模型、9个公共API和11个图像处理模块。此外,还提供了一个高质量的1,565个人工验证的任务计划和882个人工验证、过滤并可正确执行的计划。
数据集用途: 该数据集旨在评估大型语言模型(LLM)代理在多步骤多模态任务中使用工具的能力。
数据集文件:
test_human_verified_filtered.jsontest_human_verified.jsontest_raw.json数据集语言: 英语 (en)
数据集规模: 1K<n<10K
许可证: MIT
任务类别: 文本生成
数据集来源:
数据集生成: 数据输入来自多个现有数据集,包括ImageNet, sst2, SQUAD, C4, CNN daily news, COCO, COCO-Text v2.0, GQA, Visual Genome, MagicBrush, 和librispeech。
BibTeX:
@misc{ma2024mms, title={m&ms: A Benchmark to Evaluate Tool-Use for multi-step multi-modal Tasks}, author={Zixian Ma and Weikai Huang and Jieyu Zhang and Tanmay Gupta and Ranjay Krishna}, year={2024}, eprint={2403.11085}, archivePrefix={arXiv}, primaryClass={cs.CV} }
MultiTalk
MultiTalk数据集是由韩国科学技术院创建,包含超过420小时的2D视频,涵盖20种不同语言,旨在解决多语言环境下3D说话头生成的问题。该数据集通过自动化管道从YouTube收集,每段视频都配有语言标签和伪转录,部分视频还包含伪3D网格顶点。数据集的创建过程包括视频收集、主动说话者验证和正面人脸验证,确保数据质量。MultiTalk数据集的应用领域主要集中在提升多语言3D说话头生成的准确性和表现力,通过引入语言特定风格嵌入,使模型能够捕捉每种语言独特的嘴部运动。
arXiv 收录
UniMed
UniMed是一个大规模、开源的多模态医学数据集,包含超过530万张图像-文本对,涵盖六种不同的医学成像模态:X射线、CT、MRI、超声、病理学和眼底。该数据集通过利用大型语言模型(LLMs)将特定模态的分类数据集转换为图像-文本格式,并结合现有的医学领域的图像-文本数据,以促进可扩展的视觉语言模型(VLM)预训练。
github 收录
CosyVoice 2
CosyVoice 2是由阿里巴巴集团开发的多语言语音合成数据集,旨在通过大规模多语言数据集训练,实现高质量的流式语音合成。数据集通过有限标量量化技术改进语音令牌的利用率,并结合预训练的大型语言模型作为骨干,支持流式和非流式合成。数据集的创建过程包括文本令牌化、监督语义语音令牌化、统一文本-语音语言模型和块感知流匹配模型等步骤。该数据集主要应用于语音合成领域,旨在解决高延迟和低自然度的问题,提供接近人类水平的语音合成质量。
arXiv 收录
Titanic Dataset
Titanic Data Analysis: A Journey into Passenger Profiles and Survival Dynamics
kaggle 收录
中国1km分辨率逐月NDVI数据集(2001-2023年)
中国1km分辨率逐月NDVI数据集(2001-2023年)根据MODIS MOD13A2数据进行月度最大值合成、镶嵌和裁剪后制作而成,包含多个TIF文件,每个TIF文件对应该月最大值NDVI数据,文件以时间命名。数据值域改为-0.2~1,不再需要除以一万,另外范围扩大到中国及周边地区,可以自行裁剪。数据分为两个文件夹,MVC文件夹中为MOD13A2 NDVI逐月最大值合成结果,mod1k_SGfilter为MVC中数据S-G滤波后的结果。
国家地球系统科学数据中心 收录