zixianma/mnms
收藏Hugging Face2024-07-07 更新2024-04-19 收录
下载链接:
https://hf-mirror.com/datasets/zixianma/mnms
下载链接
链接失效反馈官方服务:
资源简介:
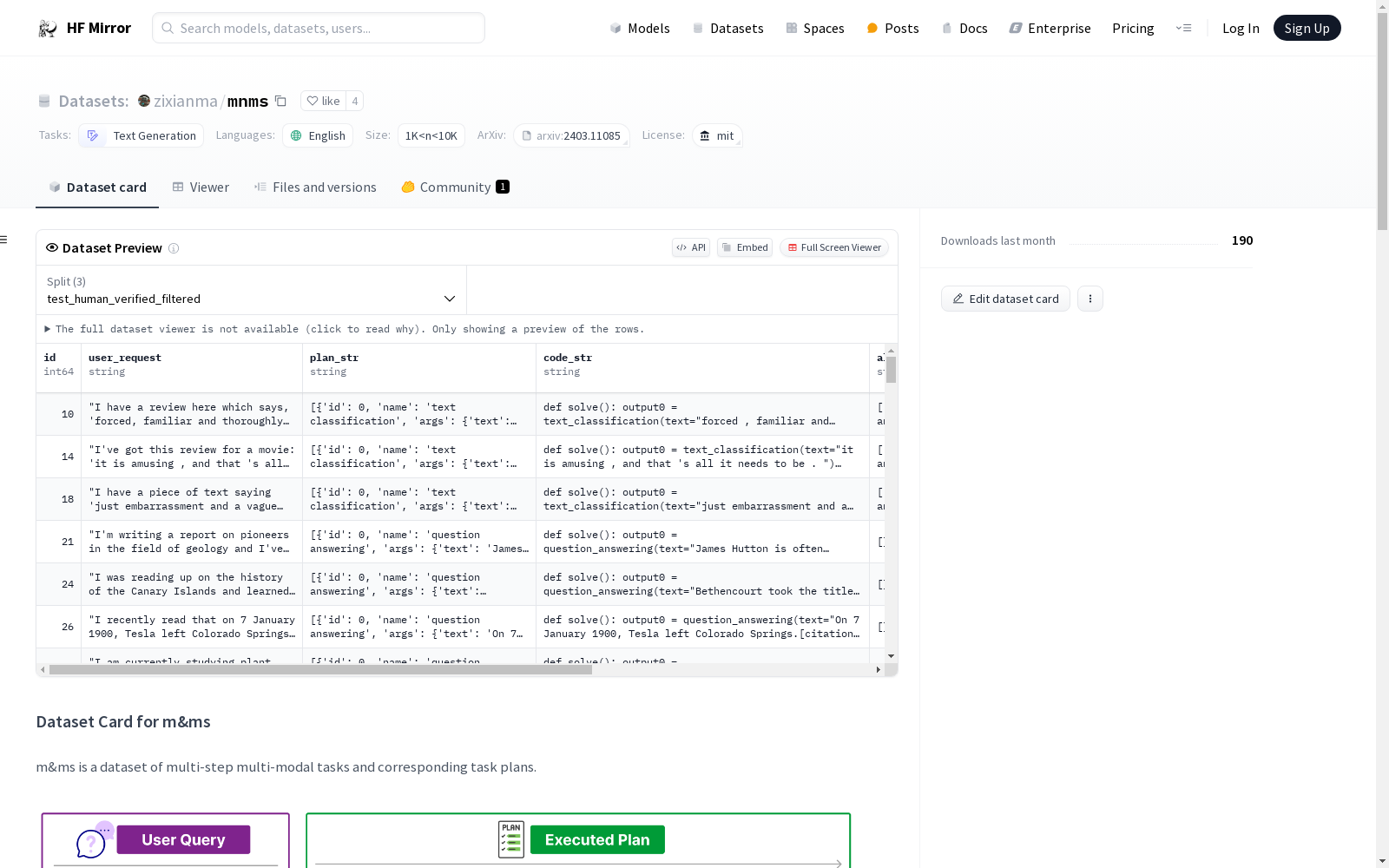
m&ms数据集包含4,000多个多步多模态任务,涉及33种工具,包括13种多模态模型、9种公共API和11种图像处理模块。对于每个任务查询,数据集提供了使用这些工具自动生成的任务计划。此外,数据集还提供了一个高质量的子集,包含1,565个人工验证的任务计划和882个人工验证、过滤且可正确执行的计划。该数据集主要用于评估大型语言模型(LLM)代理在多步多模态任务中的工具使用能力。
The M&Ms Dataset contains over 4,000 multi-step multimodal tasks involving 33 tools, including 13 multimodal models, 9 public APIs, and 11 image processing modules. For each task query, the dataset provides automatically generated task plans using these tools. Additionally, the dataset offers a high-quality subset consisting of 1,565 manually verified task plans and 882 plans that have been manually verified, filtered, and proven to execute correctly. This dataset is primarily used to evaluate the tool utilization capabilities of large language model (LLM) agents in multi-step multimodal tasks.
提供机构:
zixianma
原始信息汇总
数据集概述
数据集名称: m&ms
数据集描述: m&ms是一个包含多步骤多模态任务及其对应任务计划的数据集。该数据集包含超过4,000个多步骤多模态任务,涉及33种工具,包括13种多模态模型、9个公共API和11个图像处理模块。此外,还提供了一个高质量的1,565个人工验证的任务计划和882个人工验证、过滤并可正确执行的计划。
数据集用途: 该数据集旨在评估大型语言模型(LLM)代理在多步骤多模态任务中使用工具的能力。
数据集文件:
test_human_verified_filtered.jsontest_human_verified.jsontest_raw.json
数据集语言: 英语 (en)
数据集规模: 1K<n<10K
许可证: MIT
数据集详细信息
任务类别: 文本生成
数据集来源:
数据集生成: 数据输入来自多个现有数据集,包括ImageNet, sst2, SQUAD, C4, CNN daily news, COCO, COCO-Text v2.0, GQA, Visual Genome, MagicBrush, 和librispeech。
数据集限制
- 用户请求可能存在偏差,因为它们是由GPT-4生成的,并不一定代表真实世界的用户请求。
- 任务计划都是顺序的,需要1-3个工具来解决。
引用信息
BibTeX:
@misc{ma2024mms, title={m&ms: A Benchmark to Evaluate Tool-Use for multi-step multi-modal Tasks}, author={Zixian Ma and Weikai Huang and Jieyu Zhang and Tanmay Gupta and Ranjay Krishna}, year={2024}, eprint={2403.11085}, archivePrefix={arXiv}, primaryClass={cs.CV} }
搜集汇总
数据集介绍
构建方式
m&ms数据集的构建基于多步骤多模态任务的需求,涵盖了33种工具,包括13种多模态模型、9种公共API和11种图像处理模块。每个任务查询都配备了自动生成的计划,这些计划是基于实际工具集的。此外,数据集还包含一个高质量子集,其中包括1,565个经过人工验证的任务计划和882个经过人工验证、过滤且可正确执行的计划。数据输入来源于多个现有数据集,如ImageNet、SQUAD等,确保了数据的多样性和广泛性。
特点
m&ms数据集的显著特点在于其多步骤多模态任务的复杂性和多样性。该数据集不仅包含了多种工具的使用,还特别强调了任务计划的生成和验证过程。通过提供自动生成的计划和人工验证的高质量子集,m&ms数据集为评估大型语言模型(LLM)在工具使用能力方面的表现提供了坚实的基础。此外,数据集的构建过程确保了任务的多样性和实际应用的相关性。
使用方法
m&ms数据集主要用于评估大型语言模型(LLM)在多步骤多模态任务中的工具使用能力。使用者可以通过获取LLM代理对用户请求的计划预测,并将其与数据集中的标签计划或代码进行对比,从而进行评估。数据集的直接使用场景包括但不限于模型性能测试和工具使用策略的验证。需要注意的是,该数据集不适用于模型训练,仅用于评估和验证目的。
背景与挑战
背景概述
m&ms数据集由Zixian Ma等人于2024年创建,隶属于RAIVNLab机构。该数据集专注于多步骤多模态任务及其相应的任务计划,旨在评估大型语言模型(LLM)在工具使用能力方面的表现。m&ms数据集包含了超过4000个涉及33种工具的多步骤多模态任务,其中包括13种多模态模型、9个公共API和11个图像处理模块。这些任务的查询均配备了自动生成的计划,并进一步提供了1565个经过人工验证的高质量任务计划和882个经过验证、过滤且可正确执行的计划。m&ms数据集的推出,为多模态任务处理领域提供了一个重要的基准,推动了LLM在复杂任务规划与执行方面的研究进展。
当前挑战
m&ms数据集在构建过程中面临多项挑战。首先,用户请求的生成依赖于GPT-4,这可能导致请求内容与真实世界用户需求存在偏差。其次,所有任务计划均为顺序执行,且每个任务需使用1-3个工具,这种设计限制了任务的多样性和复杂性。此外,数据集的构建涉及从多个现有数据集(如ImageNet、COCO等)中抽取数据,这要求对数据进行严格的筛选和处理,以确保数据的质量和一致性。最后,尽管数据集提供了高质量的人工验证计划,但如何确保这些计划在不同模型和应用场景中的通用性和有效性,仍是一个待解决的问题。
常用场景
经典使用场景
在自然语言处理领域,m&ms数据集的经典使用场景主要集中在评估大型语言模型(LLM)在多步骤多模态任务中的工具使用能力。通过该数据集,研究者可以生成针对用户请求的计划预测,并将其与数据集中提供的标签计划或代码进行对比评估,从而量化模型在复杂任务中的表现。
解决学术问题
m&ms数据集解决了在多模态任务中评估模型工具使用能力的关键学术问题。传统方法往往难以全面评估模型在复杂任务中的表现,而该数据集通过提供高质量的人工验证任务计划,填补了这一空白。其意义在于推动了多模态任务处理技术的发展,并为未来研究提供了基准。
衍生相关工作
基于m&ms数据集,研究者们开展了一系列相关工作,包括改进多模态任务处理算法、开发新的评估指标以及构建更复杂的任务模拟环境。这些工作不仅深化了对多模态任务处理的理解,还为实际应用提供了技术支持,推动了该领域的技术进步。
以上内容由遇见数据集搜集并总结生成


