harvard-lil/cold-cases
收藏Hugging Face2024-03-26 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/harvard-lil/cold-cases
下载链接
链接失效反馈官方服务:
资源简介:
COLD Cases数据集包含830万美国法律决策,这些决策包含文本和元数据,并以压缩的Parquet文件格式存储。该数据集旨在支持开放法律运动,如Pile of Law和LegalBench项目。数据集由CourtListener收集和发布,并由哈佛图书馆创新实验室重新格式化,以便每个法律决策的语义信息都被编码在一个记录中,去除了多余的数据。数据集由哈佛图书馆创新实验室与自由法律项目合作准备。
The COLD Cases dataset contains 8.3 million US legal decisions, which include both text and metadata, and are stored in compressed Parquet file format. This dataset is designed to support open law initiatives such as the Pile of Law and LegalBench projects. Collected and published by CourtListener, the dataset was reformatted by the Harvard Library Innovation Lab: semantic information of each legal decision is encoded into a single record with redundant data removed. The dataset was prepared in collaboration between the Harvard Library Innovation Lab and the Free Law Project.
提供机构:
harvard-lil
原始信息汇总
Collaborative Open Legal Data (COLD) - Cases
数据集概述
COLD Cases 是一个包含 830 万份美国法律裁决的数据集,包含文本和元数据,格式为压缩的 Parquet 文件。
数据格式
数据集采用 Apache Parquet 格式,这是一种二进制格式,便于快速过滤和检索数据,因为它按列排列数据,这意味着不需要读取满足特定查询或工作流程的不必要列。
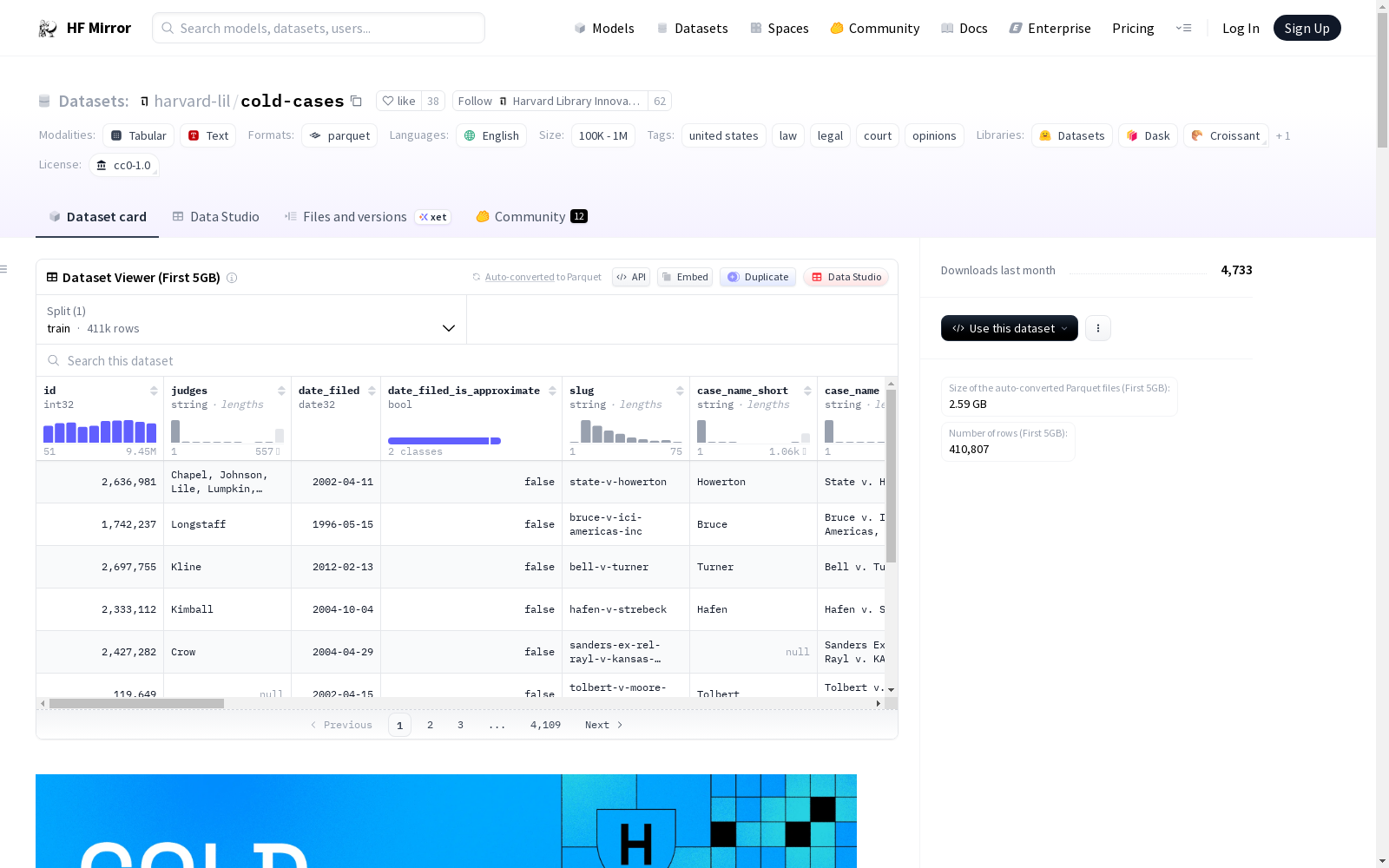
数据字典
以下是数据集中部分字段的说明:
| 字段名 | 描述 |
|---|---|
judges |
审理案件的法官姓名,从文本中提取。 |
date_filed |
案件提交日期,格式为 ISO 日期格式。 |
date_filed_is_approximate |
布尔值,表示 date_filed 是否精确到天。 |
slug |
案件的短小、人类可读的唯一字符串昵称。 |
case_name_short |
案件的简称。 |
case_name |
案件的全称。 |
case_name_full |
案件的完整正式名称。 |
attorneys |
案件中辩护律师的姓名,从文本中提取。 |
nature_of_suit |
自由文本表示的诉讼类型,如民事、侵权等。 |
syllabus |
如果由裁决报告者提供,则为裁决中涉及问题的摘要。 |
headnotes |
案件的文本性要点。 |
summary |
案件的文本摘要。 |
disposition |
法院在最终裁决中处理案件的方式。 |
history |
关于此案件在后续裁决中发生的情况的文本信息。 |
other_dates |
与案件相关的其他日期的自由文本。 |
cross_reference |
相关案件的引用。 |
citation_count |
引用此案件的案件数量。 |
precedential_status |
限制为 "Published", "Unknown", "Errata", "Unpublished", "Relating-to", "Separate", "In-chambers" 等值。 |
citations |
引用此案件的案件。 |
court_short_name |
审理案件的法院简称。 |
court_full_name |
审理案件的法院全称。 |
court_jurisdiction |
审理案件的法院类型的代码。参见:court_jurisdiction 字段值 |
opinions |
子记录数组。 |
opinions.author_str |
个别意见的作者姓名。 |
opinions.per_curiam |
布尔值,表示意见是由整个法院还是单个法官发表的。 |
opinions.type |
其中之一:"010combined", "015unamimous", "020lead", "025plurality", "030concurrence", "035concurrenceinpart", "040dissent", "050addendum", "060remittitur", "070rehearing", "080onthemerits", "090onmotiontostrike"。 |
opinions.opinion_text |
意见的实际全文。 |
opinions.ocr |
意见是通过光学字符识别捕获的还是数字文本。 |
court_type 字段值
| 值 | 描述 |
|---|---|
| F | 联邦上诉 |
| FD | 联邦地区 |
| FB | 联邦破产 |
| FBP | 联邦破产小组 |
| FS | 联邦特别 |
| S | 州最高 |
| SA | 州上诉 |
| ST | 州审判 |
| SS | 州特别 |
| TRS | 部落最高 |
| TRA | 部落上诉 |
| TRT | 部落审判 |
| TRX | 部落特别 |
| TS | 领土最高 |
| TA | 领土上诉 |
| TT | 领土审判 |
| TSP | 领土特别 |
| SAG | 州检察长 |
| MA | 军事上诉 |
| MT | 军事审判 |
| C | 委员会 |
| I | 国际 |
| T | 测试 |
使用注意事项
在使用此数据时,请注意以下事项:
- 此数据集中的所有文档都是公共信息,由美国法院发布以向公众通报法律情况。您有权访问它们。
- 尽管如此,公共法院裁决经常包含关于个人的不真实陈述。法院裁决通常包含有争议的声明,或基于法律技术上为真的虚假声明,或有声明被视为真但后来被发现为假。法律裁决旨在向您通报法律——它们不是为了向您通报个人情况而设计的,也不应被用作信用数据库、犯罪记录数据库、新闻文章或其他旨在提供事实个人信息的来源。应用程序应仔细考虑使用此数据是否会通知法律,或误导个人情况。
- 法院裁决不是法律的最新声明。每个裁决都提供了裁决时法官对法律应用于所述事实的最佳理解。使用此数据生成关于法律的声明需要整合大量上下文——通常由律师提供的技能——而不是简单的数据检索。
为了减轻隐私风险,我们已经过滤掉了 CourtListener 屏蔽或取消索引的案件。需要访问未经过滤的完整数据集的研究人员可以重新运行我们的管道在 CourtListener 的原始数据上。
搜集汇总
数据集介绍
构建方式
在法学信息数字化浪潮中,COLD Cases数据集通过系统化整合与重构,构建了包含830万份美国法律判决的庞大语料库。该数据集源自CourtListener平台收集的公开判例法数据,经由哈佛图书馆创新实验室设计的开源处理流程,将每份判决的语义信息——包括多数意见与异议意见的文本、作者、案件摘要及核心元数据——编码为单一结构化记录,并剔除了冗余信息。这一流程采用Apache Parquet列式存储格式,优化了数据查询与读取效率,为下游法律自然语言处理任务提供了标准化、高质量的数据基础。
使用方法
研究者可通过Hugging Face Datasets库直接加载或流式读取该数据集,无需本地存储全部文件。利用Parquet格式的列式存储特性,可高效筛选特定法院、时间范围或判决类型的子集。数据适用于法律文本挖掘、判例引用网络分析、司法推理建模等任务,但需注意判决内容可能包含未经核实的个人陈述或已过时的法律观点,因此建议结合专业法律知识进行语境化解读,避免误导性应用。
背景与挑战
背景概述
在法学与计算社会科学交叉领域,大规模法律文本数据集的构建对于推动法律智能化研究至关重要。哈佛大学图书馆创新实验室与自由法律项目合作,于近年推出了COLD Cases数据集,该数据集汇集了830万份美国司法判决,涵盖联邦与州各级法院的判例文本及元数据。该数据集旨在支持开放法律运动,为法律自然语言处理与机器学习项目提供标准化、高质量的数据基础,其核心研究问题聚焦于如何从海量判例中提取结构化信息以深化对法律推理与司法决策的理解,对法律人工智能、司法透明度及比较法研究均产生了深远影响。
当前挑战
COLD Cases数据集致力于解决法律文本理解中的复杂挑战,包括判例分类、法律推理建模及司法趋势预测等任务,这些任务需处理法律语言特有的模糊性、上下文依赖性及历时演变性。在构建过程中,数据集面临多重挑战:其一,原始数据源自多元公共渠道,需通过爬虫技术进行聚合与清洗,确保数据的一致性与完整性;其二,法律文本包含大量专业术语、引用结构与非结构化信息,要求精细的语义编码以区分判决意见、法官陈述与案件摘要等要素;其三,隐私与伦理考量要求过滤敏感案例,同时保持数据的法律代表性,这增加了数据预处理的复杂性。
常用场景
经典使用场景
在法学与计算社会科学交叉领域,COLD Cases数据集为法律文本挖掘提供了关键资源。该数据集收录了830万份美国司法判决,涵盖联邦与州级法院的多数意见、异议意见及案件元数据,其结构化格式便于大规模自然语言处理分析。经典应用场景包括法律先例检索系统的构建,研究者利用文本相似度算法,从海量判例中自动识别与特定法律问题相关的历史判决,从而辅助法律从业者高效梳理判例脉络。
解决学术问题
该数据集有效应对了法律人工智能领域长期存在的标注数据稀缺问题。通过提供标准化、机器可读的判例文本,它支撑了法律推理建模、判决预测等核心研究任务。学者们可基于此探究司法决策模式,例如分析法官投票倾向与案件类型间的关联,或检验法律原则在历史中的演变轨迹。这些工作深化了对司法系统运作机制的理解,推动了可解释性法律AI模型的发展。
实际应用
在法律科技产业中,COLD Cases数据集已成为智能法律工具开发的基础设施。律师事务所利用其训练合同审查引擎,自动识别条款中的潜在风险点;法律科技公司则构建案例法分析平台,为律师提供实时判例引用网络可视化服务。此外,该数据集支持公益性司法接入项目,例如开发简化版法律信息检索系统,帮助公众理解复杂法律程序,促进司法透明度与可及性。
数据集最近研究
最新研究方向
在法学与人工智能交叉领域,COLD Cases数据集作为大规模美国法律判决文本资源,正推动法律智能研究的前沿探索。其整合了830万份法律决策的文本与元数据,为自然语言处理模型提供了结构化、高质量的案例表示,支撑了如法律推理自动化和判例预测等热点方向。当前研究聚焦于利用该数据集训练法律领域专用大语言模型,以提升对复杂法律文本的语义理解能力,同时结合元数据字段如法官意见类型和先例状态,探索司法行为分析与法律趋势挖掘。这些进展不仅促进了开源法律运动的发展,也为司法透明度与法律知识普及提供了技术基础,在确保数据使用伦理的前提下,助力构建更高效、公正的法律智能系统。
以上内容由遇见数据集搜集并总结生成


